ElasticSearch 聚合分析
公号:码农充电站pro
主页:https://codeshellme.github.io
ES 中的聚合分析(Aggregations)是对数据的统计分析功能,它的优点是实时性较高,相比于 Hadoop 速度更快。
1,聚合的分类
ES 中的聚合分析主要有以下 3 大类,每一类都提供了多种统计方法:
- Metrics:对文档字段进行统计分析(数学运算),多数 Metrics 的输出是单个值,部分 Metrics 的输出是多个值。
- Bucket:一些满足特定条件的文档集合(对文档进行分组)。
- Pipeline:对其它的聚合结果进行再聚合。
- Avg bucket:求平均值
- Max bucket:求最大值
- Min bucket:求最小值
- Sum bucket:求和
- Stats bucket:综合统计
- Percentiles bucket:百分位数统计
- Cumulative sum:累计求和
- 等
一般使用聚合分析时,通常将 size 设置为 0,表示不需要返回查询结果,只需要返回聚合结果。
一个示例:
# 多个 Metric 聚合,找到最低最高和平均工资
POST index_name/_search
{
"size": 0, # size 为 0
"aggs": {
"max_salary": { # 自定义聚合名称
"max": { # 聚合类型
"field": "salary" # 聚合字段
}
},
"min_salary": { # 自定义聚合名称
"min": { # 聚合类型
"field": "salary" # 聚合字段
}
},
"avg_salary": { # 自定义聚合名称
"avg": { # 聚合类型
"field": "salary" # 聚合字段
}
}
}
}
2,Metrics 聚合
Metrics 聚合可以分为单值分析和多值分析:
- 单值分析:分析结果是单个值
- max
- min
- avg
- sum
- cardinality:类似 distinct count
- 注意 cardinality 对 keyword 类型数据和 text 类型数据的区别
- keyword 类型不会进行分词处理,而 text 类型会进行分词处理
- 等
- 多值分析:分析结果是多个值
- stats
- extended stats
- string stats
- percentiles
- percentile ranks
- top hits:根据一定的规则排序,选 top N
- 等
2.1,示例
示例,一个员工表定义:
DELETE /employees
PUT /employees/
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "keyword"
},
"job" : {
"type" : "text",
"fields" : {
"keyword" : { # 子字段名称
"type" : "keyword", # 子字段类型
"ignore_above" : 50
}
}
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "integer"
}
}
}
}
插入一些测试数据:
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}
min 聚合分析:
# Metric 聚合,找到最低的工资
POST employees/_search
{
"size": 0,
"aggs": {
"min_salary": {
"min": { # 聚合类型,求最小值
"field":"salary"
}
}
}
}
# 返回结果
"hits": {
"total": {
"value": 20, # 一共统计了多少条数据
"relation": "eq"
},
"max_score": null,
"hits": [...] # 因为 size 为 0
},
"aggregations": {
"min_salary": { # 自定义的聚合名称
"value": 9000,
}
}
stats 聚合分析:
# 输出多值
POST employees/_search
{
"size": 0,
"aggs": {
"stats_salary": {
"stats": { # stats 聚合
"field":"salary"
}
}
}
}
# 返回多值结果
"aggregations": {
"stats_salary": { # 自定义的聚合名称
"count": 20,
"min": 9000,
"max": 50000,
