YOLOv3
YOLOv3(You Only Look Once version 3)是一种流行的实时目标检测算法,由Joseph Redmon等人于2018年提出。YOLOv3在YOLOv1和YOLOv2的基础上进行了多项改进,旨在提高检测速度和准确性。
YOLOv3的核心特点:
-
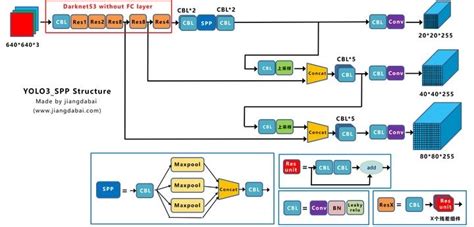
骨干网络:YOLOv3使用Darknet-53作为其骨干网络,这是一种深度卷积神经网络,具有残差结构以防止梯度消失问题,并且通过步长卷积替代了全池化层。

-
多尺度检测:YOLOv3在三个不同的尺度上进行目标检测,分别对应于输入图像的8倍、16倍和32倍下采样特征图。这种设计使得YOLOv3能够同时检测大、中、小尺寸的目标。
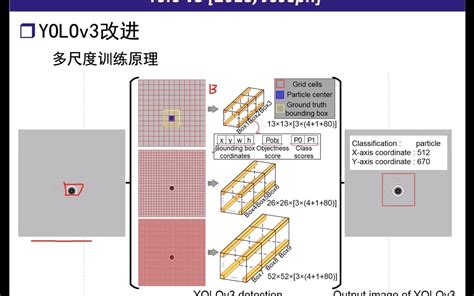
-
特征金字塔:YOLOv3引入了特征金字塔结构,将不同尺度的特征图进行融合,从而提高了检测精度。
-
损失函数优化:YOLOv3使用了改进的损失函数,包括类别损失、定位损失和置信度损失,以提高模型的鲁棒性和准确性。

-
速度与精度的平衡:YOLOv3在速度和精度之间取得了良好的平衡。在320x320分辨率下,YOLOv3可以在22毫秒内运行,并达到28.2 mAP的性能,这比SSD快三倍。
-
锚框机制:YOLOv3使用预定义的锚框来预测目标的位置,每个网格单元会生成多个锚框,并通过IoU(交并比)选择最佳边界框。


应用场景:
YOLOv3广泛应用于各种目标检测任务中,包括但不限于:
-
实时监控:用于实时视频分析和目标检测。

-
自动驾驶:用于检测道路上的车辆、行人和其他障碍物。
-
工业检测:用于检测制造过程中的缺陷和异常。
-
安全检测:用于识别隐藏的武器或其他危险物品。
性能改进:
相比于前代模型,YOLOv3在多个数据集上展示了显著的性能提升。例如,在MS COCO数据集上,YOLOv3达到了28.2 mAP,比SSD快三倍,同时保持了较高的准确性。此外,YOLOv3还被广泛应用于小样本训练场景中,通过调整模型参数和优化训练策略,进一步提升了检测效果。
结论:
YOLOv3是一种高效且准确的目标检测算法,通过改进网络结构、引入多尺度检测和特征金字塔等技术,实现了在速度和精度上的良好平衡。它在多个领域得到了广泛应用,并为后续版本如YOLOv4和YOLOv5奠定了基础。
YOLOv3、YOLOv4和YOLOv5在性能上的具体比较如下:
-
速度与精度的综合分析:
- YOLOv5在速度和精度上均优于YOLOv3和YOLOv4。在相同速度下,YOLOv5的精度高于YOLOv3,而YOLOv4的精度则高于YOLOv5。
- 在相同速度下,YOLOv5的表现优于YOLOv3,但YOLOv4在整体性能上优于YOLOv5。
-
模型大小与灵活性:
- YOLOv5提供了四种不同的网络模型(YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x),可以根据需求灵活选择适当的模型。相比之下,YOLOv3只有单一的模型版本。
- YOLOv5s是体积最小、速度最快但精度较低的版本,适合追求速度的应用场景;YOLOv5x则是精度最高但速度最慢的版本。
-
参数数量与推理速度:
- 在相同输入尺寸(640x640)下,YOLOv5的推理速度更快,但其mAP@0.5值略低于YOLOv4。
- YOLOv5使用了一系列优化策略(如模型剪枝、模型裁剪和模型量化)来提升推理速度。
-
技术改进:
- YOLOv4在YOLOv3的基础上引入了CSPDarknet53作为主干网络,并加入了SAM模块和PANet等新技术,显著提升了性能。
- YOLOv5进一步基于YOLOv4进行改进,采用了EfficientNet作为主干网络,并引入了PANet和FPEM等技术,继续提升准确率和速度。
YOLOv5在速度和精度上均优于YOLOv3和YOLOv4,尤其是在相同速度下,YOLOv5的精度表现更佳。然而,在整体性能方面,YOLOv4表现更为出色。
YOLOv3在实时监控和自动驾驶领域的应用案例有哪些?
