填充和步幅(padding and stride)
我们都知道图像在经过卷积处理后,输出图像的尺寸一般会变小,假设输入图像尺寸为\(n_h \times n_w\),卷积核尺寸为\(k_h \times k_w\),经过卷积处理后,输出图像的尺寸为\((n_h-k_h+1)\times (n_w-k_w+1)\)。但是这个过程有个弊端,那就是在经过多个卷积层后,图像的尺寸会变得很小,这里我们做一个假设:假设我们有一张\(240 \times 240\)像素的图片,在经过10层$5\times5 $卷积核的卷积后,输出图像的尺寸为\(200\times 200\),如此一来,原始图片的边缘就丢失了很多有用的信息,因此,我们引入了填充的概念。除此之外,我们在卷积时,卷积核时每次滑动一步来处理图像,这样有时会显得效率过低,于是我们引入了步幅(stride)的概念。
填充(padding)
如上所述,在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充:在输入图像的边界填充元素(通常填充元素是0)。 例如,在下中,我们将\(3\times3\)输入填充到\(5 \times 5\),那么它的输出就增加为\(4 \times 4\)。阴影部分是第一个输出元素以及用于输出计算的输入和核张量元素: \(0\times 0 + 0 \times 1 + 0\times 2 + 0\times 3\)。
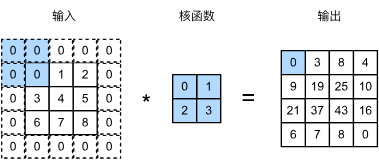
假设我们添加\(p_h\)行填充,\(p_w\)列填充,则输出形状为:
这意味着输出的高度和宽度将分别增加\(p_h\)和\(p_w\)。
在许多情况下,我们需要设置\(p_h=k_h-1\)和\(p_w=k_h-1\),使输入和输出具有相同的高度和宽度。 这样可以在构建网络时更容易地预测每个图层的输出形状。
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7。 选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
对于任何二维张量X,当满足: 1. 卷积核的大小是奇数; 2. 所有边的填充行数和列数相同; 3. 输出与输入具有相同高度和宽度 则可以得出:输出Y[i, j]是通过以输入X[i, j]为中心,与卷积核进行互相关计算得到的。
比如,在下面的例子中,我们创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素。给定高度和宽度为8的输入,则输出的高度和宽度也是8。
import torch
import torch.nn as nn
# 定义一个函数,用于计算卷积操作
def comp_conv2d(conv2d, X):
# 将输入X的形状调整为(1, 1, X的形状)
X = X.reshape((1, 1) + X.shape)
# 对输入X进行卷积操作
Y = conv2d(X)
# 将输出Y的形状调整为(Y的形状[2:],即去掉前两个维度)
return Y.reshape(Y.shape[2:])
# 定义一个卷积层,输入通道数为1,输出通道数为1,卷积核大小为3,padding为1
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1)
# 生成一个8x8的随机数矩阵作为输入
X = torch.rand(8, 8)
# 计算卷积操作的结果,并输出其形状
comp_conv2d(conv2d, X).shape
# 输出
# torch.Size([8, 8])
torch.Size([8, 8])
当卷积核的高度和宽度不同时,我们可以填充不同的高度和宽度,使输出和输入具有相同的高度和宽度。在如下示例中,我们使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1。
# 定义一个卷积层,输入通道数为1,输出通道数为1,卷积核大小为(5, 3),填充大小为(2, 1)
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(5, 3), padding=(2, 1))
# 调用comp_conv2d函数,传入卷积层和输入数据X,输出卷积后的数据形状
comp_conv2d(conv2d, X).shape
torch.Size([8, 8])
步幅(Stride)
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
我们将每次滑动元素的数量称为步幅。到目前为止,我们只使用过高度或宽度为\(1\)的步幅,那么如何使用较大的步幅呢? 下图垂直步幅为\(3\),水平步幅为\(3\)的二维互相关运算。 着色部分是输出元素以及用于输出计算的输入和内核张量元素:\(0\times0 + 0\times1+1\times2+2\times3\)、\(0\times0+6\times1+0\times2+0\times3\)。
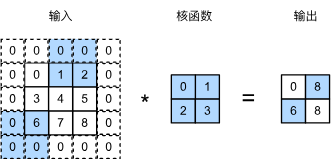
可以看到,为了计算输出中第一列的第二个元素和第一行的第二个元素,卷积窗口分别向下滑动三行和向右滑动两列。但是,当卷积窗口继续向右滑动两列时,没有输出,因为输入元素无法填充窗口(除非我们添加另一列填充)。
通常,当垂直步幅为\(s_h\)、水平步幅为\(s_w\)时,输出形状为:
如果我们设置了\(p_h=k_h-1\)和\(p_w=k_w-1\),则输出形状将简化为\(\lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor\)。 更进一步,如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状将为\((n_h/s_h) \times (n_w/s_w)\)。
下面,我们将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
# 输出
# torch.Size([4, 4])
torch.Size([4, 4])
接下来,再看一个稍微复杂点的例子。
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
torch.Size([2, 2])
为了简洁起见,当输入高度和宽度两侧的填充数量分别为\(p_h\)和\(p_w\)时,我们称之为填充\((p_h, p_w)\)。当\(p_h = p_w = p\)时,填充是\(p\)。同理,当高度和宽度上的步幅分别为\(s_h\)和\(s_w\)时,我们称之为步幅\((s_h, s_w)\)。特别地,当\(s_h = s_w = s\)时,我们称步幅为\(s\)。默认情况下,填充为0,步幅为1。在实践中,我们很少使用不一致的步幅或填充,也就是说,我们通常有\(p_h = p_w\)和\(s_h = s_w\)。
总结
填充的目的是为了减少图像边缘信息的损失,而采用合适步幅的目的是提升图像卷积运算的效率,并降低冗余像素的扫描次数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号