makeMoE_from_Scratch_with_Expert_Capacity文件解读
数据准备
导入必要的包
#导入必要的包并设置种子以实现重现性。
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(42)
#Optional
import mlflow
下载莎士比亚数据集
莎士比亚数据集通常是指包含莎士比亚作品文本的数据集,这些作品涵盖了莎士比亚的所有戏剧、十四行诗和其他诗作。这样的数据集在文学研究、自然语言处理(NLP)和机器学习领域非常有用,具体用途包括:
- 文学研究:学者和研究人员使用这些数据集来分析莎士比亚的语言风格、人物刻画、剧情发展等。
- 自然语言处理:在NLP领域,莎士比亚数据集常被用作训练和测试文本生成模型、语言模型、机器翻译系统等。由于莎士比亚的语言风格独特且具有时代特征,因此这些数据集对于训练模型以理解和生成具有特定风格的语言特别有用。
- 教育和学习:教师和学生可以使用这些数据集来学习莎士比亚的作品,进行文本分析,或者作为写作和戏剧表演的灵感来源。
数据集的特点可能包括:
- 文本格式:通常为纯文本格式,但有时也会提供标注过的版本,如词性标注、句法结构等。
- 语言:主要是早期现代英语,具有特定的拼写和语法结构。
- 完整性:不同的数据集可能包含不同程度的完整性,有的可能包含莎士比亚的全部作品,有的可能只包含部分作品或特定类型的作品。
使用这些数据集时,应考虑到版权问题,确保在使用前获得了适当的许可或确认数据集属于公共领域。在公共领域的数据集通常不受版权限制,可以自由使用。
# Downloading the tiny shakespeare dataset
# !wget https://raw.githubusercontent.com/AviSoori1x/makeMoE/main/input.txt
读取数据集,返回给text文件
# read it in to inspect it
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
创建一个字符到整型的相互映射并定义了一个编码函数和解码函数
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
print(encode("hii there"))
print(decode(encode("hii there")))
# 输出
[46, 47, 47, 1, 58, 46, 43, 56, 43]
hii there
编码整个数据集并保存位torch.Tensor
# let's now encode the entire text dataset and store it into a torch.Tensor
data = torch.tensor(encode(text), dtype=torch.long)
print(data.shape, data.dtype)
print(data[:1000]) # the 1000 characters we looked at earier will to the GPT look like this
将数据集拆分位训练集和验证集
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]
设置并行的独立序列数和最大的文本预测长度
batch_size = 4 # how many independent sequences will we process in parallel?
block_size = 8 # what is the maximum context length for predictions?
生成输入x和目标y的小批量数据
ef get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
return x, y
xb, yb = get_batch('train')
print('inputs:')
print(xb.shape)
print(xb)
print('targets:')
print(yb.shape)
print(yb)
print('----')
for b in range(batch_size): # batch dimension
for t in range(block_size): # time dimension
context = xb[b, :t+1]
target = yb[b,t]
print(f"when input is {context.tolist()} the target: {target}")
