python高级技术(线程)
一 线程理论
1 有了进程为什么要有线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了:如果把我们上课的过程看成一个进程的话,那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
2 线程的出现
3 进程和线程的关系

4 使用线程的实际场景
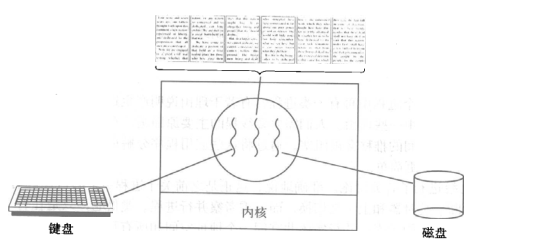
开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
5 内存中的线程
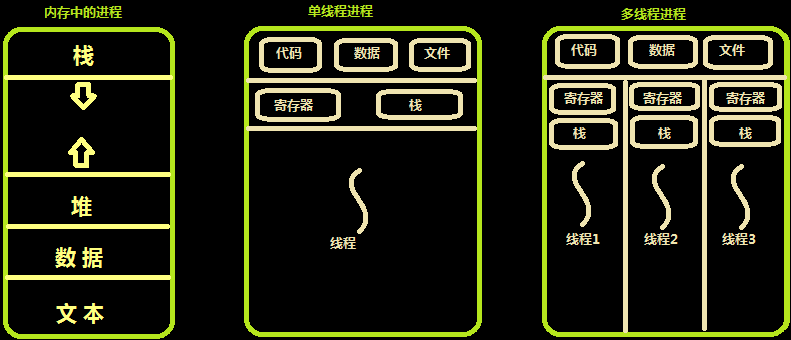
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。
不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程
2. 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢?
因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
什么是线程 进程 :资源单位 线程 :执行单位 将操作系统比喻一个大的工厂 那么进程就相当于工厂里面的车间 而线程就是车间里面的流水线 每一个进程肯定自带一个线程 再次总结: 进程:资源单位(起一个进程仅仅只是在内存空间中开辟一块独立的空间) 线程:执行单位(真正被CPU执行的其实是进程里面的线程,线程指的是代码的执行过程 执行代码中所需要使用到的资源都找所在的进程要) 进程和线程都是虚拟单位,只是为了我们更方便的描述问题 * 为何要有线程 开设进程 1、申请内存空间 耗资源 2、“拷贝代码” 耗资源 开线程 一个进程内可以开设多个线程,在用一个进程内开设多个线程无需再次申请内存空间操作 总结: 开设线程的开销要远远的小于进程的开销 同一个进程下的多个线程数据是共享的!!!
二 开启线程的两种方式
第一种方法
from threading import Thread import time def task(name): print('{} is running'.format(name)) time.sleep(1) print('{} is over'.format(name)) # 开启线程不需要在main下面执行代码 直接书写就可以 # 但是我们还是习惯性的将启动命令写在main下面 t = Thread(target=task, args=('lq',)) t.start() print('主') ''' lq is running 主 lq is over 为什么主不是首先打印,开线程的开销小,几乎代码一执行线程就已经创建了 开启进程,需要申请内存空间,需要时间,代码执行回先继续执行,就会先打印主 '''
第二种方法
from threading import Thread import time class MyThead(Thread): def __init__(self, name): '''针对(__init__)的方法,统一读成 双下init''' # 重写了别人的方法 又不知道别人的方法有啥 你就调用父类的方法 super().__init__() self.name = name def run(self): print('{} is running'.format(self.name)) time.sleep(1) print('{} is over'.format(self.name)) if __name__ == '__main__': t = MyThead('LQ') t.start() print('主') ''' LQ is running主 LQ is over '''
三 实现TCP服务端的并发效果
服务端通信循环,整合到一个函数,链接循环一次开设一个线程(进程),
链接池,接待一个客人后,不用在自己去服务,开启线程(进程),安排
其他人服务。
服务端(未考虑粘包的问题):
