ElasticSearch 分布式集群
公号:码农充电站pro
主页:https://codeshellme.github.io
1,ES 的分布式架构
ES 是一个分布式的集群,具有高可用性和可扩展性:
- 高可用性指的是:当某些节点意外宕机或者数据丢失的时候,不影响整个集群的使用。
- 可扩展性指的是:当业务数据量增加的时候,可以增加节点的数量,从而增强整个集群的能力。
ES 集群
ES 集群中可以有一个或多个节点,ES 通过集群名字来区分不同的集群,集群名可以通过 cluster.name 进行设置,默认为 "elasticsearch"。
2,ES 的节点类型
ES 的一个节点就是一个 Java 进程,所以一台机器可以运行一个或多个节点,生产环境建议一台机器只运行一个节点。
每个节点启动之后,都会分配一个 UID,并保存在 data 目录下。
每个节点都有节点名字,节点名可通过 node.name 设置。
2.1,Master 节点
Master 节点的职责:
- 处理客户端的请求。
- 决定分片被分配到哪个节点。
- 负责索引的创建于删除。
- 维护集群状态。
- 等。
集群的状态包括:
- 所有的节点信息
- 所有的索引及其 Mapping 和 Setting 信息
- 分片的路由信息
所有的节点有保存了集群的状态信息,但只有主节点能够修改集群状态。
2.2,Master-eligible 节点
在 ES 集群中,只有 Master-eligible 节点可以被选举为 Master 节点。
每个节点启动后默认就是 Master-eligible 节点,可以通过设置 node.master 为 false 来禁止成为 Master-eligible 节点。
默认情况下,集群中的第一个节点启动后,会将自己选举为 Master 节点。
集群中的每个节点都保存了集群的状态,但只有 Master 节点能够修改集群的状态信息。
2.3,Data 与 Coordinating 节点
用于保存 ES 数据的节点,就是 Data 节点,它对数据扩展起到了至关重要的作用。
Coordinating 节点叫做协调节点,它负责接收 Client 的请求,将请求分发到合适的节点,并最终汇总结果返回给 Client。
在 ES 中,所有的节点都是 Coordinating 节点。
2.4,Ingest 节点
Ingest 节点用于对数据预处理,通过添加一些 processors 来完成特定的处理。