"avg": 24700,
"sum": 494000
}
}
2.2,top_hits 示例
# 指定 size,不同岗位中,年纪最大的3个员工的信息
POST employees/_search
{
"size": 0,
"aggs":{
"old_employee":{ # 聚合名称
"top_hits":{ # top_hits 分桶
"size":3,
"sort":[ # 根据 age 倒序排序,选前 3 个
{"age":{"order":"desc"}}
]
}
}
}
}
3,Bucket 聚合
Bucket 聚合按照一定的规则,将文档分配到不同的桶中,达到分类的目的。
Bucket 聚合支持嵌套,也就是在桶里再次分桶。
Bucket 聚合算法:
- Terms:根据关键字(字符串)分桶。text 类型的字段需要打开 fielddata 配置。
- 注意 keyword 类型不会做分词处理,text 类型会做分词处理。
- 另外 size 参数可以控制桶的数量。
- Range:按照范围进行分桶,主要针对数字类型的数据。
- Date range
- Histogram:直方图分桶,指定一个间隔值,来进行分桶。
- Date histogram
- 等
3.1,Terms 示例
示例:
# 对 keword 进行聚合
POST employees/_search
{
"size": 0, # size 为 0
"aggs": {
"jobs": { # 自定义聚合名称
"terms": { # terms 聚合
"field":"job.keyword" # job 字段的 keyword 子字段
}
}
}
}
# 返回值结构示例
"aggregations": {
"genres": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ # 很多桶,这是一个数组
{
"key": "electronic",
"doc_count": 6
},
{
"key": "rock",
"doc_count": 3
},
{
"key": "jazz",
"doc_count": 2
}
]
}
}
对 Text 字段进行 terms 聚合查询会出错,示例:
# 对 Text 字段进行 terms 聚合查询
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job" # job 是 text 类型
}
}
}
}
# 对 Text 字段打开 fielddata,以支持 terms aggregation
PUT employees/_mapping
{
"properties" : {
"job":{
"type": "text",
"fielddata": true # 打开 fielddata
}
}
}
3.2,Terms 性能优化
当某个字段的写入和 Terms 聚合比较频繁的时候,可用通过打开 eager_global_ordinals 配置来对 Terms 操作进行优化。
示例:
PUT index_name
{
"mappings": {
"properties": {
"foo": { # 字段名称
"type": "keyword",
"eager_global_ordinals": true # 打开
}
}
}
}
3.3,嵌套聚合示例
Bucket 聚合支持添加子聚合来进一步分析,子聚合可以是一个 Metrics 或者 Bucket。
示例 1:
# 指定 size,不同岗位中,年纪最大的3个员工的信息
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": { # 先做了一个 terms 分桶
"field":"job.keyword"
},
"aggs":{ # 嵌套一个聚合,称为子聚合,
"old_employee":{ # 聚合名称
"top_hits":{ # top_hits 分桶
"size":3,
"sort":[ # 根据 age 倒序排序,选前 3 个
{"age":{"order":"desc"}}
]
}
}
}
}
}
}
示例 2 :
POST employees/_search
{
"size": 0,
"aggs": {
"Job_salary_stats": {
"terms": { # 先做了一个 terms 分桶
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": { # 子聚合是一个 stats
"field": "salary"
}
}
}
}
}
}
# 多次嵌套
POST employees/_search
