
算法笔记 第6章 C++标准模版库(STL)介绍 学习笔记
6.1 vector的常见用法详解
vector:变长数组,长度根据需要而自动改变的数组
要使用vector,则需要添加vector头文件,即#include<vector>,还需要在头文件下面加上一句“using namespace std;”
1.vector的定义
单独定义一个vector
vector<typename> name;
typename可以是任何基本类型,例如int,double,char,结构体等,也可以是STL标准容器,例如vector、set、queue等。
如果typename也是一个STL容器,定义的时候要记得在>>符号之间加上空格。
vector数组的定义方法:vector<typename> Arrayname[arraySize];
这样Arrayname[0]~Arrayname[arraySize-1]中每一个都是一个vector容器。
2.vector容器内元素的访问
(1)通过下标访问
vector<typename> vi;
vi[index]
下标是从0到vi.size()-1
(2)通过迭代器访问
vector<typename>::iterator it:
举例:
vector<int>::iterator it;
vector<double>::iterator it;
#include<cstdio> #include<vector> using namespace std; int main(){ vector<int> vi; for(int i=1;i<=5;i++){ vi.push_back(i); } vector<int>::iterator it = vi.begin(); for(int i=0;i<5;i++){ printf("%d ",*(it+i)); } return 0; }
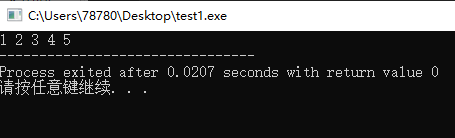
vi[i]和*(vi.begin()+i)是等价的
迭代器还实现了两种自加操作:++it 和 it++
#include<cstdio> #include<vector> using namespace std; int main(){ vector<int> vi; for(int i=1;i<=5;i++){ vi.push_back(i); } for(vector<int>::iterator it = vi.begin();it!=vi.end();it++){ printf("%d ",*it); } return 0; }
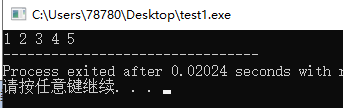
只有vector和string中,才允许使用vi.begin()+3这种迭代器加上整数的写法。
3.vector常用函数实例解析
(1)push_back(x):在vector后面添加一个元素x,时间复杂度为O(1)
(2)pop_back():删除vector的尾元素,时间复杂度为O(1)
(3)size():获得vector中元素的个数,时间复杂度为O(1)
(4)clear():清空vector中的所有元素,时间复杂度为O(N),N为vector中元素的个数
(5)insert():insert(i,x)用来向vector的任意迭代器it处插入一个元素x,时间复杂度O(N)
(6)erase()有两种用法:删除单个元素、删除一个区间内的所有元素。
1、删除单个元素 vi.erase(vi.begin()+3); 删除vi[3]
2、删除一个区间内的所有元素:vi.erase(vi.begin()+1,vi.begin()+4); 删除vi[1]、vi[2]、vi[3]
4.vector的常见用途
(1)储存数据
(2)用邻接表存储图
PAT A1039 Course List for Student
Zhejiang University has 40000 students and provides 2500 courses. Now given the student name lists of all the courses, you are supposed to output the registered course list for each student who comes for a query.
Input Specification:
Each input file contains one test case. For each case, the first line contains 2 positive integers: N (≤), the number of students who look for their course lists, and K (≤), the total number of courses. Then the student name lists are given for the courses (numbered from 1 to K) in the following format: for each course i, first the course index i and the number of registered students Ni (≤) are given in a line. Then in the next line, Ni student names are given. A student name consists of 3 capital English letters plus a one-digit number. Finally the last line contains the N names of students who come for a query. All the names and numbers in a line are separated by a space.
Output Specification:
For each test case, print your results in N lines. Each line corresponds to one student, in the following format: first print the student's name, then the total number of registered courses of that student, and finally the indices of the courses in increasing order. The query results must be printed in the same order as input. All the data in a line must be separated by a space, with no extra space at the end of the line.
