
MySQL(表相关操作)
一 存储引擎
日常生活中文件格式有很多,并且针对不同的文件格式会有对应不同存储方式 和处理机制(txt、word)
针对不同的数据应该有对应的不同的处理机制来存储
存储引擎就是不同的处理机制
MySQL主要存储引擎

-
Innodb
是MySQL5.5版本及之后默认的存储引擎
存储数据更加的安全
-
myisam 是MySQL5.5版本之前默认的存储引擎 速度要比Innodb更快,但是我们更加注重的是数据的安全
-
memory 内存引擎(数据全部存放在内存中)断电数据丢失
-
blackhole 无论存什么,都立刻消失(黑洞)
''' 查看所有的存储引擎 show engines; ''' ''' create table t10(id int) engine=innodb; create table t20(id int) engine=myisam; create table t30(id int) engine=blackhole; create table t40(id int) engine=memory; ''' ''' 存数据 insert into t10 values(1); insert into t20 values(1); insert into t30 values(1); insert into t40 values(1); '''

二 创建表的完整语法
# 语法 create table 表名( 字段名1 类型(宽度) 约束条件, 字段名2 类型(宽度) 约束条件, 字段名3 类型(宽度) 约束条件 ) # 注意 1、在同一张表中字段名不能重复 2、宽度和约束条件是可选(可写可不写)而字段名和字段类型是必须的 约束条件写的话 也支持写多个 字段名1 类型(宽度) 约束条件1 约束条件2..., create table t5(id); 报错 3、最后一行不能有逗号 create table t5( id int, name char ); '''补充''' # 宽度 一般情况下指的是对存储数据的限制 create table t7(name char); 默认宽度是1 insert into t7 values('jason'); insert into t7 values(null); 关键字NULL 针对不同的版本会出现不同的效果 5.6版本默认没有开启严格模式,规定只能存一个字符你给了多个字符,那么我会自动帮你截取 5.7版本及以上或者开启了严格模式,那么规定只能存几个,就不能超,一旦超出范围立刻报错 data too long for '''严格模式到底开不开?''' MySQL5.7之后的版本默认都是开启严格模式的 使用数据库的准则: 能尽量少的让数据库干活就尽量少,不要给数据库增加额外的压力 # 约束条件 null not null 不能插入null create table t8(id int,name char not null); ''' 宽度和约束条件到底是什么关系 宽度是用来限制数据的存储 约束条件是在宽度的基础之上增加的额外的约束 '''
三 严格模式
# 如何查看严格模式 show variables like "%mode"; 模糊匹配/查询 关键值 like %: 匹配任意多个字符 _: 匹配任意单个字符 # 修改严格模式 set session 只在当前窗口有效 set globle 全局有效 set global sql_mode = 'STRICT_TRANS_TABLES'; # 修改完之后,重新进入服务端即可
四 基本数据类型
整型
-
分类
TINYINT SMALLINT MEDUIMINT INT BIGINT
-
作用
存储年龄、等级、id、号码等
![]()
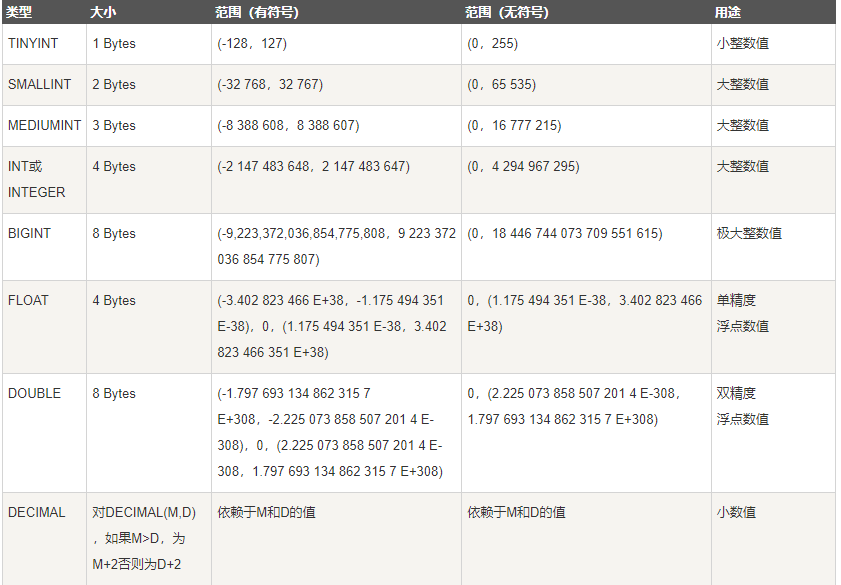
''' 以TINYINT 是否有符号 默认情况下是带符号的 超出会如何 超出限制只存最大可接受值 create table t9(id tinyint); insert into t9 values(-128),(256); ''' # 约束条件值unsigned 无符号 create table t10(id tinyint unsigned); create table t11(id int); # int默认也是带符号的 # 整型默认情况下都是带有符号的 # 针对整型,括号内的宽度到底是干嘛的 create table t12(id int(8)); insert into t12 values(123456789); ''' 特例:只有整型括号里面的数字不是表示限制位数而是显示长度 id int(8) 如果数字没有超出8位,那么默认用空格填充至8位 如果数字超出了8位,那么有几位就存几位(但是还是要遵守最大范围) ''' create table t13(id int(8) unsigned zerofill); # 用0填充至8位 # 总结: 针对整型字段,括号内无需指定宽度,因为它默认的宽度以及足够显示所有的数据了
浮点型
-
分类 FLOAT、DOUBLE、DECIMAL
-
作用 身高、薪资