{
"size": 0,
"aggs": { # 第 1 层
"Job_gender_stats": {
"terms": {
"field": "job.keyword" # 先根据岗位分桶
},
"aggs": { # 第 2 层
"gender_stats": {
"terms": {
"field": "gender" # 再根据性别分桶
},
"aggs": { # 第 3 层
"salary_stats": {
"stats": { # 最后根据工资统计 stats
"field": "salary"
}
}
}
}
}
}
}
}
3.4,Range 示例
对员工的工资进行区间聚合:
# Salary Ranges 分桶,可以自己定义 key
POST employees/_search
{
"size": 0,
"aggs": {
"salary_range": { # 自定义聚合名称
"range": { # range 聚合
"field":"salary", # 聚合的字段
"ranges":[ # range 聚合规则/条件
{
"to":10000 # salary < 10000
},
{
"from":10000, # 10000 < salary < 20000
"to":20000
},
{ # 如果没有定义 key,ES 会自动生成
"key":"可以使用 key 自定义名称",
"from":20000 # salary > 20000
}
]
}
}
}
}
3.5,Histogram 示例
示例,工资0到10万,以 5000一个区间进行分桶:
# Salary Histogram
POST employees/_search
{
"size": 0,
"aggs": {
"salary_histrogram": { # 自定义聚合名称
"histogram": { # histogram 聚合
"field":"salary", # 聚合的字段
"interval":5000, # 区间值
"extended_bounds":{ # 范围
"min":0,
"max":100000
}
}
}
}
}
4,Pipeline 聚合
Pipeline 聚合用于对其它聚合的结果进行再聚合。
根据 Pipeline 聚合与原聚合的位置区别,分为两类:
- Pipeline 聚合与原聚合同级,称为 Sibling 聚合
Max_bucket,Min_bucket,Avg_bucket,Sum_bucketStats_bucket,Extended-Status_bucketPercentiles_bucket
- Pipeline 聚合内嵌在原聚合之内,称为 Parent 聚合
Derivative:求导Cumulative-sum:累计求和Moving-function:滑动窗口
4.1,Sibling 聚合示例
示例:
# 平均工资最低的工作类型
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": { # 自定义聚合名称
"terms": {
"field": "job.keyword", # 先对岗位类型进行分桶
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary" # 再计算每种工资岗位的平价值
}
}
}
},
"min_salary_by_job":{ # 自定义聚合名称
"min_bucket": { # pipeline 聚合
"buckets_path": "jobs>avg_salary"
} # 含义是:对 jobs 中的 avg_salary 进行一个 min_bucket 聚合
}
}
}
4.2,Parent 聚合示例
示例:
# 示例 1
POST employees/_search
{
"size": 0,
"aggs": {
"age": { # 自定义聚合名称
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": { # 自定义聚合名称
"avg": {
"field": "salary"
}
}, # 自定义聚合名称
"derivative_avg_salary":{ # 注意 derivative 聚合的位置,与 avg_salary 同级
"derivative": { # 而不是与 age 同级
"buckets_path": "avg_salary" # 注意这里不再有箭头 >
}
}
}
}
}
}
# 示例 2
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"cumulative_salary":{