Ingest 节点是在 ES 5.0 后引入的一种节点类型,可以达到一定的 Logstash 的功能。
默认情况下,所有的节点都是 Ingest 节点。
2.5,配置节点类型
理论上,一个节点可以扮演过多个角色,但生产环境中,建议设置单一角色。
节点的类型可以通过下面参数进行配置:
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| Master-eligible | node.master | true |
| Data Node | node.data | true |
| Ingest Node | node.ingest | true |
| Coordinating Node | 无 | 设置上面 3 个都为 false |
3,集群的健康状态
我们可以通过下面的 API 来查看整个集群的健康状态:
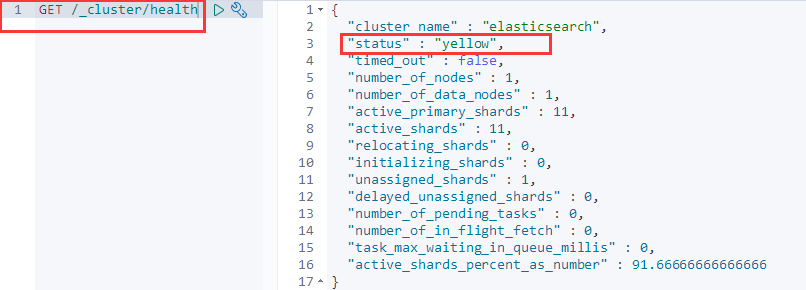
集群有 3 种级别的健康状态:
green:所有的主分片与副本分片都正常。yellow:所有的主分片都正常,某些副本分片不正常。red:部分主分片不正常。
我们也可以通过 Kibana 中的索引管理,来查看每个索引的健康状态:
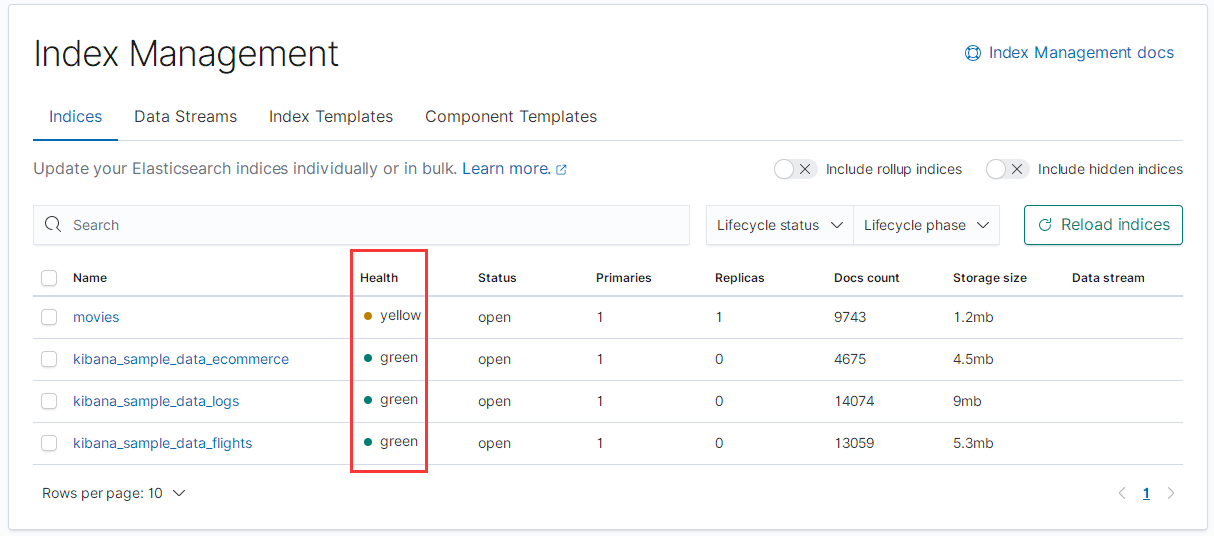
索引的状态级别与集群的状态级别一致。
4,脑裂问题
脑裂问题是分布式系统中的经典问题。
脑裂问题指的是,当出现网络故障时,一些节点无法与另一些节点连接,这时这两大部分节点会各自为主;当网络恢复时,也无法恢复成一个整体。
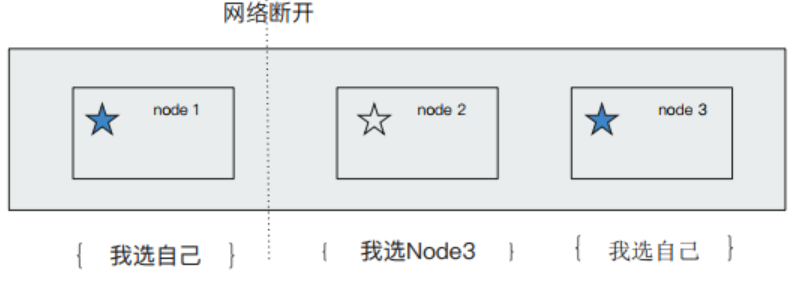
如何避免脑裂问题
要限定一个选举条件,设置 Quorum(仲裁):
- Quorum = (master 节点总数 / 2)+ 1
只有当 Master eligible 节点数大于 Quorum 时,才能进行选举。
在 ES 7.0 之前,为了避免脑裂问题,需要手动设置 discovery.zen.minimum_master_nodes 为 Quorum。
在 ES 7.0 之后,ES 会自己处理脑裂问题,不需要用户处理。
5,ES 中的分片
ES 中的分片(Shard)用于存储数据,是存储的最小单元。
分片有两种:主分片(Primary Shard)和副本分片(Replica Shard),副本分片是主分片的拷贝。
主分片用于数据水平扩展的问题,主分片数在索引创建时指定,之后不允许修改。
