【python标准库模块五】Xml模块学习
Xml模块
xml本身是一种格式规范,是一种包含了数据以及数据说明的文本格式规范。在json没有兴起之前各行各业进行数据交换的时候用的就是这个。目前在金融行业也在广泛在运用。
举个简单的例子,xml是一种标记性语言,格式类似于<data>数据</data>,这样一个封闭起来是一个整体

以上就是xml内部的样子,可以将其想象成一棵树,如下图所示
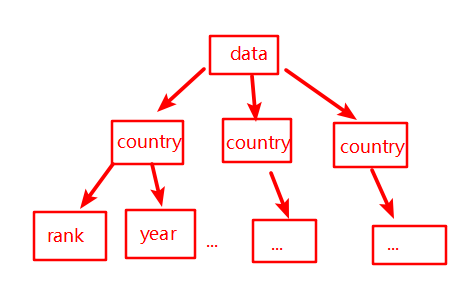
利用python解析xml文件
- xml模块的导入
import xml.etree.ElementTree as ET
1.获取标签的相关信息接口
一般访问xml文件的时候,先得到根节点,然后再遍历根节点,得到根节点的子节点相关信息
#得到树根 root = tree.getroot() for element in root: print(element.tag) #获取标签名 print(element.attrib) #获取标签属性 print(element.text) #获取标签值
2.xml文件的查找操作
查找操作使用.iter("标签名")来做,这个函数会找到符合标签名的标签继承到一个可迭代的序类中。这个是从根节点开始搜索整棵树
#获取所有"rank"标签的text for element in root.iter("rank"): print(element.text) #获取标签值
查找使用.findall("标签名"),这个函数会找到符合标签名的所有标签集成到一个可迭代的序列中。这个是只能找当前这一级的
#获取所有根节点下的名字为country的标签。只能在自己的一级找 for element in root.findall("country"): print(element.tag) #获取标签名
查找使用.find("标签名"),这个函数会找到符合标签名的第一个标签。然后返回该标签 的子标签的序列
#找到root节点下标签名为country的标签,并返回其子标签组成的序列 for element in root.find("country"): print(element.tag) #获取标签名
3.xml的删除
这里分为修改标签的属性和标签的内容
import xml.etree.ElementTree as ET #得到xml树 tree = ET.parse("xml_lesson") #得到树根 root = tree.getroot() #找到root节点下标签名为country的标签,并返回其子标签组成的序列 node = root.find("country") node.set("name","China") node = node.find("rank") node.text = "1" #写回原文件 tree.write("xml_lesson")

4.xml文件的创建
主要思想是先创建节点,再把节点打包成树
import xml.etree.ElementTree as ET #创建根节点 root = ET.Element("data") #创建子节点,并添加属性 age = ET.SubElement(root,"age") age.attrib = {"age":"age attribute"} age.text = "23" #创建elementtree对象,写文件 tree = ET.ElementTree(root) tree.write("test.xml")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号