Sample Input:
11 5
4 7
BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1
1 4
ANN0 BOB5 JAY9 LOR6
2 7
ANN0 BOB5 FRA8 JAY9 JOE4 KAT3 LOR6
3 1
BOB5
5 9
AMY7 ANN0 BOB5 DON2 FRA8 JAY9 KAT3 LOR6 ZOE1
ZOE1 ANN0 BOB5 JOE4 JAY9 FRA8 DON2 AMY7 KAT3 LOR6 NON9
Sample Output:
ZOE1 2 4 5
ANN0 3 1 2 5
BOB5 5 1 2 3 4 5
JOE4 1 2
JAY9 4 1 2 4 5
FRA8 3 2 4 5
DON2 2 4 5
AMY7 1 5
KAT3 3 2 4 5
LOR6 4 1 2 4 5
NON9 0
#include<cstdio> #include<cstring> #include<vector> #include<algorithm> using namespace std; const int N = 40010; const int M = 26*26*26*10+1; vector<int> selectCourse[M]; int getID(char name[]){ int id = 0; for(int i = 0;i<3;i++){ id = id * 26 + (name[i] - 'A'); } id = id * 10 + (name[3] - '0'); return id; } int main(){ char name[5]; int n,k; scanf("%d%d",&n,&k); for(int i=0;i<k;i++){ int course,x; scanf("%d%d",&course,&x); for(int j = 0;j<x;j++){ scanf("%s",name); int id = getID(name); selectCourse[id].push_back(course); } } for(int i=0;i<n;i++){ scanf("%s",name); int id = getID(name); sort(selectCourse[id].begin(),selectCourse[id].end()); printf("%s %d",name,selectCourse[id].size()); for(int j=0;j<selectCourse[id].size();j++){ printf(" %d",selectCourse[id][j]); } printf("\n"); } return 0; }
6.2 set的常见用法详解
set翻译为集合,是一个内部自动有序且不含重复元素的容器。加入set后可以实现自动排序,因此熟练使用set可以在做某些题时减少思维量。
使用set需要添加set头文件,即#include<set> 还需要在头文件下面加上一句:using namespace std;
1.set的定义
单独定义一个set:
set<typename> name;
例子:set<int> name; set<double> name; set<char> name;
2.set容器内元素的访问
set只能通过迭代器访问:
set<typename>::iterator it;
举例:
set<char>::iterator it;
set<int>::iterator it;
#include<stdio.h> #include<set> using namespace std; int main(){ set<int> st; st.insert(3); st.insert(5); st.insert(2); st.insert(3); //不支持it<st.end()的写法 for(set<int>::iterator it = st.begin(); it!=st.end(); it++){ printf("%d ",*it); } return 0; }
3.set常用函数实例解析
(1)insert()
insert(x):可将x插入set容器中,并自动递增排序和去重,时间复杂度O(logN)
(2)find():
find(value):返回set中对应值为value的迭代器,时间复杂度为O(logN)
#include<stdio.h> #include<set> using namespace std; int main(){ set<int> st; for(int i=1;i<=3;i++){ st.insert(i); } set<int>::iterator it = st.find(2); printf("%d\n",*it); return 0; }
(3)erase()
1.删除单个元素,删除单个元素有两种方法,st.erase(it)与st.erase(value)
st.erase(it):it为所需要删除元素的迭代器,时间复杂度为O(1)。可以结合find()函数使用
#include<stdio.h> #include<set> using namespace std; int main(){ set<int> st; st.insert(100); st.insert(200); st.insert(100); st.insert(300); st.erase(st.find(100)); st.erase(st.find(200)); for(set<int>::iterator it = st.begin();it!=st.end();it++){ printf("%d\n",*it); } return 0; }
st.erase(value):value为所需要删除元素的值。时间复杂度为O(logN),N为set内的元素个数。
#include<stdio.h> #include<set> using namespace std; int main(){ set<int> st; st.insert(100); st.insert(200); st.erase(100); for(set<int>::iterator it = st.begin();it!=st.end();it++){ printf("%d\n",*it); } return 0; }
2.删除一个区间内的所有元素
st.earse(first,last),删除[first,last)区间内的元素
(4)size()
size()用来获得set内元素的个数,时间复杂度为O(1)
(5)clear()
clear()用来清空set中的元素,复杂度为O(N),其中N为set内元素的个数
3.set的常见用途
set最主要的作用是自动去重并按升序排序