"cumulative_sum": { # 累计求和
"buckets_path": "avg_salary"
}
}
}
}
}
}
5,聚合的作用范围
ES 聚合的默认作用范围是 Query 的查询结果,如果没有写 Query,那默认就是在索引的所有数据上做聚合。
比如:
POST employees/_search
{
"size": 0,
"query": { # 在 query 的结果之上做聚合
"range": {
"age": {"gte": 20}
}
},
"aggs": {
"jobs": {
"terms": {"field":"job.keyword"}
}
}
}
ES 支持通过以下方式来改变聚合的作用范围:
- Query:ES 聚合的默认作用范围。
- 一般设置 size 为 0。
- 如果没有写 Query,那默认就是在索引的所有数据上做聚合。
- Filter:写在某个聚合的内部,只控制某个聚合的作用范围。
- 一般设置 size 为 0。
- Post Filter:对聚合没有影响,只是对聚合的结果进行再过滤。
- 不再设置 size 为 0。
- 使用场景:获取聚合信息,并获取符合条件的文档。
- Global:会覆盖掉 Query 的影响。
5.1,Filter 示例
示例:
POST employees/_search
{
"size": 0,
"aggs": {
"older_person": { # 自定义聚合名称
"filter":{ # 通过 filter 改变聚合的作用范围
"range":{
"age":{"from":35}
}
}, # end older_person
"aggs":{ # 在 filter 的结果之上做聚合
"jobs":{ # 自定义聚合名称
"terms": {"field":"job.keyword"}
}
}
}, # end older_person
"all_jobs": { # 又一个聚合,没有 filter
"terms": {"field":"job.keyword"}
}
}
}
5.2,Post Filter 示例
示例:
POST employees/_search
{
"aggs": {
"jobs": { # 自定义聚合名称
"terms": {"field": "job.keyword"}
}
}, # end aggs
"post_filter": { # 一个 post_filter,对聚合的结果进行过滤
"match": {
"job.keyword": "Dev Manager"
}
}
}
5.3,Global 示例
POST employees/_search
{
"size": 0,
"query": { # 一个 query
"range": {
"age": {"gte": 40}
}
},
"aggs": {
"jobs": { # 一个聚合
"terms": {"field":"job.keyword"}
},
"all":{ # 又一个聚合,名称为 all
"global":{}, # 这里的 global 会覆盖掉上面的 query,使得聚合 all 的作用范围不受 query 的影响
"aggs":{ # 子聚合
"salary_avg":{ # 自定义聚合名称
"avg":{"field":"salary"}
}
}
}
}
}
6,聚合中的排序
6.1,基于 count 的排序
聚合中的排序使用 order 字段,默认按照 _count 和 _key 进行排序。
_count:表示按照文档数排序,如果不指定 _count,默认按照降序进行排序。_key:表示关键字(字符串值),如果文档数相同,再按照 key 进行排序。
示例 1:
# 使用 count 和 key
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {"gte": 20}
}
},
"aggs": {
"jobs": { # 自定义聚合名称
"terms": { # terms 聚合
"field":"job.keyword",
"order":[ # order 排序
{"_count":"asc"}, # 先安装文档数排序
{"_key":"desc"} # 如果文档数相同,再按照 key 排序
]
}
}
}
}
6.2,基于子聚合的排序
也可以基于子聚合排序。
示例 2:
# 先对工作种类进行分桶
# 再以工作种类的平均工资进行排序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": { # 自定义聚合名称
"terms": {
"field":"job.keyword",