YOLOv3在实时监控和自动驾驶领域的应用案例非常广泛,具体如下:
实时监控领域
-
智能安防监控:
- YOLOv3可以实时检测监控画面中的异常行为和潜在威胁。例如,在机场、车站等公共场所的监控系统中,YOLOv3能够快速识别出可疑人员和异常车辆,从而提高安全防范能力。
- 在大型商场的监控系统中,YOLOv3通过实时识别盗窃行为,有效减少了盗窃事件的发生率。
-
视频监控:
- YOLOv3被广泛应用于视频监控系统中,用于实时分析监控视频,识别入侵者、车辆或其他目标。
-
无人机目标检测:
- 在无人机领域,YOLOv3可以用于实时检测无人机上的物体,实现高效的目标追踪和监控。
自动驾驶领域
-
道路检测:
- YOLOv3能够实时检测道路上的车辆、行人、交通标志等目标,为自动驾驶系统提供准确的环境信息。例如,当行人过马路时,自动驾驶车辆可以根据YOLOv3检测到的信息及时刹车或避让。
-
交通流量管理:
- 在智能交通领域,YOLOv3可以用于车辆检测、行人检测和交通标志识别等任务,帮助交通管理部门更好地监控交通流量,提高交通安全性。
-
机器人导航:
- YOLOv3还可以帮助机器人识别并避开障碍物,实现自主导航。
YOLOv3在实时监控和自动驾驶领域的应用非常广泛,涵盖了从安防监控到智能交通、从无人机目标检测到机器人导航等多个方面。
YOLOv3的特征金字塔结构是如何工作的,与传统目标检测方法相比有何优势?
YOLOv3的特征金字塔结构(FPN)是一种用于目标检测的网络架构,它通过融合不同尺度的特征图来提高对不同大小目标的检测能力。YOLOv3采用了Darknet-53作为基础网络,并在其中间层加入了多个侧支路径,这些侧支路径将不同尺度的特征图融合在一起,形成一个特征金字塔。这种设计使得YOLOv3能够在不同的尺度上进行目标检测,从而适应多种不同大小的目标检测任务。
具体来说,YOLOv3从Darknet-53的不同位置提取三个特征层,分别为(52,52,256)、(26,26,512)和(13,13,1024),并通过FPN层将这些特征层进行融合,形成特征金字塔。这种多尺度预测的方法不仅提高了对小目标的检测能力,还增强了模型对不同尺寸目标的适应性。
与传统目标检测方法相比,YOLOv3的特征金字塔结构具有以下优势:
- 提高检测精度:通过融合不同尺度的特征图,YOLOv3能够同时检测不同大小的目标,从而提高了检测精度。
- 增强小目标检测能力:YOLOv3特别关注小目标的检测,通过多尺度预测和特征金字塔结构,显著提升了小目标的检测性能。
- 提高检测速度:尽管网络结构复杂,但YOLOv3仍然保持了较高的检测速度,满足实时检测的需求。
- 灵活的多标签检测:YOLOv3使用逻辑回归分类器处理多标签分类问题,能够同时预测多个类别,标注多个检测目标。
YOLOv3在小样本训练场景中的优化策略和效果评估。
YOLOv3在小样本训练场景中的优化策略和效果评估可以从多个方面进行探讨。以下是基于我搜索到的资料的详细分析:
优化策略
-
数据增强与处理:
- 数据增强是提高小样本检测模型鲁棒性的关键方法之一。通过数据增强技术,如随机裁剪、旋转、缩放等操作,可以增加模型对不同视角和尺寸目标的适应能力。
- 对于特定类型的数据集(如红外小目标检测),还可以采用过采样和复制小目标进行增强,以提高模型的泛化能力。
-
锚点(Anchor)调整:
