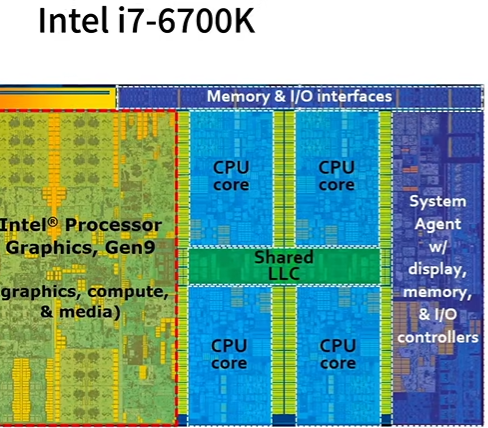
CPU和GPU
CPU
提升CPU利用率1
- 在计算\(a + b\)之前,需要准备数据
-
- 主内存->L3缓存->L2缓存->L1缓存->CPU寄存器
- L1访问延时:0.5ns
- L2访问延时:7ns(\(14\times L1访问延时\))
- L3访问延时:100ns(\(200\times L2访问延时\))
- 提升空间和时间的内存本地性
- 时间:重用数据使得保持它们在缓存里
- 空间:减少读写数据使得可以预读取
样例分析
- 如果一个矩阵是按行存储,访问一行会比访问一列要快
- CPU一次读取64字节(缓存线)
- CPU会“聪明地”提前读取下一个缓存线
提升CPU利用率2
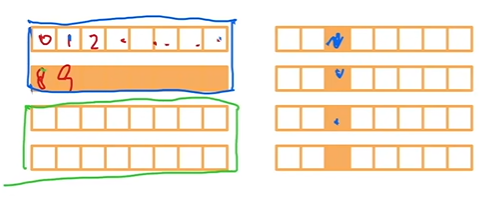
- 高端CPU有几十个核
- EC2 P3.16xlarge:2 Intel Xeon CPUs, 32 物理核
- 并行来利用所有核
- 超线程不一定提升性能,因为它们共享寄存器
样例分析
- 上面比下面慢
for i in range(len(a)):
c[i] = a[i] + b[i]
c = a + b
- 上面调用了
len(a)次+操作,而下面只调用了一次 - 右边很容易并行(例如下面的C++代码)
#pragma omp for
for (i=0; i<a.size(); i++){
c[i] =a[i] + b[i];
}
GPU

提升GPU利用率1
- 并行
- 使用数千个线程
- 内存本地性
- 缓存更小,架构更加简单
- 少用控制语句
- 支持有限
- 同步开销很大
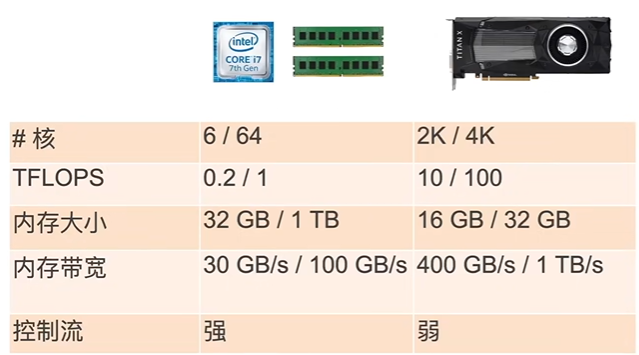
CPU vs GPU
一般/高端
总结
- CPU:可以处理通用计算。性能优化考虑数据读写效率和多线程
- GPU:使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类