副本分片用于解决数据高可用的问题,副本分片数可以动态调整。
分片数可以通过索引的 setting 进行设置,比如:
PUT /index_name
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
其中 number_of_shards 表示主分片数,number_of_replicas 表示每个主分片的副本分片数。
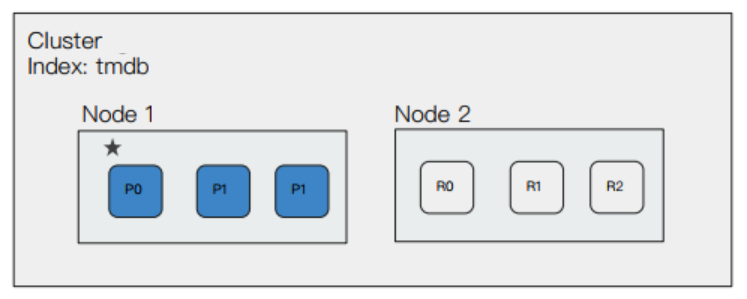
如果一个集群有 3 个数据节点,某个索引有 3 个主分片,1 一个副本分片,那么它的节点分布会像下面这样:
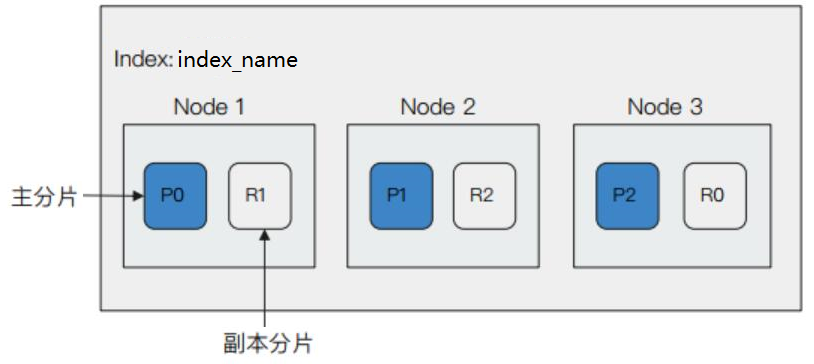
其中蓝色框为主分片,白色框为副本分片。
ES 在分配主副分片时,会将副本分片与主分片应该在不同的节点上。
主分片和副本分片分别分布到不同的数据节点上,这样的话,如果有某个数据节点宕机,也不会影响整个系统的使用。
ES 7.0 开始,默认的主分片数为 1,默认的副本分片数为 0。在生产环境中,副本分片数至少为 1。
5.1,生产环境如何设置分片数
分片数设置不合理引发的问题:

5.2,集群节点的变化

根据这样的配置(3 个主分片,1 个副本分片),如果只有一个节点,则会导致副本分片无法分配(ES 会将主副分片分配在不同的节点上),集群状态为 yellow。
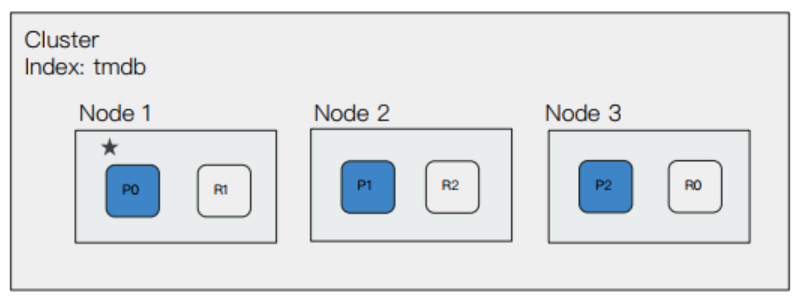
如果此时增加一个数据节点,那么副本分片就得以分配,集群具备了故障转移能力,集群状态转为 green。
如果此时再增加一个数据节点,那么主节点会重新分配分片的分布。同时,集群的整体能力也得到了提升。
5.3,故障转移
如果此时有一个节点发生故障,比如主节点发生了故障:
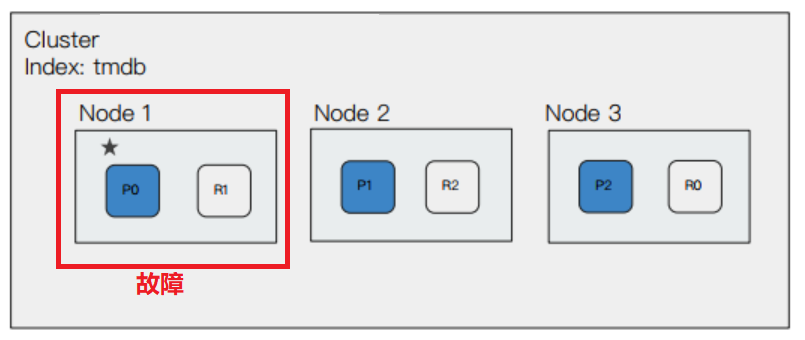
此时集群的状态会变为 yellow,然后会重新选举主节点(假设选举了 Node2 为主节点),并且原来的 Node1 节点上的 p0 和 R1 分片,会被分配到 Node2 和 Node3 上。
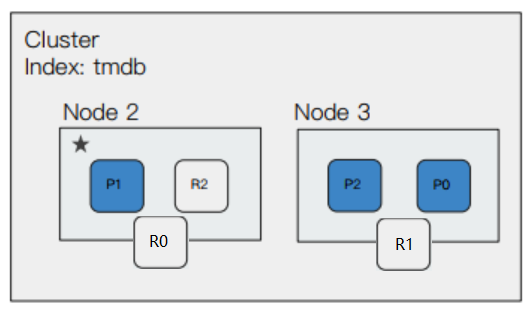
集群调整完毕后,会重新恢复到 green 状态。
6,分片的内部原理
ES 中的一个分片对应了 Lucene 中的一个 Index。
6.1,Lucene Index
在 Lucene 中,单个倒排索引文件称为 Segment。