"order":[ # 基于子聚合的排序
{"avg_salary":"desc"}
]
}, # end terms
"aggs": { # 子聚合
"avg_salary": { # 子聚合名称
"avg": {"field":"salary"}
}
}
} # end jobs
}
}
如果子聚合是多值输出,也可以基于 子聚合名.属性 来进行排序,如下:
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[ # 基于子聚合的属性排序
{"stats_salary.min":"desc"}
]
}, # end terms
"aggs": {
"stats_salary": { # 子聚合是多值输出
"stats": {"field":"salary"}
}
}
} # end jobs
}
}
7,聚合分析的原理及精准度
下面介绍聚合分析的原理及精准度的问题。
7.1,分布式系统的三个概念
分布式系统中有三个概念:
- 数据量
- 精准度
- 实时性
对于分布式系统(数据分布在不同的分片上),这三个指标不能同时具备,同时只能满足其中的 2 个条件:
- Hadoop 离线计算:可以同时满足大数据量和精准度。
- 近似计算:可以同时满足大数据量和实时性。
- 有限数据计算:可以同时满足精准度和实时性。
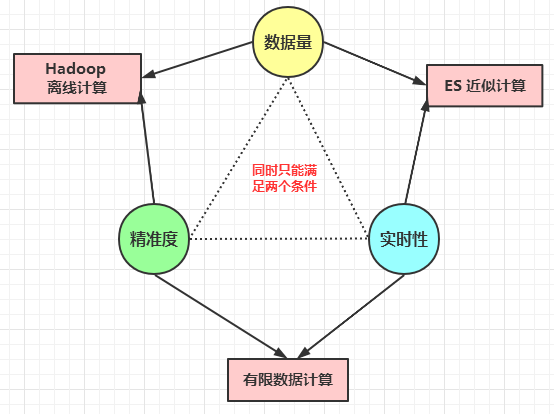
ES 属于近似计算,具备了数据量和实时性的特点,失去了精准度。
7.2,聚合分析的原理
ES 是一个分布式系统,数据分布在不同的分片上。
因此,ES 在进行聚合分析时,会先在每个主分片上做聚合,然后再将每个主分片上的聚合结果进行汇总,从而得到最终的聚合结果。
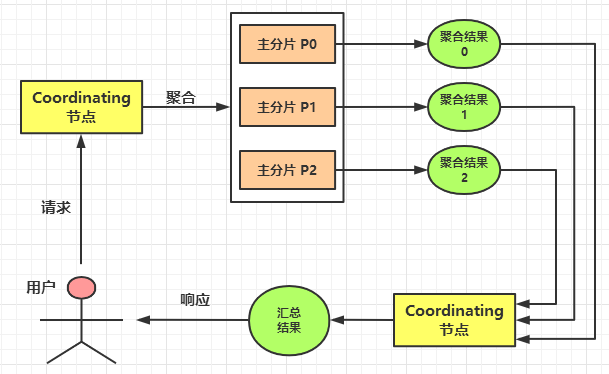
7.3,聚合分析的精准度
分布式聚合的原理,会天生带来精准度的问题,但并不是所有的聚合分析都有精准度问题:
下面来看下 Terms 聚合存在的问题,下图中的:
- A(6) 表示 A 类的文档数有 6 个。
- B(4) 表示 B 类的文档数有 4 个。
- C(4) 表示 C 类的文档数有 4 个。
- D(3) 表示 D 类的文档数有 3 个。
下图是 Terms 聚合流程:
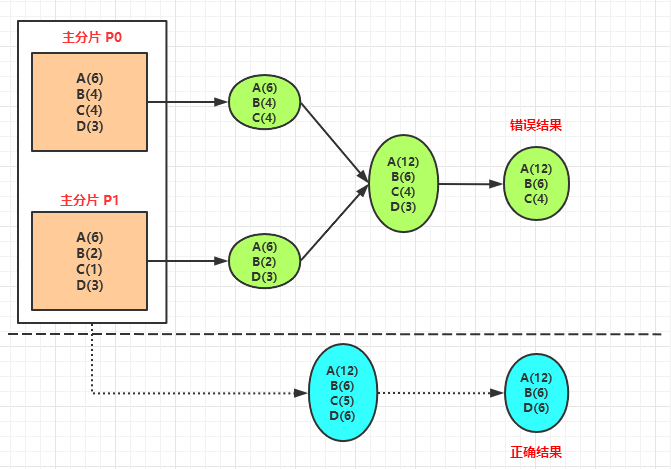
上图中,在进行 Terms 聚合时(最终结果只要按照数量排序的前 3 个),需要分别在分片 P0 和 P1上做聚合,然后再将它们的聚合结果进行汇总。
正确的聚合结果应该是 A(12),B(6),D(6),但是由于分片的原因,ES 计算出来的结果是 A(12),B(6),C(4)。这就是 Terms 聚合存在的精准度问题。
7.4,show_term_doc_count_error 参数
打开 show_term_doc_count_error 配置可以使得 terms 聚合的返回结果中有一个 doc_count_error_upper_bound 值(最小为0),通过该值可以了解精准程度;该值越小,说明 Terms 的精准度越高。
POST index_name/_search
{
"size": 0,
"aggs": {
"weather": { # 自定义聚合名称
"terms": { # terms 聚合
"field":"OriginWeather",
"show_term_doc_count_error":true # 打开
}
}
}
}
7.5,如何提高 terms 精准度
提高 terms 聚合的精准度有两种方式:
- 将主分片数设置为 1。
- 因为 terms 的不准确是由于分片导致的,如果将主分片数设置为 1,就不存在不准确的问题。
- 这种方式在数据量不是很大的时候,可以是使用。
- 将 shard_size 的值尽量调大(意味着从分片上额外获取更多的数据,从而提升准确度)。
- shard_size 值变大后,会使得计算量变大,进而使得ES 的整体性能变低,精准度变高。
- 所以需要权衡 shard_size 值与精准度的平衡。
- shard_size 值的默认值是 【size * 1.5 + 10】。
设置 shard_size 的语法:
POST my_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field":"OriginWeather",
"size":1,
"shard_size":1,
"show_term_doc_count_error":true
}
}
}
}
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号