6.3 string的常见用法详解
使用string,需要添加string头文件,即#include<string>,还需要在头文件下面加上一句:"using namespace std;"
1.string的定义
string str;
string的初始化:string str="abcd";
2.string中内容的访问
(1)通过下标访问
for(int i=0;i<str.length();i++){
printf("%c",str[i]);
}
读入和输出整个字符串,只能用cin和cout
cin>>str;
cout<<str;
用printf()输出string,则需要使用c_str()函数,将string类型转换为字符数组进行输出
printf("%s\n",str.c_str());
(2)通过迭代器访问
string::iterator it;
#include<stdio.h> #include<string> using namespace std; int main(){ string str = "abcd"; for(string::iterator it = str.begin();it!=str.end();it++) printf("%c",*it); return 0; }
3.string常用函数实例解析
(1) operator+=
可以将两个string直接拼接起来。
(2) compare operator
j两个string类型可以直接使用==、!=、<、<=、>、 >=比较大小
(3) length()/size()
length()返回string的长度,即存放的字符数
(4)insert()
insert()函数有很多种写法,这里给出几个常用的写法,时间复杂度为O(N)
1 insert(pos,string),在pos号位置插入字符串string
2 insert(it,it2,it3):it为原字符串的欲插入位置,it2和it3为待插入字符串的首尾迭代器,用来表示串[it2,it3)将被插在it的位置上。
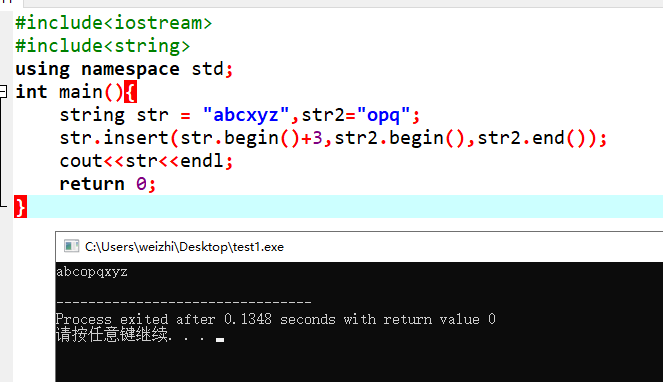
(5)erase():
erase()有两种用法:删除单个元素、删除一个区间内的所有元素。时间复杂度均为O(N)。
1、删除单个元素
str.erase(it):用于删除单个元素,it为需要删除的元素的迭代器。
#include<iostream> #include<string> using namespace std; int main(){ string str = "abcdefg"; str.erase(str.begin()+4); cout<<str<<endl; return 0; }
2、删除一个区间内的所有元素
#include<iostream> #include<string> using namespace std; int main(){ string str = "abcdefg"; str.erase(str.begin()+2,str.end()-1); cout<<str<<endl; return 0; }
(6)clear():用以清空string中的数据,时间复杂度一般为O(1)
(7)substr():substr(pos,len)返回从pos号位开始、长度为len的子串,时间复杂度为O(len)
(8)string::npos,是一个常数,其本身的值为-1
string::npos用以作为find函数失配时的返回值。
(9)find():
str.find(str2),.当str2是str的子串时,返回其在str中第一次出现的位置;如果str2不是str的子串,那么返回string::npos
str.find(str2,pos):从str的pos号位开始匹配str2
#include<iostream> #include<string> using namespace std; int main(){ string str = "Thank you for your smile."; string str2 = "you"; string str3 = "me"; if(str.find(str2) != string::npos){ cout<<str.find(str2)<<endl; } if(str.find(str2,7) !=string::npos){ cout<<str.find(str2,7)<<endl; } if(str.find(str3)!=string::npos){ cout<<str.find(str3)<<endl; }else{ cout<<"I know there is no position for me."<<endl; } return 0; }
(10)replace()
str.replace(pos,len,str2):把str从pos号位开始、长度为len的子串替换为str2
str.replace(it1,it2,str2):把str的迭代器[it1,it2)范围的子串替换为str2
6.4 map的常用用法详解
map可以将任何基本类型(包括STL容器)映射到任何基本类型(包括STL容器)
要使用map,需要添加map头文件,即#include<map>,还需要在头文件下面加上一句using namespace std;
1.map的定义
map<typename1,typename2> mp;
第一个是键的类型,第二个是值的类型
map<string,int> mp;
如果是字符串到整型的映射,必须使用string而不能使用char数组。
2.map容器内元素的访问
(1)通过下标访问
#include<stdio.h> #include<map> using namespace std; int main(){ map<char,int> mp; mp['c'] = 20; mp['c'] = 30; printf("%d\n",mp['c']); return 0; }
(2)通过迭代器访问
map<typename1,typename2>::iterator it;
map可以使用It->first来访问键,使用it->second来访问值

map会以键从小到大的顺序自动排序,这是由于map内部是使用红黑树实现的。
3.map常用函数实例解析
(1)find()
find(key)返回键为key的映射的迭代器,时间复杂度为O(logN),N为map中映射的个数。
#include<stdio.h> #include<map> using namespace std; int main(){ map<char,int> mp; mp['a'] = 1; mp['b'] = 2; mp['c'] = 3; map<char,int>::iterator it = mp.find('b'); printf("%c %d\n",it->first,it->second); return 0; }