# 存储限制 float(255,30) 总共255位,小数部分 double(255,30) 总共255位,小数部分 decimal(65,30) 总共65位,小数部分 # 精确度验证 create table t13(id float(255,30)); create table t14(id double(255,30)); create table t15(id decimal(65,30)); float < double < decimal # 精度排序 # 要结合实际应用场景,三者都能使用
字符类型
-
分类
''' char 定长 char(4) 数据超过四个字符直接报错,不够四个字符空格补全 varchar 变长 varchar(4) 数据超过四个字符直接报错,不够有几个存几个 ''' create table t16(name char(4)); create table t17(name varchar(4)); insert into t16 values('a'); insert into t17 values('a'); # 介绍一个小方法char_length统计字段长度 select char_length(name) from t16; select char_length(name) from t17; ''' 首先可以肯定的是char硬盘上存的绝对是真正的数据,带有空格的 但是在显示的时候MySQL会自动将多余的空格剔除 ''' # 再次修改sql_mode 让MySQL不要做自动剔除操作 set global sql_mode='STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH';
char与varchar对比
''' char 缺点:浪费空间 优点:存取都很简单 直接按照固定的字符存取数据即可 jason egon alex wusir 存按照五个字符存,取也直接按照五个字符取 varchar 优点:节省空间 缺点:存取较为麻烦 1Bytes+jason 1Bytes+egon 1Bytes+alex 1Bytes+wusir 存的时候需要制作报头 取的时候也需要先读取报头,之后才能读取真实数据 以前基本上都是用的char,其实现在用varchar的也挺多 ''' 补充: 进公司之后不需要考虑字段类型和字段名,产品经理已指定
日期类型
-
分类 date:年月日 2020-5-4 datetime:年月日时分秒 2020-5-4 11:11:11 time:时分秒11:11:11 Year:2020
create table student( id int, name varchar(16), born_year year, birth date, study_time time, reg_time datetime ); insert into student values(1,'egon','2010','2010-11-11','11:11:11','2010-11-11 11:11:11');
枚举与集合类型
-
分类
''' 枚举(enum) 多选一 集合(set) 多选多 ''
-
具体使用
create table user( id int, name char(16), gender enum('male','female','others') ); insert into user values(1,'json','male'); # 正常 insert into user values(1,'egon','xxxx'); # 报错 # 枚举字段,后期在存数据的时候只能从枚举里面选择一个存储 create table teacher( id int, name char(16), gender enum('male','female','others'), hobby set('read','run','summing','sleep') ); insert into teacher values(1,'jason','male','run'); insert into teacher values(2,'egon','female','run,sleep'); insert into teacher values(3,'alex','other','哈哈'); # 报错 # 集合可以只写一个,但是不能写没有列举的
总结
字段类型 严格模式 约束条件 not null zerofill unsigned
五 约束条件
default默认值
# 补充知识点,插入数据的时候可以指定字段 create table t1( id int, name char(16) ); insert into t1(name,id) values('lq',1); create table t2( id int, name char(16), gender enum('male','female','other') default 'male' ); insert into t2(id,name) values(1,'jason'); insert into t2 values(2,'egon','female');
unique唯一