Segment 是不可变的,当有新的文档写入时,会生成新的 Segment(放在文件系统缓存中)。
多个 Segment 汇总在一起称为 Lucene 中的 Index,也就是 ES 中的分片。

6.2,Refresh 刷新
ES 的文档在写入时,会先放在 Index Buffer(内存) 中,当 Index Buffer 的空间被占用到一定程度/时间周期后,会 Refresh 到 Segment 中,Index Buffer 则会被清空。
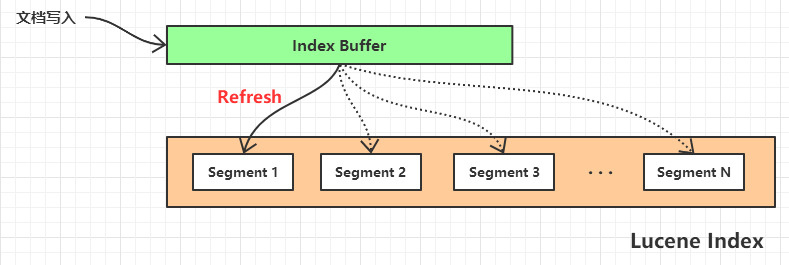
Refresh 的刷新频率可以通过 index.refresh_interval 参数进行设置,默认为 1 秒。
或者当 Index Buffer 被占用到 JVM 的 10%(默认值),也会触发 Refresh。
当文档被 Refresh 到 Segment 后,就可以被 ES 检索到了。
6.3,Transaction log
写入文档时,会先放在 Index Buffer 中,而 Index Buffer 是在内存中,为了防止内存意外(比如断电)丢失,在写入 Index Buffer 的同时,也会写到 Transaction log(磁盘)中。
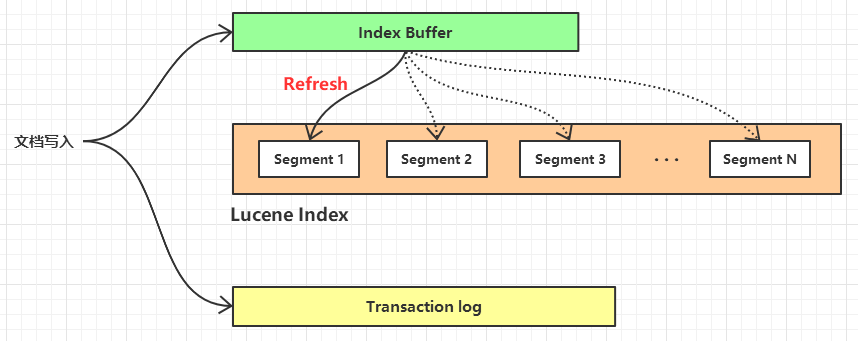
一个 Transaction log 默认是 512M。
6.4,Flush 操作
ES 的 Flush 会触发以下操作:
- 调用 Refresh
- 调用 fsync,将文件系统缓存中的 Segment 写入磁盘。
- 清空 Transaction log。
Flush 操作默认 30 分钟调用一次,或者当 Transaction log 满(默认 512 M)时也会触发 Flush。
6.5,Merge 合并
当越来越多的 Segment 被写入到磁盘后,磁盘上的 Segment 会变得很多,ES 会定期 Merge 这些 Segment。
文档的删除操作并不会马上被真正的删除,而是会写入 del 文件中,Merge 操作也会删除该文件。
Merge 操作可以由 ES 自动触发,也可以手动强制 Merge,语法如下:
POST index_name/_forcemerge
7,文档的分布式存储
文档会均匀分布在分片上,充分利用硬件资源,避免资源利用不均。
文档到分片的路由算法:
shard_index = hash(_routing) % number_of_primary_shards- Hash 算法可以保证文档均匀的分散到分片上。