(2)erase()
erase()有两种用法:删除单个元素、删除一个区间内的所有元素
一、删除单个元素
删除单个元素有两种方法:
1、mp.erase(it),it为需要删除的元素的迭代器。时间复杂度为O(1)
#include<stdio.h> #include<map> using namespace std; int main(){ map<char,int> mp; mp['a'] = 1; mp['b'] = 2; mp['c'] = 3; map<char,int>::iterator it = mp.find('b'); mp.erase(it); for(map<char,int>::iterator it=mp.begin();it!=mp.end();it++){ printf("%c %d\n",it->first,it->second); } return 0; }
2、mp.erase(key),key为欲删除的映射的键。时间复杂度为O(logN),N为map
#include<stdio.h> #include<map> using namespace std; int main(){ map<char,int> mp; mp['a'] = 1; mp['b'] = 2; mp['c'] = 3; mp.erase('b'); for(map<char,int>::iterator it=mp.begin();it!=mp.end();it++){ printf("%c %d\n",it->first,it->second); } return 0; }
二、删除一个区间内的所有元素
mp.erase(first,last),左闭右开
#include<stdio.h> #include<map> using namespace std; int main(){ map<char,int> mp; mp['a'] = 1; mp['b'] = 2; mp['c'] = 3; map<char,int>::iterator it = mp.find('b'); mp.erase(it,mp.end()); for(map<char,int>::iterator it=mp.begin();it!=mp.end();it++){ printf("%c %d\n",it->first,it->second); } return 0; }
(3)size()
size()用来获得map中映射的对数,时间复杂度为O(1)
(4)clear()
clear()用来清空map中的所有元素,复杂度为O(N),其中N为map中元素的个数。
6.5 queue的常见用法详解
queue翻译为队列,在STL中主要则是实现了一个先进先出的容器。
1.queue的定义
要使用queue,应先添加头文件#include<queue>,并在头文件下面加上using namespace std;
queue<typename> name;
2.queue容器内元素的访问
在STL中只能通过front()来访问队首元素,或是通过back()来访问队尾元素。
#include<stdio.h> #include<queue> using namespace std; int main(){ queue<int> q; for(int i=1;i<=5;i++){ q.push(i); } printf("%d %d\n",q.front(),q.back()); return 0; }
输出结果:
1 5
3.queue常用函数实例解析
(1)push
push(x)将x进行入队,时间复杂度为O(1).
(2)front()、back()
front()和back()可以分别获得队首元素和队尾元素,时间复杂度为O(1)
(3)pop()
pop()令队首元素出队,时间复杂度为O(1)
#include<stdio.h> #include<queue> using namespace std; int main(){ queue<int> q; for(int i=1;i<=5;i++){ q.push(i); } for(int i=1;i<=3;i++){ q.pop(); } printf("%d\n",q.front()); return 0; }
输出结果:4
(4) empty()
empty()检测queue是否为空,返回true则空,返回false则非空。时间复杂度为O(1)
(5) size()
size()返回queue内元素的个数,时间复杂度为O(1)
6.6 priority_queue的常见用法详解
priority_queue又称为优先队列,其底层是用堆来进行实现的。
在优先队列中,队首元素一定是当前队列中优先级最高的那一个。例如在队列有如下元素,且定义好了优先级:
桃子(优先级3)
梨子(优先级4)
苹果(优先级1)
那么出队的顺序为梨子(4)-->桃子(3)---->苹果(1)
1.priority_queue的定义
要使用优先队列,应先添加头文件#include<queue>,并在头文件下面加上"using namespace std;"
priority_queue<typename> name;
2.priority_queue容器内元素的访问
优先队列只能通过top()函数来访问队首元素(也可以称为堆顶元素),也就是优先级最高的元素。
#include<stdio.h> #include<queue> using namespace std; int main(){ priority_queue<int> q; q.push(3); q.push(4); q.push(1); printf("%d\n",q.top()); return 0; }
3.priority_queue常用函数实例解析
(1)push()
push(x)令x入队,时间复杂度为O(logN)
(2)top()
top()可以获得队首元素(即堆顶元素),时间复杂度为O(1)
(3)pop()
pop()令队首元素出队,时间复杂度为O(logN)
#include<stdio.h> #include<queue> using namespace std; int main(){ priority_queue<int> q; q.push(3); q.push(4); q.push(1); printf("%d\n",q.top()); q.pop(); printf("%d\n",q.top()); return 0; }
(4)empty()
empty()检测优先队列是否为空,返回true则空,返回false则非空。
(5)size()
size()返回优先队列内元素的个数,时间复杂度为O(1).