# 单列唯一 create table t3( id int unique, name char(16) ); insert into t3 values(1,'lq'),(1,'xiaobao'); # 报错 insert into t3 values(1,'zd'); # 联合唯一 ''' Ip 和 port 单个都可以重复,但是加载一起必须是唯一的 ''' create table t4( id int, ip char(16), port int, unique(ip,port) ); insert into t4 values(1,'127.0.0.1',8080); insert into t4 values(2,'127.0.0.1',8081); insert into t4 values(1,'127.0.0.1',8081); # 报错,需联合唯一
primary key主键
''' 1、从约束条件效果上来看primary key等价于not null + unique 非空且唯一!!! ''' create table t5(id int primary key); insert into t5 values(null); # 报错 insert into t5 values(1),(1); # 报错 ''' 2、它除了有约束效果之外,它还是Innodb存储引擎组织数据的依据 Innodb存储引擎在创建表的时候必须要有primary key 因为它类似于书的目录,能够帮助提示查询效率并且也是建表的依据 ''' # 1)一张表中有且只有一个主键,如果你没有设置主键,那么会从上往下搜索直到遇到一个非空且唯一的字段将它自动升级为主键 create table t6( id int, name char(16), age int not null unique, addr char(32) not null unique ); # 2) 如果表中没有主键也没有其他任何的非空且唯一字段,那么Innodb会采用自己内部提供的一个隐藏字段作为主键,隐藏意味着你无法使用它,就无法提升查询速度 # 3) 一张表中通常都应该有一个主键字段,并且通常将id/uid/sid字段作为主键 # 单个字段主键 create table t5( id int primary key, name char(16) ); # 联合主键(多个字段联合起来作为表的主键,本质还是一个主键)
create table service( ip varchar(15), port char(5), service_name varchar(10) not null, primary key(ip,port) ); mysql> desc service; +--------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-------------+------+-----+---------+-------+ | ip | varchar(15) | NO | PRI | NULL | | | port | char(5) | NO | PRI | NULL | | | service_name | varchar(10) | NO | | NULL | | +--------------+-------------+------+-----+---------+-------+
''' 也意味着,以后在创建表的时候id字段一定要加primary key '''
auto_increment自增
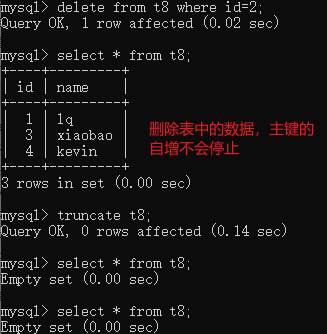
# 当编号特别多的时候,人为的去维护太繁琐 create table t8( id int primary key auto_increment, name char(16) ); insert into t8(name) values('lq'),('zd'),('xiaobao'),('kevin'); # 注意auto_increment通常都是加在主键上的,不能给普通字段加 create table t8( id int primary key auto_increment, name char(16); cid int auto_increment ); # 报错 ''' 结论 以后在创建表的id(数据的唯一标识id、uid、sid)字段的时候 id int primary key auto_increment ''' # 补充 delete from 在删除表中数据的时候,主键的自增不会停止 truncate t1 清空表数据并且重置主键
六 表与表之间建关系(约束)
''' 定义一张员工表,表中有很多字段 id name gender dep_name dep_desc 1、该表的组织结构不是很清晰(可忽视) 2、浪费硬盘空间(可忽视) 3、数据的扩展性极差(无法忽视的) ''' # 如何优化? '''上述问题就类似于你将所有的代码都写在了一个py文件中''' '''将员工表拆分成员工表和部门表'''
外键
''' 外键就是用来帮助我们建立表与表之间关系的 foreign key '''
表关系
''' 表与表之间最多只有四种关系 一对多关系 多对多关系 一对一关系 没有关系 '''
一对多关系
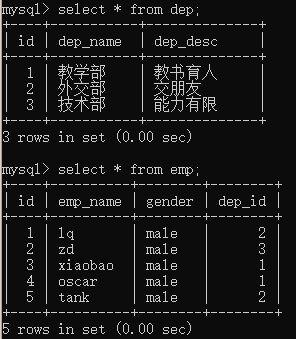