- 使用K-means聚类算法重新计算适合特定目标尺寸的Anchor,可以显著提升检测精度。这种方法特别适用于小目标检测任务,因为它能够更好地匹配不同尺寸的目标。
-
特征图与网络结构优化:
- YOLOv3通过使用高分辨率的特征图来预测小目标,减少小目标被下采样和合并的概率。
- 在网络结构上,可以通过引入注意力机制、修改残差模块等方式来提升模型性能。
-
损失函数优化:
- 在损失函数中对小目标的置信度损失和边界框回归损失赋予更高的权重,以加强对小目标的检测力度。
- 加权Boosting思想也可以用于训练过程中,通过加大负样本惩罚力度,提升正样本的学习效果。
-
超参数调优:
- 批量大小、学习率和迭代次数等超参数的合理设置对于模型训练的效率和稳定性至关重要。较大的批量大小可以提高训练效率,但可能导致模型不稳定;较小的批量大小则有助于提高模型稳定性。
效果评估
-
检测成功率与精度:
- 在士兵目标检测数据集上,经过优化后的YOLOv3模型实现了85.6%的目标检测成功率,平均精度(mAP)达到82.18%,显示出良好的检测效果。
-
实时性能:
- 在GPU和Xavier上进行测试时,YOLOv3模型在士兵目标检测数据集上的推理速度分别为54.6和26.8帧每秒,表现出较好的实时性能。
-
多场景应用:
- YOLOv3在多个行业中的广泛应用表明其在保持高速运行的同时,检测性能也得到了显著提升。
结论
YOLOv3在小样本训练场景中的优化策略主要包括数据增强、锚点调整、特征图与网络结构优化、损失函数优化以及超参数调优。这些策略不仅提高了模型的检测精度和鲁棒性,还确保了模型在实际应用中的高效性和实时性。
YOLOv3的损失函数优化细节是什么,与前代模型相比有哪些改进?
YOLOv3的损失函数优化细节主要体现在以下几个方面:
-
损失函数的改进:
- YOLOv3将YOLOv2中的softmax损失替换为多个独立的逻辑回归损失(logistic loss),以提高预测精度。
- 去除了前12800次迭代中对Anchor的回归损失的训练限制,简化了训练过程。
- 新增了ignore threshold参数,用于忽略与GT box IOU大于设定阈值的预测框的objectness损失,减少无效信息的计算。
- 在目标框回归过程中加入了GIoU、DIoU、CIOU等损失,以及在分类过程中加入了Focal Loss,以适应不同数据集和任务需求。
-
损失函数的具体构成:
- YOLOv3的损失函数由四个部分组成:边界框位置损失、边界框置信度损失、类别损失和总损失。
- 边界框位置损失使用平方差(L2)损失衡量预测框与真实框之间的差异。
- 边界框置信度损失使用逻辑回归损失(二元交叉熵)衡量预测框是否包含目标物体的置信度。
- 类别损失同样使用二元交叉熵损失。
- 总损失是各部分损失的加权和,通过最小化总损失,模型可以提高对目标物体的检测和识别能力。
-
多尺度预测策略:
- YOLOv3采用了多尺度预测策略,每个尺度预测3个边界框,并且分类器采用二元交叉熵损失,不使用softmax。
- 多尺度预测提高了模型对不同尺寸目标的检测能力。
-
其他改进:
- YOLOv3对非极大值抑制(NMS)算法进行了优化,提高了目标检测的精度和效率。
- 网络结构方面,YOLOv3采用了Darknet-53作为基础网络,并进行了改进,如增加卷积数量,使用3×3和1×1卷积层。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号