# 输出
"""inputs:
torch.Size([4, 8])
tensor([[ 6, 0, 14, 43, 44, 53, 56, 43],
[39, 1, 42, 59, 43, 1, 39, 52],
[47, 41, 43, 1, 39, 52, 42, 1],
[53, 44, 1, 50, 43, 58, 1, 58]])
targets:
torch.Size([4, 8])
tensor([[ 0, 14, 43, 44, 53, 56, 43, 1],
[ 1, 42, 59, 43, 1, 39, 52, 42],
[41, 43, 1, 39, 52, 42, 1, 42],
[44, 1, 50, 43, 58, 1, 58, 46]])
----
when input is [6] the target: 0
when input is [6, 0] the target: 14
when input is [6, 0, 14] the target: 43
when input is [6, 0, 14, 43] the target: 44
when input is [6, 0, 14, 43, 44] the target: 53
when input is [6, 0, 14, 43, 44, 53] the target: 56
when input is [6, 0, 14, 43, 44, 53, 56] the target: 43
when input is [6, 0, 14, 43, 44, 53, 56, 43] the target: 1
when input is [39] the target: 1
when input is [39, 1] the target: 42
when input is [39, 1, 42] the target: 59
when input is [39, 1, 42, 59] the target: 43
when input is [39, 1, 42, 59, 43] the target: 1
when input is [39, 1, 42, 59, 43, 1] the target: 39
when input is [39, 1, 42, 59, 43, 1, 39] the target: 52
when input is [39, 1, 42, 59, 43, 1, 39, 52] the target: 42
when input is [47] the target: 41
when input is [47, 41] the target: 43
when input is [47, 41, 43] the target: 1
when input is [47, 41, 43, 1] the target: 39
when input is [47, 41, 43, 1, 39] the target: 52
when input is [47, 41, 43, 1, 39, 52] the target: 42
when input is [47, 41, 43, 1, 39, 52, 42] the target: 1
when input is [47, 41, 43, 1, 39, 52, 42, 1] the target: 42
when input is [53] the target: 44
when input is [53, 44] the target: 1
when input is [53, 44, 1] the target: 50
when input is [53, 44, 1, 50] the target: 43
when input is [53, 44, 1, 50, 43] the target: 58
when input is [53, 44, 1, 50, 43, 58] the target: 1
when input is [53, 44, 1, 50, 43, 58, 1] the target: 58
when input is [53, 44, 1, 50, 43, 58, 1, 58] the target: 46
"""
多头注意力部分
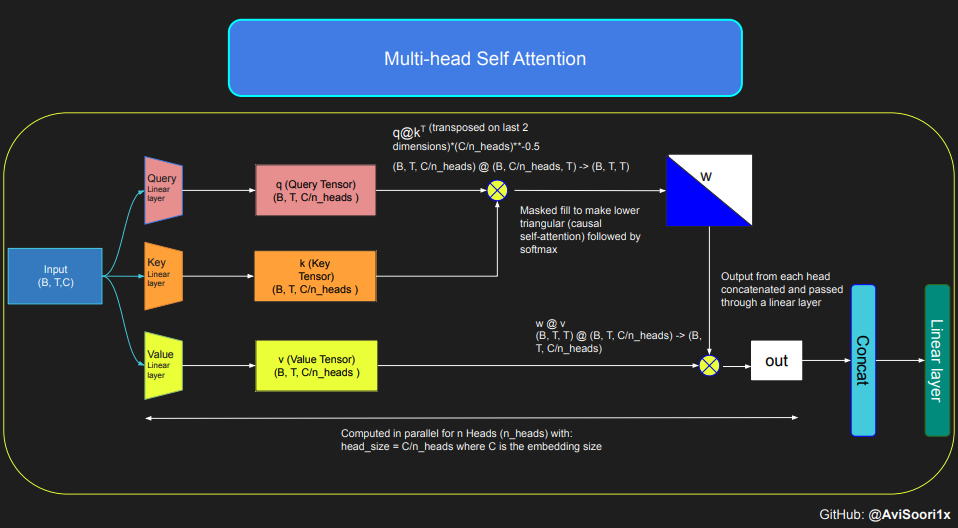
先看一个单头注意力的部分
# 设置随机种子,以确保结果的可复现性
torch.manual_seed(1337)
# 定义维度:批量大小(Batch)、时间步长(Time)、通道数(Channels)
B, T, C = 4, 8, 32 # 分别代表批量大小、时间步长、通道数