''' 判断表与表之间关系的时候,换位思考,分别站在两张表的角度考虑 两张表考虑完后,才能得出结论 员工表与部门表为例 先站在员工表 思考一个员工能否对应多个部门(一条员工数据能否对应多条部门数据) 不能!!!(不能直接得出结论,一定要两张表考略完全) 再站在部门表 思考一个部门能否对应多个员工(一个部门数据能否对应多条员工数据) 能!!! 得出结论: 员工表与部门表单向的一对多 所以表关系就是一对多 ''' foreign key 1、一对多表关系,外键字段建在多的一方(建在员工表) 2、在创建表的时候,一定要先建被关联表(先建部门表) 3、在录入数据的时候,也必须先录入被关联表(先录入部门表) # SQL语句建立表关系 create table dep( id int primary key auto_increment, dep_name char(16), dep_desc char(32) ); create table emp( id int primary key auto_increment, emp_name char(16), gender enum('male','female','other') default 'male', dep_id int, foreign key(dep_id) references dep(id) ); insert into dep(dep_name,dep_desc) values('教学部','教书育人'),('外交部','交朋友') ,('技术部','能力有限'); insert into emp(emp_name,dep_id) values('lq',2),('zd',3),('xiaobao',1); insert into emp(emp_name,dep_id) values('oscar',1),('tank',2);
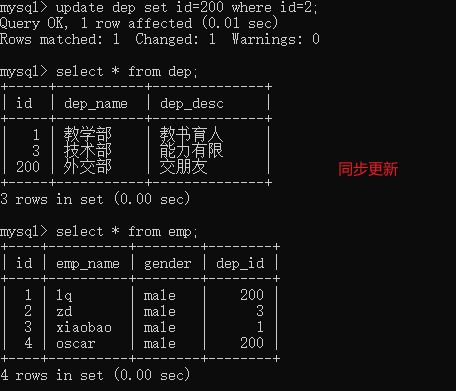
# 修改dep表里面的id字段 update dep set id=200 where id=2; # 报错 # 删除dep表里面的数据 delete from dep; # 报错 # 1、先删除教学部对应的员工数据,之后再删除部门 操作太过繁琐 # 2、真正做到数据之间有关系 更新就同步更新 删除就同步删除 ''' 1) 级联更新 2) 级联删除 ''' create table dep( id int primary key auto_increment, dep_name char(16), dep_desc char(32) ); create table emp( id int primary key auto_increment, emp_name char(16), gender enum('male','female','other') default 'male', dep_id int, foreign key(dep_id) references dep(id) on update cascade # 同步更新 on delete cascade # 同步删除 ); insert into dep(dep_name,dep_desc) values('教学部','教书育人'),('外交部','交朋友') ,('技术部','能力有限'); insert into emp(emp_name,dep_id) values('lq',2),('zd',3),('xiaobao',1),('oscar',2); update dep set id=200 where id=2; # 同步更新 delete from dep where id=200; # 同步删除
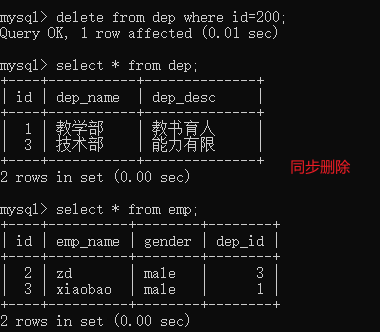
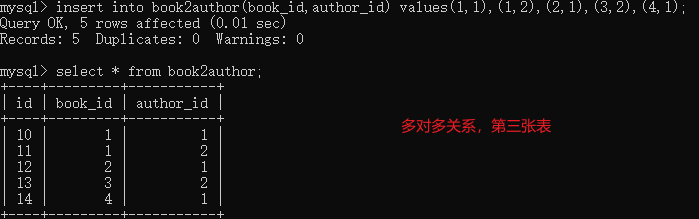
多对多
# 例:图书表和作者表 create table book( id int primary key auto_increment, title varchar(32), price int, author_id int, foreign key(author_id) references author(id) on update cascade on delete cascade ); # 报错 create table author( id int primary key auto_increment, name varchar(32), age int, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade ); # 报错 ''' 按照上述的方式创建,一个都不能成功 针对多对多字段表关系,不能在两张原有的表中创建外键 需要你单独再开设一张,专门用来存储两张表数据之间的关系 原两张表,分别对应第三张表,是一对多的关系 ''' create table book( id int primary key auto_increment, title varchar(32), price int ); create table author( id int primary key