4.priority_queue内元素优先级的设置
(1)基本数据类型的优先级设置
priority_queue<int> q;
priority_queue<int,vector<int>,less<int> > q;
less<int>表示数字大的优先级越大,而greater<int>表示数字小的优先级越大。
#include<stdio.h> #include<queue> using namespace std; int main(){ priority_queue<int,vector<int>,greater<int> > q; q.push(3); q.push(4); q.push(1); printf("%d\n",q.top()); return 0; }
(2)结构体的优先级设置
建立一个结构体:
struct fruit{
string name;
int price;
};
希望按照水果的价格高的为优先级高,就需要重载小于号"<".
struct fruit{ string name; int price; friend bool operator < (fruit f1,fruit f2){ return f1.price < f2.price; } };
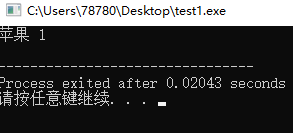
#include<iostream> #include<string> #include<queue> using namespace std; struct fruit{ string name; int price; friend bool operator < (fruit f1,fruit f2){ return f1.price > f2.price; } }f1,f2,f3; int main(){ priority_queue<fruit> q; f1.name = "桃子"; f1.price = 3; f2.name = "梨子"; f2.price = 4; f3.name = "苹果"; f3.price = 1; q.push(f1); q.push(f2); q.push(f3); cout<<q.top().name <<" "<<q.top().price << endl; return 0; }
6.7 stack的常见用法详解
stack翻译为栈,是STL中实现的一个后进先出的容器。
1.stack的定义
要使用stack,应先添加头文件#include<stack>,并在头文件下面加上"using namespace std;"
其定义的写法和其他STL容器相同,typename可以任意基本数据类型或容器
stack<typename> name;
2.stack容器内元素的访问
stack中只能通过top()来访问栈顶元素。
#include<stdio.h> #include<stack> using namespace std; int main(){ stack<int> st; for(int i=1;i<=5;i++){ st.push(i); } printf("%d\n",st.top()); return 0; }
3.stack常用函数实例解析
(1)push()
push(x)将x入栈,时间复杂为O(1)
(2)top()
top()获得栈顶元素,时间复杂度为O(1)
(3)pop()
pop()用以弹出栈顶元素,时间复杂度为O(1)
(4)empty()
empty()可以检测stack是否为空,返回true为空,返回false为非空。
(5)size()
size()返回stack内元素的个数,时间复杂度为O(1)
4.stack的常见用途
stack用来模拟实现一些递归。
6.8 pair的常见用法详解
当想要将两个元素绑在一起作为一个合成元素,又不想要定义结构体时,使用pair可以很方便地作为一个代替品。
1.pair的定义
要使用pair,应先添加头文件#include<utility>,并在头文件下面加上using namespace std;
注意:map的内部实现涉及pair,因此添加map头文件时会自动添加utility头文件,如果需要使用pair就不再需要额外添加utility头文件了。因此,若记不住utility的拼写,可以偷懒使用map头文件来代替。
pair<typeName1,typeName2> name;
临时构建一个pair,有如下两种方法:
①、将类型定义写在前面,后面用小括号内两个元素的方式
pair<string,int>("haha",5)
②、使用自带的make_pair函数
make_pair("haha",5)
2.pair中元素的访问
pair中只有两个元素,分别是first和second.
#include<iostream> #include<utility> #include<string> using namespace std; int main(){ pair<string,int> p; p.first = "haha"; p.second = 5; cout << p.first <<" "<<p.second<<endl; p = make_pair("xixi",55); cout<< p.first <<" "<<p.second<<endl; p = pair<string,int>("heihei",555); cout<<p.first <<" "<<p.second<<endl; return 0; }

3.pair的常见用途
作为map的键值对来进行插入
#include<iostream> #include<string> #include<map> using namespace std; int main(){ map<string,int> mp; mp.insert(make_pair("heihei",5)); mp.insert(pair<string,int>("haha",10)); for(map<string,int>::iterator it = mp.begin();it!=mp.end();it++){ cout << it->first <<" "<<it->second<<endl; } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号