# 随机生成一个具有上述维度的张量
x = torch.randn(B, T, C)
# 定义一个头的尺寸(Head size),这是注意力机制中的关键参数
head_size = 16
# 创建线性层来分别生成键(Key)、查询(Query)和值(Value)
key = nn.Linear(C, head_size, bias=False) # 键的线性层,不使用偏置
query = nn.Linear(C, head_size, bias=False) # 查询的线性层,不使用偏置
value = nn.Linear(C, head_size, bias=False) # 值的线性层,不使用偏置
# 使用线性层处理输入x来获取键、查询和值
k = key(x) # (B, T, head_size)
q = query(x) # (B, T, head_size)
# 计算查询和键的点积,这代表了注意力权重
wei = q @ k.transpose(-2, -1) # (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
# 创建一个下三角矩阵,用于后续的掩码操作
tril = torch.tril(torch.ones(T, T))
# 使用掩码矩阵将wei中不需要的部分设置为负无穷
wei = wei.masked_fill(tril == 0, float('-inf'))
# 应用softmax函数来获得归一化的注意力权重
wei = F.softmax(wei, dim=-1) # (B, T, T)
# 使用线性层处理输入x来获取值
v = value(x) # (B, T, head_size)
# 使用注意力权重和值进行矩阵乘法,得到最终的输出
out = wei @ v # (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
# 输出张量的形状
out.shape
多头注意力层
先定义单头类
# 定义模型参数
n_embd = 64 # 嵌入维度
n_head = 4 # 头的数量
n_layer = 4 # 层的数量
head_size = 16 # 每个头的尺寸
dropout = 0.1 # dropout比率
# 定义一个自注意力头(Head)的类
class Head(nn.Module):
""" 自注意力机制的单个头 """
def __init__(self, head_size):
super().__init__()
# 初始化线性层,用于生成键(Key)、查询(Query)和值(Value)
self.key = nn.Linear(n_embd, head_size, bias=False) # 键的线性层
self.query = nn.Linear(n_embd, head_size, bias=False) # 查询的线性层
self.value = nn.Linear(n_embd, head_size, bias=False) # 值的线性层
# 创建一个下三角矩阵,用于后续的掩码操作,确保自注意力是因果的(即未来的信息不会被考虑)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
# 初始化dropout层,用于正则化
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 获取输入张量的形状:批量大小(B)、时间步长(T)、通道数(C)
B, T, C = x.shape
# 使用线性层处理输入x来获取键、查询和值
k = self.key(x) # (B, T, head_size)
q = self.query(x) # (B, T, head_size)
# 计算注意力分数("affinities"),即查询和键的点积,并除以C的平方根进行缩放
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, head_size) @ (B, head_size, T) -> (B, T, T)
# 使用掩码矩阵将wei中不需要的部分设置为负无穷,确保自注意力是因果的
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
# 应用softmax函数来获得归一化的注意力权重
wei = F.softmax(wei, dim=-1) # (B, T, T)
# 应用dropout
wei = self.dropout(wei)
# 使用线性层处理输入x来获取值
v = self.value(x) # (B, T, head_size)