auto_increment, name varchar(32), age int ); create table book2author( id int primary key auto_increment, book_id int, author_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade ); insert into book(title,price) values('前端',122),('python',200),('java',100),('php',111); insert into author(name,age) values('lq',18),('xiaobao',9); insert into book2author(book_id,author_id) values(1,1),(1,2),(2,1),(3,2),(4,1);
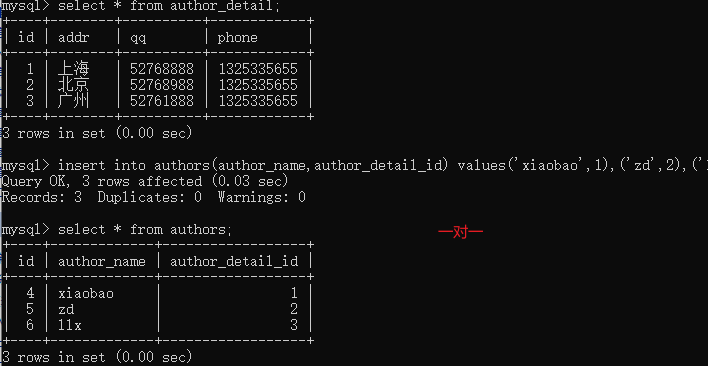
一对一
''' id name age addr hobby phone email 如果一个表的字段特别多,每次查询又不是所有的字段都能用得上 ''' 将表一分为二 用户表 用户表 id name age 用户详细表 id addr phone hobby email 站在用户表 一个用户能否对应多个用户详细 不能 站在详细表 一个详细表能否属于多个用户 不能 结论:单向的一对多都不成立,那么这个时候两者之间的表关系 就是一对一 或者没有关系 ''' 一对一,外键字段建在任意一方都可以,但是推荐建在查询频率比较高的表中 记得加上unique ''' 例: create table author_detail( id int primary key auto_increment, addr varchar(20) not null, qq varchar(10) not null, phone char(16) not null ); create table authors( id int primary key auto_increment, author_name varchar(20) not null, author_detail_id int unique, #该字段一定要是唯一的 foreign key(author_detail_id) references author_detail(id) #外键的字段一定要保证unique on delete cascade on update cascade );
# 增加作者详情(先添加)
insert into author_detail(addr,qq,phone) values('上海','52768888','1325335655'),('北京','52768988','1325335655'),('广州','52761888','1325335655');
# 增加作者 (后添加)
insert into authors(author_name,author_detail_id) values('xiaobao',1),('zd',2),('llx',3);
总结
''' 表关系的建立需要用到foreign key 一对多 外键字段建在多的一方 多对多 自己开设第三张存储 一对一 建在任意一方都可以,但是推荐你建在查询频率较高的表中 ''' ''' 判断表之间关系的方式 换位思考!!! 员工与部门(一对多) 图书与作者(多对多) 作者和作者详细(一对一) '''
'''
表与表之间如果有关系的话,可以有两种建立联系的方式
1.通过外键强制性的建立关系
2.通过sql语句逻辑层面上建立关系
delete from emp where id=1;
delete from dep where id=1;
创建外键会消耗一定的资源,并且增加了表与表之间的耦合度
在实际项目中,如果表特别多,其实可以不做任何外键处理,直接通过sql语句来建立逻辑层面上的关系
到底用不用外键取决于实际项目需求
'''
七 修改表的完整语法大全
# MySQL对大小写是不敏感的 # 修改表名 alter table 表名 rename 新表名; # 增加字段 add table 表名 add 字段名 字段类型(宽度) 约束条件; add table 表名 add 字段名 字段类型(宽度) 约束条件 first; add table 表名 add 字段名 字段类型(宽度) 约束条件 after 字段名; # 删除字段 alter table 表名 drop 字段名; # 修改字段名 alter table 表名 modify 字段名 字段类型(宽带) 约束条件; alter table 表名 change 旧字段名 新字段名 字段类型(宽度) 约束条件;
四 复制表
# sql语句查询的结果其实也是一张虚拟表 create table 表名 select * from 旧表; 不能复制主键、外键等(浅拷贝) create table 表名 select * from 旧表名 where id>3; 附件条件的复制
'''
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号