
Python自然语言处理 第2章获得文本语料和词汇资源 学习笔记
2.1 获取文本语料库
古腾堡语料库
NLTK 包含古腾堡项目(Project Gutenberg)电子文本档案的经过挑选的一小部分文本,该项目大约有25,000本免费电子图书,放在http://www.gutenberg.org/上。 找出简.奥斯丁的《爱玛》,并给它一个简短的名称emma,然后找出它包含多少个词。
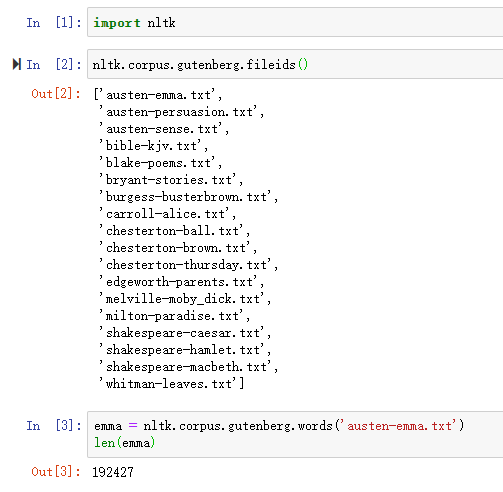
可以采用以下语句来处理索引和第1章中的其他任务

可以通过以下语句进行简化来定义emma

sents()函数把文本划分成句子,其中每一个句子是一个单词列表:

虽然古腾堡项目包含成千上万的书籍,它代表既定的文学。考虑较不正式的语言也是很重要的。NLTK 的网络文本小集合的内容包括Firefox 交流论坛,在纽约无意听到的对话, 加勒比海盗的电影剧本,个人广告和葡萄酒的评论:

还有一个即时消息聊天会话语料库,最初由美国海军研究生院为研究自动检测互联网幼童虐待癖而收集的。语料库包含超过10,000 张帖子,以“UserNNN”形式的通用名替换掉用户名,手工编辑消除任何其他身份信息,制作而成。

布朗语料库是第一个百万词级的英语电子语料库的,由布朗大学于1961 年创建。这个语料库包含500 个不同来源的文本,按照文体分类,如:新闻、社论等。

比较不同文体中的情态动词的用法,产生特定文体的计数
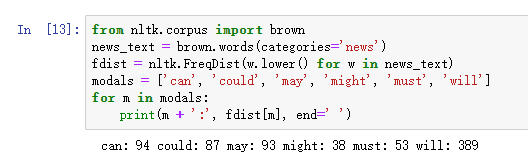
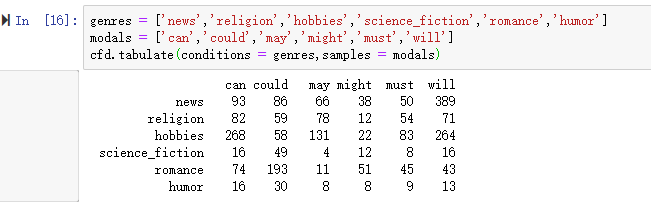
可以看出新闻文体中最常见的情态动词是will,而言情文体中最常见的情态动词是could

 浙公网安备 33010602011771号
浙公网安备 33010602011771号