# 使用注意力权重和值进行矩阵乘法,得到最终的输出
out = wei @ v # (B, T, T) @ (B, T, head_size) -> (B, T, head_size)
# 返回输出张量
return out
再定义多头类
# 定义多头自注意力(Multi-Headed Self Attention)的类
class MultiHeadAttention(nn.Module):
""" 并行执行多个自注意力头(Heads) """
def __init__(self, num_heads, head_size):
super().__init__()
# 初始化多个Head实例,每个实例都是一个自注意力头
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
# 初始化一个线性层,用于将所有头的输出合并成一个单一的表示
self.proj = nn.Linear(n_embd, n_embd)
# 初始化dropout层,用于正则化
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 将输入x传递给每个自注意力头,并将所有头的输出在最后一个维度上拼接
out = torch.cat([h(x) for h in self.heads], dim=-1)
# 将拼接后的输出通过线性层处理,然后应用dropout
out = self.dropout(self.proj(out))
# 返回最终的输出张量
return out
确定多头输出是原始输入大小
#Confirming that what's output from multi head attention is the original embedding size
B,T,C = 4,8,64 # batch, time, channels
x = torch.randn(B,T,C)
mha = MultiHeadAttention(4,16)
mha(x).shape
# output
torch.Size([4, 8, 64])
专家模块构建
在稀疏混合专家(MoE)架构中,每个transformer块内的自我注意力机制保持不变。然而,每个块的结构发生了显著的变化:标准前馈神经网络被替换为几个稀疏激活的前馈网络,称为专家。“稀疏激活”是指序列中的每个令牌仅路由到可用总池中有限数量的这些专家——通常是一两个——的过程。这种修改允许对输入数据的不同部分进行专门处理,使模型能够有效地处理更广泛的复杂性。
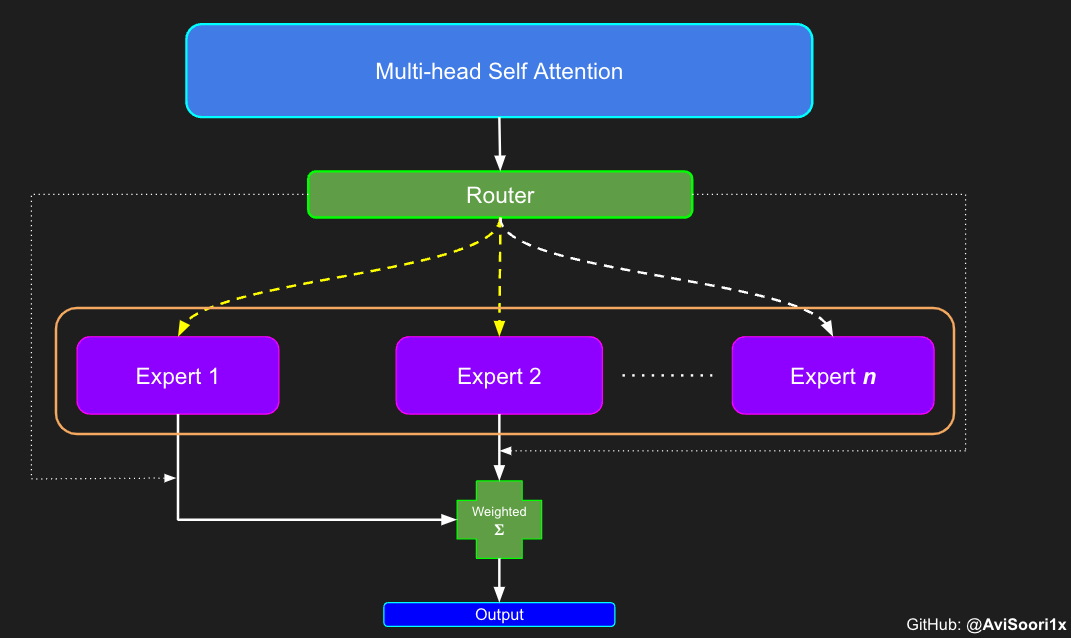
创建一个专家
# 定义专家模块(Expert module)
class Expert(nn.Module):
""" 每个专家是一个简单的多层感知机(MLP),包括线性层和非线性层 """
def __init__(self, n_embd):
super(Expert, self).__init__()
# 初始化一个多层感知机(MLP)网络
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd), # 第一个线性层,输入维度为n_embd,输出维度为4*n_embd
nn.ReLU(), # 应用ReLU非线性激活函数
nn.Linear(4 * n_embd, n_embd), # 第二个线性层,输入维度为4*n_embd,输出维度为n_embd
nn.Dropout(dropout), # 应用dropout正则化,以减少过拟合
)
def forward(self, x):
# 输入x通过MLP网络,并返回输出
return self.net(x)
构建门控网络
门控网络,也称为路由器,决定了从多头关注中接收每个令牌的输出的是哪个专家网络。
让我们考虑一个简单的例子:假设有4个专家,令牌要路由到前2个专家。最初,我们通过线性层将令牌输入门控网络。这一层将输入张量从(2,4,32)的形状——表示(Batch size, Tokens,n_embed,其中n_embed是输入的通道维度)——投射到(2,4,4)的新形状,它对应于(Batch size,Tokens,num_experts),其中num_experts是专家网络的计数。在此之后,我们确定顶部k=2个最高值及其各自沿最后一个维度的指数。
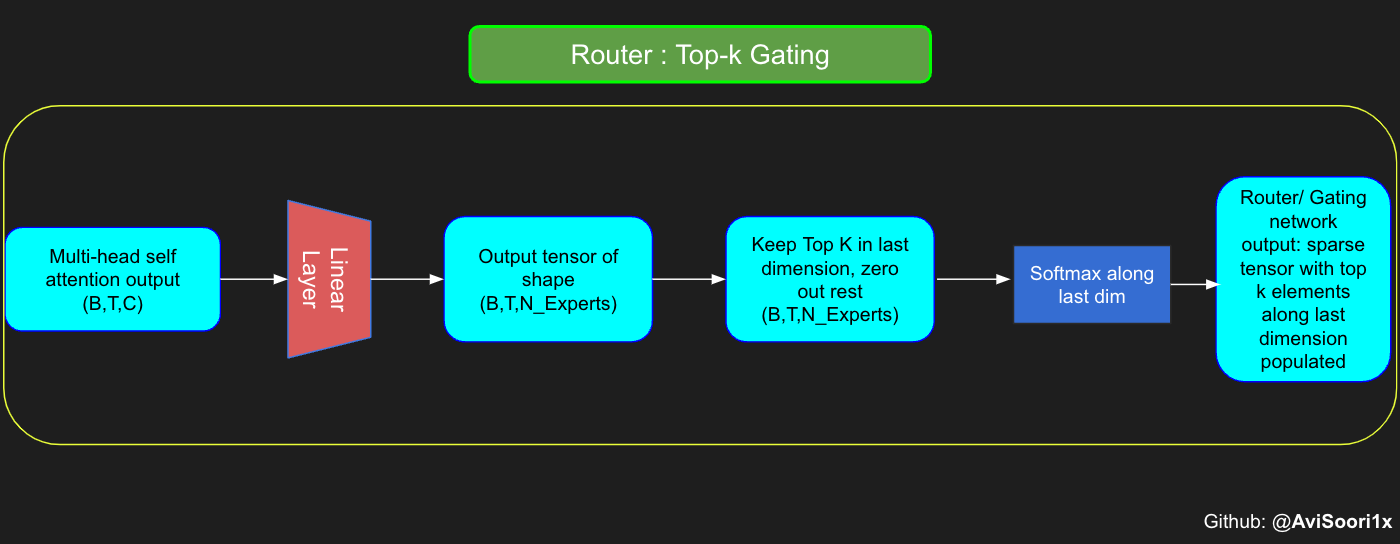
下面是代码演示
# 定义超参数
num_experts = 4 # 专家数量
top_k = 2 # 每个样本将被路由到的前k个专家
n_embed = 32 # 嵌入维度