- 默认的
_routing值为文档 id。 _routing的值也可以自行指定。
正是因为文档的路由算法是基于主分片数来计算的,所以主分片数一旦确定以后,就不能修改。
_routing 的设置语法如下:
POST index_name/_doc/doc_id/routing=xxx
{
# 文档数据
}
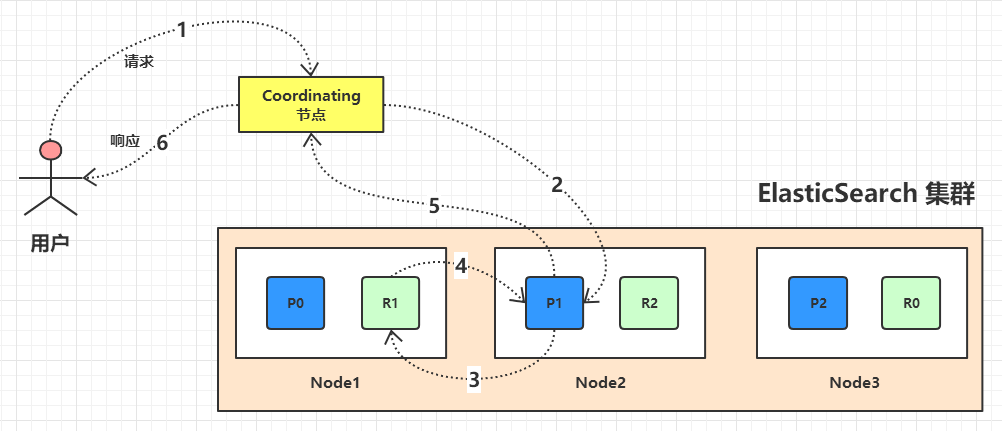
文档的 Write 操作(插入,更新,删除)的流程:
- 客户将文档的 Write 请求发送到 Coordinating 节点(Coordinating 节点负责处理客户请求,而不是 Master 节点)。
- Coordinating 节点通过 Hash 算法找到该文档的主分片。
- 在主分片上进行 Write 操作,主分片 Write 成功后,将该 Write 请求发送到所有的副本分片。
- 所有副本分片进行相应的 Write 操作,成功后,将结果返回给主分片。
- 主分片将所以的执行结果反馈给 Coordinating 节点。
- Coordinating 节点将最终的结果反馈给客户端。
8,分布式查询及相关性算分
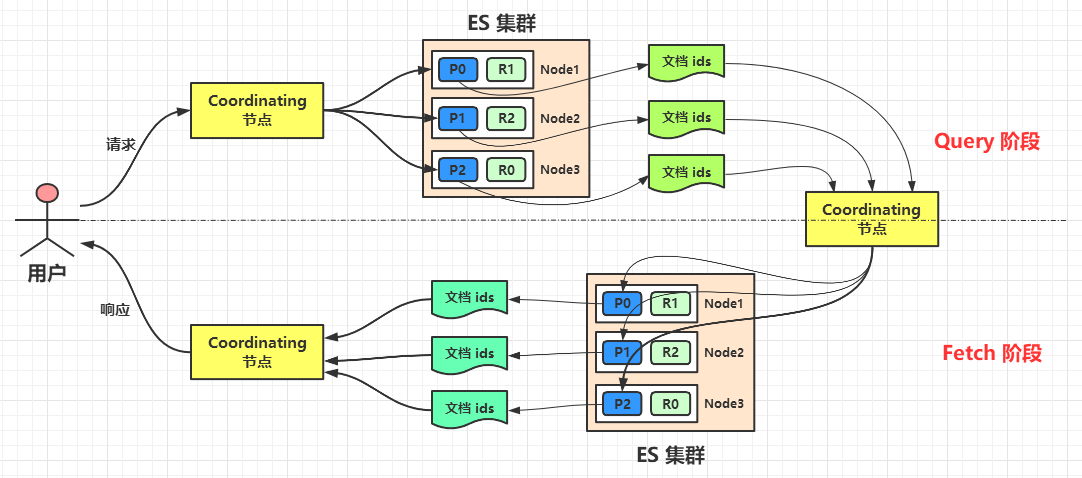
8.1,Query Then Fetch 过程
ES 的搜索过程分两个阶段:
- Query 阶段:
- 用户将查询请求发送到 Coordinating 节点,Coordinating 节点会随机选择 N(主分片数) 个分片,发送查询请求。
- 收到查询请求的分片执行查询,并进行排序。然后每个分片都会返回
From + Size个排好序的文档 ID 和排序值(score),给 Coordinating 节点。
- Fetch 阶段:
- Coordinating 节点会将从所有分片得到的文档重新排序,重新得到
From + Size个文档的 ID。 - Coordinating 节点以
Multi Get的方式,到相应的分片获取具体的文档信息,并返回给用户。
- Coordinating 节点会将从所有分片得到的文档重新排序,重新得到
这两个阶段合称为 Query Then Fetch。
8.2,Query Then Fetch 的问题

8.3,算分不准的解决办法

(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号