
算法笔记 第7章 提高篇(1)--数据结构专题(1) 学习笔记
7.1栈的应用
栈:后进先出,可以理解为一个箱子,而箱子的容量仅供一本书放入或拿出。每次可以把一本书放在箱子的最上方,也可以把箱子最上方的书拿出。
栈顶指针:始终指向栈的最上方元素的一个标记,栈中没有元素(即栈空)时令TOP为-1.
栈的常见操作示范实现,使用数组st[]来实现栈:
(1)清空(clear):
栈的清空操作将栈顶指针TOP置为-1,表示栈中没有元素。
void clear(){
TOP = -1;
}
(2)获取栈内元素个数(size)
栈内元素个数为TOP+1
int size(){
return TOP + 1;
}
(3)判空(empty)
当TOP == -1时,栈为空,返回true;否则,返回false
bool empty(){
if(TOP == -1) return true;
else return false;
}
(4) 进栈(push)
void push(int x){
st[++TOP] = x;
}
(5)出栈(pop)
void pop(){
TOP--;
}
(6)取栈顶元素(top)
int top(){
return st[TOP];
}
在使用pop()函数和top()函数之前必须先使用empty()函数判断栈是否为空。
可以使用STL中的stack容器,STL中没有实现栈的清空,如果需要实现栈的清空,可以用一个while循环反复pop出元素直到栈空。
while(!st.empty()){
st.pop();
}
PAT 1051 Pop Sequence (25分)
Given a stack which can keep M numbers at most. Push N numbers in the order of 1, 2, 3, ..., N and pop randomly. You are supposed to tell if a given sequence of numbers is a possible pop sequence of the stack. For example, if M is 5 and N is 7, we can obtain 1, 2, 3, 4, 5, 6, 7 from the stack, but not 3, 2, 1, 7, 5, 6, 4.
Input Specification:
Each input file contains one test case. For each case, the first line contains 3 numbers (all no more than 1000): M (the maximum capacity of the stack), N (the length of push sequence), and K (the number of pop sequences to be checked). Then K lines follow, each contains a pop sequence of N numbers. All the numbers in a line are separated by a space.
Output Specification:
For each pop sequence, print in one line "YES" if it is indeed a possible pop sequence of the stack, or "NO" if not.
Sample Input:
5 7 5
1 2 3 4 5 6 7
3 2 1 7 5 6 4
7 6 5 4 3 2 1
5 6 4 3 7 2 1
1 7 6 5 4 3 2
Sample Output:
YES
NO
NO
YES
NO
#include<cstdio> #include<stack> using namespace std; const int maxn = 1010; int arr[maxn]; //保存出栈顺序 stack<int> st; //入栈 int main(){ int m,n,T; scanf("%d%d%d",&m,&n,&T); while(T--){ while(!st.empty()){ st.pop(); } for(int i=1;i<=n;i++){ scanf("%d",&arr[i]); } int current = 1; bool flag = true; for(int i=1;i<=n;i++){ st.push(i); if(st.size()>m){ flag = false; break; } while(!st.empty() && arr[current] == st.top()){ st.pop(); current++; } } if(st.empty() == true && flag == true){ printf("YES\n"); }else{ printf("NO\n"); } } return 0; }
7.2 队列的应用
队列是一种先进先出的数据结构。日常生活中有很多地方都会出现队列这个概念,比如食堂里排队打饭,每个人都要排到队伍的最后面,而队伍最前面的人则打饭出队。队列总是从队尾加入元素,而从队首移除元素,并且满足先进先出的规则。
一般来说,需要一个队首指针front来指向队首元素的前一个元素,而使用一个队尾指针rear来指向队尾元素。下面将使用数组q[]来实现队列,而int型变量front存放队首元素的前一个元素的下标、rear存放队尾元素的下标。
(1) 清空
void clear(){
front = rear = -1;
}
(2) 获取队列内元素的个数
int size(){
return rear - front;
}
(3) 判空
bool empty(){
if(front == rear) return true;
else return false;
}
(4) 入队
void push(int x){
q[++rear] = x;
}
(5)出队
void pop(){
front++;
}
(6)取队首元素
int get_front(){
return q[front+1];
}
(7)取队尾元素
int get_rear(){
return q[rear];
}
Mice and Rice is the name of a programming contest in which each programmer must write a piece of code to control the movements of a mouse in a given map. The goal of each mouse is to eat as much rice as possible in order to become a FatMouse.
First the playing order is randomly decided for NP programmers. Then every NG programmers are grouped in a match. The fattest mouse in a group wins and enters the next turn. All the losers in this turn are ranked the same. Every NG winners are then grouped in the next match until a final winner is determined.