import socket from multiprocessing import Process from threading import Thread ''' 服务端 1、要有固定的IP和PORT 2、24小时不间断提供服务 3、能够支持并发 ''' server = socket.socket() # 括号内不加参数默认就是TCP协议 server.bind(('127.0.0.1', 8089)) server.listen(5) # 将服务器的代码单独封装成一个函数 # 通信循环封装成一个函数 def task(conn): while True: try: data = conn.recv(1024) # 针对mac linux 客户端断开链接后 if len(data) == 0: break print(data.decode('utf-8')) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() # 链接循环 while True: conn, addr = server.accept() t = Thread(target=task, args=(conn,)) t.start()
客户端:
import socket client = socket.socket() client.connect(('127.0.0.1', 8089)) while True: client.send('hello world'.encode('utf-8')) data = client.recv(1024) print(data.decode('utf-8'))
四 线程对象的join方法
from threading import Thread import time def task(name): print('{} is running'.format(name)) time.sleep(1) print('{} is over'.format(name)) if __name__ == '__main__': t = Thread(target=task, args=('lq',)) t.start() t.join() # 主线程等待子线程运行结束再执行 print('主') ''' lq is running lq is over 主 '''
五 同一进程下多个线程数据共享
from threading import Thread import time money = 100 def task(): global money money = 500 print(money) time.sleep(3) if __name__ == '__main__': t = Thread(target=task) t.start() t.join() print(money) ''' 500 '''
六 线程对象属性及其他方法
from threading import Thread, active_count, current_thread import os, time def task(): print('x', os.getpid()) print('hello world', current_thread().name) time.sleep(1) if __name__ == '__main__': t = Thread(target=task) t1 = Thread(target=task) t.start() t1.start() print('主', active_count()) # 统计当前正在活跃的线程数 print('x', os.getpid()) print('主', current_thread().name) # 获取线程名字 ''' x 10372 hello world Thread-1 x主 10372 3hello world x 10372Thread-2 主 MainThread '''
active_count() 统计当前正在活跃的线程数
current_thread().name 获取线程名字
七 守护线程
from threading import Thread import time def task(name): print('{} is running'.format(name)) time.sleep(1) print('{} is over'.format(name)) if __name__ == '__main__': t = Thread(target=task, args=('lq',)) t.daemon = True t.start() print('主') ''' lq is running主 主线程运行结束后不会立刻结束,会等其他非守护线程结束才会结束 因为主线程的结束意味着所在的进程的结束 '''
主线程运行结束后不会立刻结束,会等其他非守护线程结束才会结束