# 生成一个示例的多头注意力输出
mh_output = torch.randn(2, 4, n_embed) # 考虑n_embed=32, context_length=4和batch_size=2
# 创建一个线性层,用于计算路由权重
topkgate_linear = nn.Linear(n_embed, num_experts) # nn.Linear(32, 4)
# 使用线性层计算每个样本的路由权重
logits = topkgate_linear(mh_ou tput)
# 获取top-k路由权重和对应的专家索引
top_k_logits, top_k_indices = logits.topk(top_k, dim=-1) # Get top-k experts
# 打印top-k路由权重和对应的专家索引
top_k_logits, top_k_indices
# output
"""(tensor([[[0.4110, 0.3834],
[1.2689, 0.4571],
[0.2761, 0.1655],
[0.6160, 0.1792]],
[[0.4101, 0.1542],
[0.2123, 0.1829],
[1.1640, 0.4642],
[0.5413, 0.1986]]], grad_fn=<TopkBackward0>),
tensor([[[2, 0],
[1, 3],
[2, 1],
[1, 2]],
[[3, 2],
[2, 1],
[2, 0],
[3, 0]]]))"""
仅将前k个值沿最后一个维度保留在各自的索引中,即可获得稀疏门控输出。用“-inf”填充其余部分并通过softmax激活。这会将“-inf”值推至零,使前两个值更加突出并求和为1。这种对1的求和有助于专家输出的加权
zeros = torch.full_like(logits, float('-inf')) #full_like clones a tensor and fills it with a specified value (like infinity) for masking or calculations.
sparse_logits = zeros.scatter(-1, top_k_indices, top_k_logits)
sparse_logits
# 定义Top-k路由器模块
class TopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(TopkRouter, self).__init__()
# 初始化参数
self.top_k = top_k # 每个样本将被路由到的前k个专家的数量
self.linear = nn.Linear(n_embed, num_experts) # 初始化一个线性层,用于计算路由权重
def forward(self, mh_output):
# mh_output是从多头自注意力块的输出张量
logits = self.linear(mh_output) # 使用线性层计算每个样本的路由权重
top_k_logits, indices = logits.topk(self.top_k, dim=-1) # 获取每个样本的前k个最大的权重及其对应的专家索引
zeros = torch.full_like(logits, float('-inf')) # 创建一个全为负无穷的张量,用于后续的掩码操作
sparse_logits = zeros.scatter(-1, indices, top_k_logits) # 使用掩码将路由权重中不需要的部分设置为负无穷
router_output = F.softmax(sparse_logits, dim=-1) # 对稀疏化的路由权重应用softmax,得到归一化的路由概率
return router_output, indices # 返回路由概率和选择的专家索引
测试路由网络
#Testing this out:
# 设置参数
num_experts = 4
top_k = 2
n_embd = 32
# 创建一个TopkRouter实例
top_k_gate = TopkRouter(n_embd, num_experts, top_k)
# 生成一个示例输入
mh_output = torch.randn(2, 4, n_embd)
# 使用TopkRouter处理输入
gating_output, indices = top_k_gate(mh_output)
# 返回门控输出的大小、值和选择的专家索引
(gating_output.shape, gating_output, indices)
结果
#And it works!!