For the sake of simplicity, assume that the weight of each mouse is fixed once the programmer submits his/her code. Given the weights of all the mice and the initial playing order, you are supposed to output the ranks for the programmers.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: NP and NG (≤), the number of programmers and the maximum number of mice in a group, respectively. If there are less than NG mice at the end of the player's list, then all the mice left will be put into the last group. The second line contains NP distinct non-negative numbers Wi (,) where each Wi is the weight of the i-th mouse respectively. The third line gives the initial playing order which is a permutation of 0 (assume that the programmers are numbered from 0 to NP−1). All the numbers in a line are separated by a space.
Output Specification:
For each test case, print the final ranks in a line. The i-th number is the rank of the i-th programmer, and all the numbers must be separated by a space, with no extra space at the end of the line.
Sample Input:
11 3
25 18 0 46 37 3 19 22 57 56 10
6 0 8 7 10 5 9 1 4 2 3
Sample Output:
5 5 5 2 5 5 5 3 1 3 5
#include<cstdio> #include<queue> using namespace std; const int maxn = 1010; struct mouse{ int weight; int R; }mouse[maxn]; int main(){ int np,ng,order; scanf("%d%d",&np,&ng); for(int i=0;i<np;i++){ scanf("%d",&mouse[i].weight); } queue<int> q; for(int i = 0;i<np;i++){ scanf("%d",&order); q.push(order); } int temp = np,group; while(q.size()!=1){ if(temp%ng == 0) group = temp/ng; else group = temp/ng + 1; for(int i = 0;i<group;i++){ int k = q.front(); for(int j = 0;j<ng;j++){ if(i * ng + j >= temp) break; int front = q.front(); if(mouse[front].weight > mouse[k].weight){ k = front; } mouse[front].R = group + 1; q.pop(); } q.push(k); } temp = group; } mouse[q.front()].R = 1; for(int i=0;i<np;i++){ printf("%d",mouse[i].R); if(i <np-1) printf(" "); } return 0; }
7.3 链表处理
7.3.1 链表的概念
链表由若干个结点组成,且结点在内存中的存储位置通常是不连续的。链表的两个结点之间一般通过一个指针来从一个结点指向另一个结点,因此链表的结点一般由两部分构成,即数据域和指针域。
struct node{ typename data; node* next; };
以链表是否存在头结点,可以把链表分为带头结点的链表和不带头结点的链表。头结点一般称为head,数据域data不存放任何内容,而指针域next指向第一个数据域有内容的结点。本书中的链表均采用带头结点的写法。
7.3.2 使用malloc函数或new运算符为链表结点分配内存空间
1.malloc函数
malloc函数是C语言中stdlib.h头文件下用于申请动态内存的函数,其返回类型是申请的同变量类型的指针,用法如下:
typename *p = (typename*)malloc(sizeof(typename));
以申请一个int型变量和一个node型结构体变量为例:
int *p = (int*)malloc(sizeof(int));
node *p = (node*)malloc(sizeof(node));
2.new 运算符
typename *p = new typename;
同样以申请一个int型变量和一个node型结构体变量为例:
int *p = new int;
node *p = new node;
3.内存泄漏
内存泄漏是指使用malloc与new开辟出来的内存空间在使用过后没有释放,导致其在程序结束之前始终占据该内存空间,这在一些较大的程序中很容易导致内存消耗过快以致最后无内存可分配。因此必须记住,在使用完malloc与new开辟出来的空间后必须将其释放,否则会造成内存泄漏。
(1) free函数
free函数是对应malloc函数的,同样是在stdlib.h头文件下。
free(p);
malloc函数与free函数必须成对出现,否则容易产生内存泄漏。
(2) delete运算符
delete运算符是对应new运算符的,其使用方法和实现效果均与free相同。
delete(p);
new运算符与delete运算符必须成对出现,否则会容易产生内存泄漏。
7.3.3 链表的基本操作
1.创建链表
#include<stdio.h> #include<stdlib.h> struct node{ int data; node *next; }; node* create(int Array[]){ node *p,*pre,*head; //pre保存当前结点的前驱结点,head为头结点 head = new node; head->next = NULL; pre = head; for(int i=0;i<5;i++){ p = new node; p->data = Array[i]; p->next = NULL; pre->next = p; pre = p; } return head; } int main(){ int Array[5] = {5,3,6,1,2}; node *L = create(Array); L = L->next; while(L != NULL){ printf("%d ",L->data); L = L->next; } return 0; }
2.查找元素
//在以head为头结点的链表上计数元素x的个数 int search(node* head,int x){ int count = 0; node* p = head->next; while(p != NULL){ if(p->data == x){ count++; } p = p->next; } return count; }
3.插入元素
//将x插入以head为头结点的链表的第pos个位置上 void insert(node *head,int pos,int x){ node *p = head; for(int i=0;i<pos-1;i++){ p = p->next; //pos-1是为了到插入位置的前一个结点 } node *p = new node; //新建结点 q->data = x; //新结点的数据域为x q->next = p->next; //新结点的下一个结点指向原先插入位置的结点 p->next = q; //前一个位置的结点指向新结点 }
