
KNN 算法-理论篇-如何给电影进行分类
公号:码农充电站pro
主页:https://codeshellme.github.io
KNN 算法的全称是K-Nearest Neighbor,中文为K 近邻算法,它是基于距离的一种算法,简单有效。
KNN 算法即可用于分类问题,也可用于回归问题。
1,准备电影数据
假如我们统计了一些电影数据,包括电影名称,打斗次数,接吻次数,电影类型,如下:
| 电影名称 | 打斗次数 | 接吻次数 | 电影类型 |
|---|---|---|---|
| 黑客帝国 | 115 | 6 | 动作片 |
| 功夫 | 109 | 8 | 动作片 |
| 战狼 | 120 | 9 | 动作片 |
| 恋恋笔记本 | 5 | 78 | 爱情片 |
| 泰坦尼克号 | 6 | 60 | 爱情片 |
| 花样年华 | 8 | 69 | 爱情片 |
可以看到,电影分成了两类,分别是动作片和爱情片。
2,用KNN 算法处理分类问题
如果现在有一部新的电影A,它的打斗和接吻次数分别是80 和7,那如何用KNN 算法对齐进行分类呢?
我们可以将打斗次数作为X 轴,接吻次数作为Y 轴,将上述电影数据画在一个坐标系中,如下:
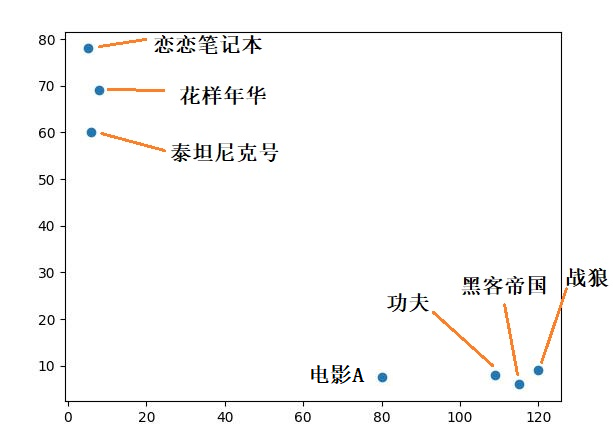
关于如何用Python 画图,可以参考文章《如何使用Python 进行数据可视化》
通过上图可以直观的看出,动作电影与爱情电影的分布范围是不同的。
KNN 算法基于距离,它的原理是:选择与待分类数据最近的K 个点,这K 个点属于哪个分类最多,那么待分类数据就属于哪个分类。
所以,要判断电影A 属于哪一类电影,就要从已知的电影样本中,选出距离电影A 最近的K 个点:
- 如果这K 个点中,属于动作电影较多,那么电影A 就属于动作电影。
- 如果这K 个点中,属于爱情电影较多,那么电影A 就属于爱情电影。
比如,我们从样本中选出三个点(即 K 为 3),那么距离电影A 最近的三个点是《功夫》,《黑客帝国》和《战狼》,而这三部电影都是动作电影。因此,可以判断电影A 也是动作电影。
另外,我们还要处理两个问题:
- 如何判断点之间的距离。
- 如何确定K 的值。
关于点之间的距离判断,可以参考文章《计算机如何理解事物的相关性》。
至于K 值的选择,K 值较大或者较小都会对模型的训练造成负面影响,K 值较小会造成过拟合,K 值较大欠拟合。
因此,K 值的选择,一般采用交叉验证的方式。
交叉验证的思路是,把样本集中的大部分样本作为训练集,剩余部分用于预测,来验证分类模型的准确度。一般会把 K 值选取在较小范围内,逐一尝试K 的值,当模型准确度最高时,就是最合适的K 值。
可以总结出,KNN 算法用于分类问题时,一般的步骤是:
- 计算待分类物体与其他物体之间的距离;
- 按照距离进行排序,统计出距离最近的 K 个邻居;
- K 个最近的邻居,属于哪个分类最多,待分类物体就属于哪一类。
3,用KNN 算法处理回归问题
如果,我们现在有一部电影B,知道该电影属于动作电影,并且知道该电影的接吻次数是7,现在想预测该电影的打斗次数是多少?
这个问题就属于回归问题。
分类问题的预测结果是离散值,
回归问题的预测结果是连续值。
首先看下,根据已知数据,如何判断出距离电影B 最近的K 个点。
我们依然设置K 为3,已知数据为:
- 电影B 属于动作电影。
- 电影B 的接吻次数是 7。
根据已知数据可以画出下图:
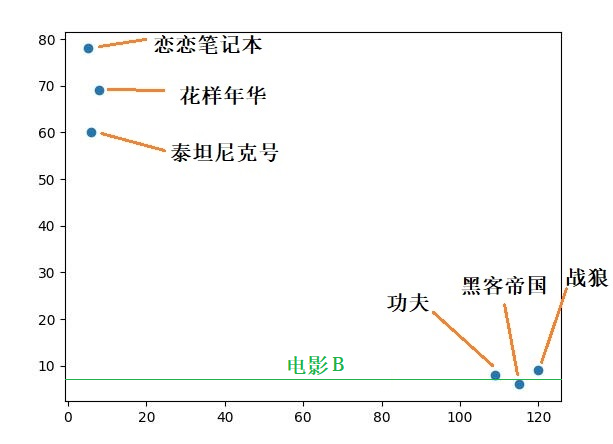
图中我画出了一条水平线,这条线代表所有接吻次数是7 的电影,接下来就是要找到距离这条线最近的三部(K 为 3)动作电影。
可以看到,距离这条水平线最近的三部动作电影是《功夫》,《黑客帝国》和《战狼》,那么这三部电影的打斗次数的平均值,就是我们预测的电影B 的打斗次数。
所以,电影B 的打斗次数是:
(115 + 109 +120) / 3 ≈ 115
4,总结
本篇文章主要介绍了KNN 算法的基本原理,它简单易懂,即可处理分类问题,又可处理回归问题。
KNN 算法是基于距离的一种机器学习算法,需要计算测试点与样本点之间的距离。因此,当数据量大的时候,计算量就会非常庞大,需要大量的存储空间和计算时间。
另外,如果样本数据分类不均衡,比如有些分类的样本非常少,那么该类别的分类准确率就会很低。因此,在实际应用中,要特别注意这一点。
(本节完。)
推荐阅读:
欢迎关注作者公众号,获取更多技术干货。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号