# output
"""(torch.Size([2, 4, 4]),
tensor([[[0.0000, 0.6447, 0.3553, 0.0000],
[0.6154, 0.3846, 0.0000, 0.0000],
[0.6815, 0.0000, 0.3185, 0.0000],
[0.0000, 0.0000, 0.6044, 0.3956]],
[[0.0000, 0.7603, 0.0000, 0.2397],
[0.0000, 0.5704, 0.0000, 0.4296],
[0.0000, 0.5422, 0.4578, 0.0000],
[0.6960, 0.0000, 0.3040, 0.0000]]], grad_fn=<SoftmaxBackward0>),
tensor([[[1, 2],
[0, 1],
[0, 2],
[2, 3]],
[[1, 3],
[1, 3],
[1, 2],
[0, 2]]]))"""
Noisy Top-K Gating
文章还介绍了一种高效的门控网络——Noisy Top-K Gating
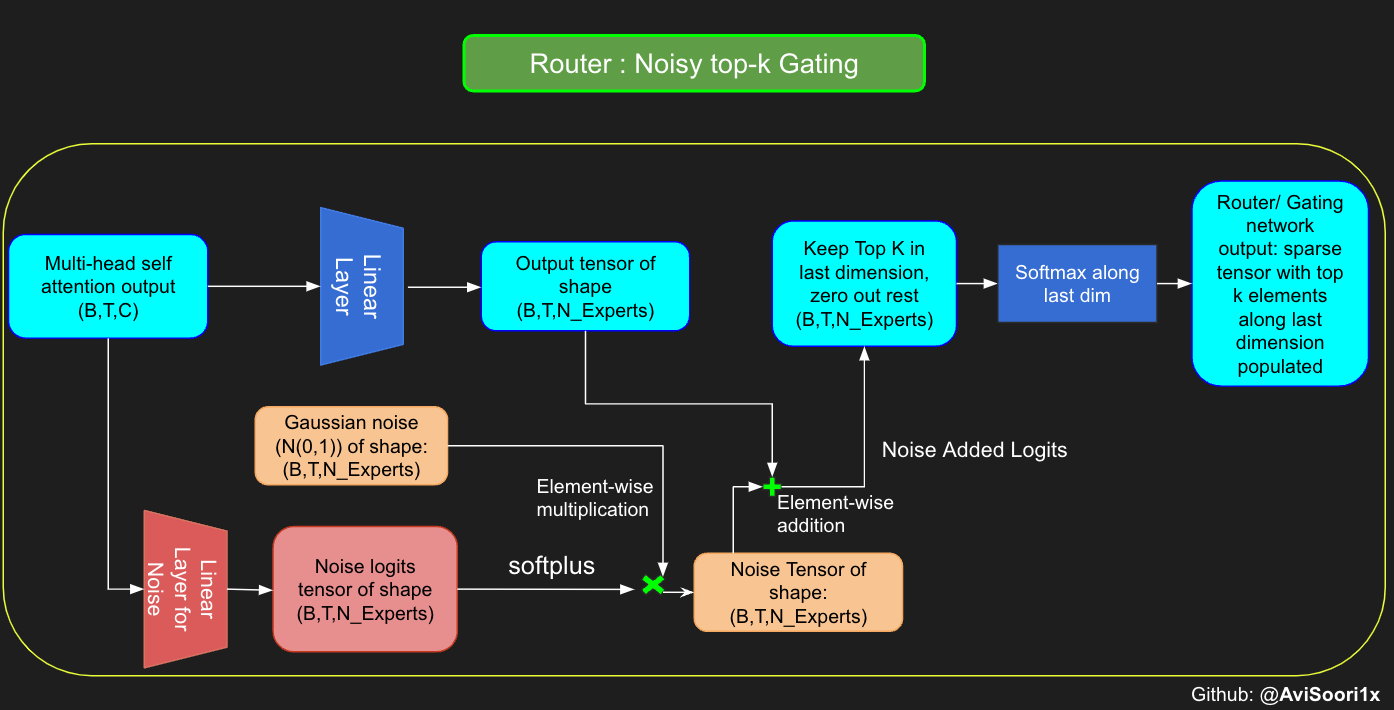
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个NoisyTopkRouter类,用于带噪声的门控机制
class NoisyTopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
# 将top_k设置为类的属性
self.top_k = top_k
# 初始化一个线性层,用于计算路由的logits
self.topkroute_linear = nn.Linear(n_embed, num_experts)
# 初始化另一个线性层,用于计算噪声的logits
self.noise_linear = nn.Linear(n_embed, num_experts)
def forward(self, mh_output):
# mh_output是多头自注意力块的输出张量
logits = self.topkroute_linear(mh_output)
# 计算噪声的logits
noise_logits = self.noise_linear(mh_output)
# 将缩放后的单位高斯噪声添加到logits上
# 使用F.softplus函数对噪声logits进行缩放
noise = torch.randn_like(logits) * F.softplus(noise_logits)
noisy_logits = logits + noise
# 获取top-k的logits和对应的索引
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
# 创建一个与noisy_logits形状相同,填充了负无穷大的张量
zeros = torch.full_like(noisy_logits, float('-inf'))
# 将top-k的logits放置在稀疏张量的正确位置上
# scatter函数将top_k_logits的值放置到indices指定的位置上
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
# 使用softmax函数计算最终的门控输出
router_output = F.softmax(sparse_logits, dim=-1)
# 返回门控输出和选择的专家索引
return router_output, indices
这个网络与原始门控网络的区别在于它添加了一个噪声线性层,它允许模型在路由决策时引入随机性,这有助于提高模型的泛化能力。
创建稀疏混合专家模块