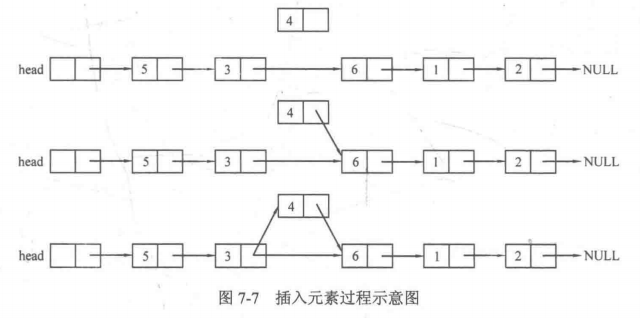
4.删除元素
//删除以head为头结点的链表中所有数据为x的结点 void del(node *head,int x){ node* p = head->next; //p从第一个结点开始枚举 node* pre = head; //pre始终保存p的前驱结点的指针 while(p != NULL){ if(p->data == x){ //数据域恰好为x,说明要删除该结点 pre->next = p->next; delete(p); p = pre->next; }else{ //数据域不是x,把pre和p都后移一位 pre = p; p = p->next; } } }
7.3.4静态链表
静态链表的实现原理是hash,即通过建立一个结构体数组,并令数组的下标直接表示结点的地址,来达到直接访问数组中的元素就能访问结点的结果。
struct Node{ typename data; int next; }node[size];
在使用静态链表时,尽量不要把结构体类型名和结构体变量名取成相同的名字。
PAT A1032 Sharing (25分)
To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.
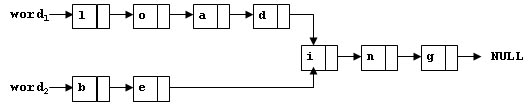
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −.
Then N lines follow, each describes a node in the format:
Address Data NextwhereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010Sample Output 1:
67890Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1Sample Output 2:
-1#include<cstdio> const int maxn = 100010; struct NODE{ char data; int next; int flag; }node[maxn]; int main(){ for(int i=0;i<maxn;i++){ node[i].flag = false; } int ad1,ad2,n; scanf("%d %d %d",&ad1,&ad2,&n); int add,data,p; for(int i=0;i<n;i++){ scanf("%d %c %d",&add,&data,&p); node[add].data = data; node[add].next = p; } for(p=ad1;p != -1;p=node[p].next){ node[p].flag = true; } for(p = ad2; p != -1;p=node[p].next){ if(node[p].flag == true){ break; } } if(p!=-1){ printf("%05d\n",p); }else{ printf("-1\n"); } return 0; }
A linked list consists of a series of structures, which are not necessarily adjacent in memory. We assume that each structure contains an integer key and a Next pointer to the next structure. Now given a linked list, you are supposed to sort the structures according to their key values in increasing order.
Input Specification:
Each input file contains one test case. For each case, the first line contains a positive N (<) and an address of the head node, where N is the total number of nodes in memory and the address of a node is a 5-digit positive integer. NULL is represented by −.
Then N lines follow, each describes a node in the format:
Address Key Nextwhere Address is the address of the node in memory, Key is an integer in [−], and Next is the address of the next node. It is guaranteed that all the keys are distinct and there is no cycle in the linked list starting from the head node.
Output Specification:
For each test case, the output format is the same as that of the input, where N is the total number of nodes in the list and all the nodes must be sorted order.
Sample Input:
5 00001
11111 100 -1
00001 0 22222
33333 100000 11111
12345 -1 33333
22222 1000 12345Sample Output:
5 12345
12345 -1 00001
00001 0 11111
11111 100 22222
22222 1000 33333
33333 100000 -1#include<cstdio> #include<algorithm> using namespace std; const int maxn = 100010; struct Node{ int address,key,next; bool flag; }node[maxn]; bool cmp(Node a,Node b){ if(a.flag == false || b.flag==false){ return a.flag > b.flag; }else{ return a.key < b.key; } } int main(){ for(int i=0;i<maxn;i++){ node[i].flag = false; } int n,begin; scanf("%d%d",&n,&begin); int address; for(int i=0;i<n;i++){ scanf("%d",&address); scanf("%d %d",&node[address].key,&node[address].next); node[address].address = address; } int p=begin,count = 0; while(p != -1){ node[p].flag = true; count++; p = node[p].next; } if(count == 0){ printf("0 -1"); }else{ sort(node,node+maxn,cmp); printf("%d %05d\n",count,node[0].address); for(int i=0;i<count;i++){ if(i < count-1){ printf("%05d %d %05d\n",node[i].address,node[i].key,node[i+1].address); }else{ printf("%05d %d -1\n",node[i].address,node[i].key); } } } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号