因为主线程的结束意味着所在的进程的结束
八 线程互斥锁
与进程互斥锁同理,让并发效果变成串行效果,
通过降低效率,来保证数据安全。
from threading import Thread, Lock import time money = 100 mutex = Lock() def task(): global money mutex.acquire() tmp = money time.sleep(0.01) money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): # 启动100个线程 t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money) ''' 0 '''
九 GIL全局解释器锁

1 GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
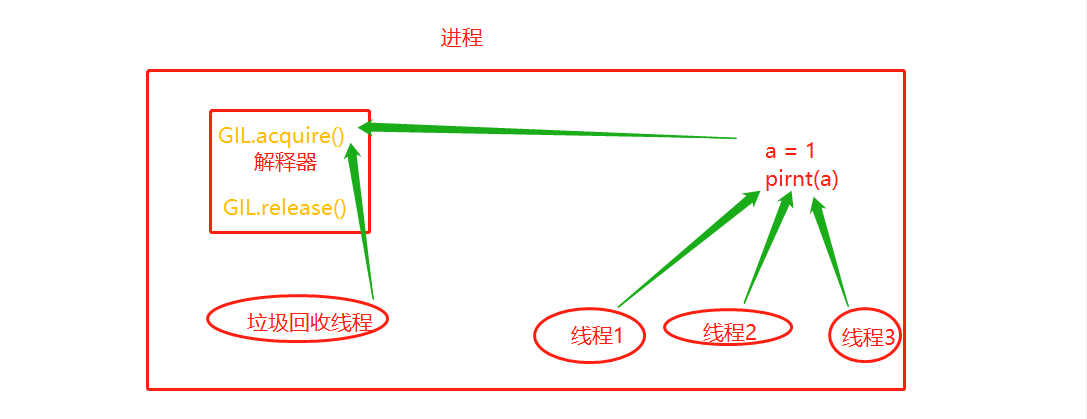
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内。
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
因有垃圾回收机制,就有了垃圾回收线程,保证数据安全,加了GIL锁,导致无法一个进程下多个线程实现多核优势。
2 GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如下图
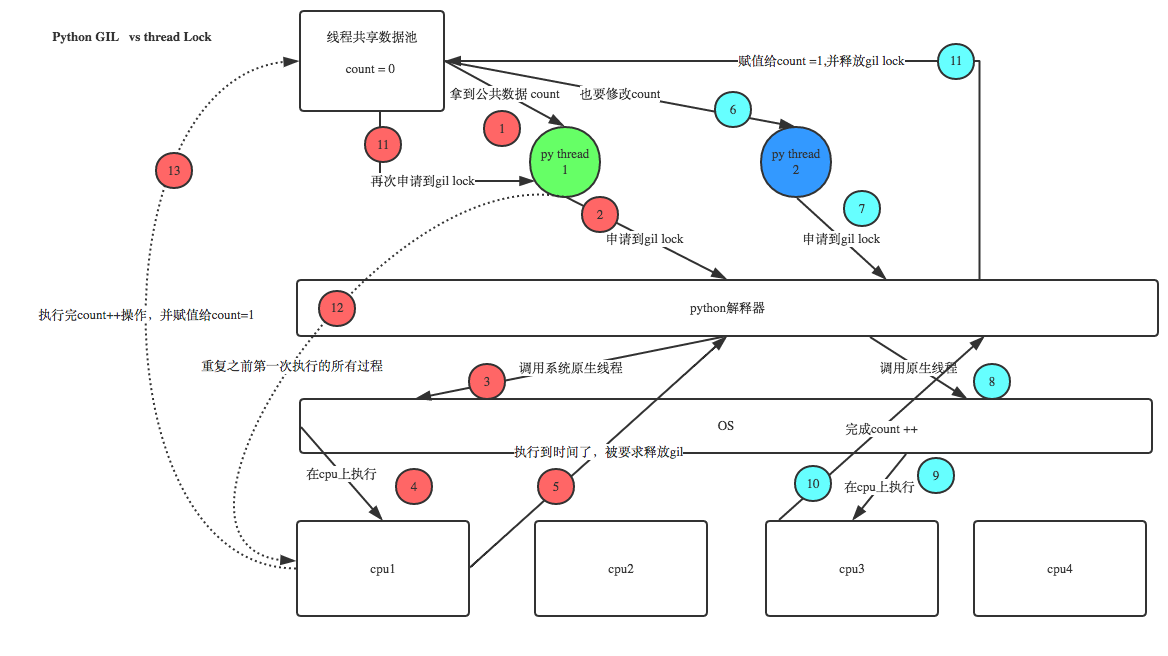
python解释器有多个版本 Cpython Jpython Pypython 但普遍使用的都是Cpython解释器 在Cpython解释器中GIL是一把互斥锁,用来阻止同一个进程下的多个线程的同时执行 同一个进程下的多个线程无法利用多核优势!!! 疑问:python的多线程是不是一点用都没有???无法利用多核优势 因为Cpython中的内存管理不是线程安全的 内存管理(垃圾回收机制) 1.引用计数 2.标记清除 3.分代回收 重点: 1.GIL不是python的特点而是Cpython解释器的特点 2.GIL是保证解释器级别的数据的安全 3.GIL会导致同一个进程下的多个线程的无法同时执行既无法利用多核优势(******) 4.针对不同的数据还是需要加不同的锁处理 5.解释型语言的通病:同一个进程下多个线程无法利用多核优势 # 同一个进程下的多线程无法利用多核优势,是不是就没有用了 *多线程是否有用要看具体情况 单核:四个任务(IO密集型\计算密集型) 多核:四个任务(IO密集型\计算密集型) * 计算密集型 每个任务都需要10S 单核(不用考虑) 多进程:额外的消耗资源 多线程:介绍开销 多核 多进程:总耗时 10 多线程:总耗时 40 * IO密集型 多核 多进程:相对浪费资源 多线程:更加节省资源 * 总结 多进程和多线程都有各自的优势 并且我们后面在写项目的时候通常可以 多进程下面再开设多线程 这样的话既可以利用多核也可以节约资源消耗
应用:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
3 GIL与普通互斥锁的区别
from threading import Thread, Lock import time money = 100 mutex = Lock() def task(): global money mutex.acquire() tmp = money time.sleep(0.1) # 只要进入IO了 GIL会自动释放 money = tmp - 1 mutex.release() if __name__ == '__main__': t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(money) ''' 0 100个线程启动后,先抢GIL sleep时,也就是进入IO,GIL自动释放,但是我手上还有一个自己的互斥锁 其他线程虽然抢到了GIL但是抢不到互斥锁 最终GIL还是回到你的手上,你去操作数据 '''
没有锁的情况下,没有time.sleep,结果是0,是有GIL锁,有了串行效果,加上time.sleep
的IO,GIL会自动释放,结果就是99,没有串行效果,所以在有IO操作的线程中,保证数据安全
还需要加一把字节的锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号