这个过程的主要方面涉及门控网络的输出。在获取这些结果后,对于给定的token,将top k值有选择地与对应top-k专家的输出相乘。这种选择性乘法形成了一个加权求和,构成了SparseMoe块的输出。这个过程的关键和具有挑战性的部分是避免不必要的乘法。只对top_k专家进行前向传播,然后计算这个加权求和是至关重要的。如果为每个专家都执行前向传播,那就失去了使用稀疏MoE的意义,因为这样它就不再稀疏了。
class SparseMoE(nn.Module):
""" 实现稀疏混合专家模型(Sparse MoE) """
def __init__(self, n_embed, num_experts, top_k):
super(SparseMoE, self).__init__()
# 初始化路由器(Router),用于决定输入数据应该路由到哪些专家
# 相当于一个门控网络
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)
# 初始化一组专家,每个专家都是一个Expert模块
self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
# top_k表示每个输入样本将被路由到的前k个专家
self.top_k = top_k
def forward(self, x):
# 路由器计算路由权重和选择的专家索引
gating_output, indices = self.router(x)
# 初始化最终输出张量,其形状与输入相同
final_output = torch.zeros_like(x)
# 将输入和路由权重重塑为二维张量,以便于批量处理
flat_x = x.view(-1, x.size(-1))
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# 并行处理每个专家
for i, expert in enumerate(self.experts):
# 创建一个布尔掩码,表示当前专家是否在top-k内
expert_mask = (indices == i).any(dim=-1)
flat_mask = expert_mask.view(-1)
# 如果有数据需要路由到当前专家
if flat_mask.any():
# 提取需要路由到当前专家的输入数据
expert_input = flat_x[flat_mask]
# 将输入数据传递给专家并获取输出
expert_output = expert(expert_input)
# 提取并应用路由权重
gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)
weighted_output = expert_output * gating_scores
# 通过索引更新最终输出,将专家的加权输出累加到最终输出中
final_output[expert_mask] += weighted_output.squeeze(1)
# 返回最终输出张量
return final_output
测试这个模型
import torch
import torch.nn as nn
# 测试这个模型
num_experts = 8
top_k = 2
n_embd = 16
dropout=0.1
# 生成一个多头注意力的输出示例
mh_output = torch.randn(4, 8, n_embd)
# 创建一个SparseMoE模型实例
sparse_moe = SparseMoE(n_embd, num_experts, top_k)
# 调用模型并获取最终输出
final_output = sparse_moe(mh_output)
# 打印最终输出的形状和内容
final_output_shape = final_output.shape
final_output_content = final_output
final_output_shape, final_output_content
# output
"""Shape of the final output: torch.Size([4, 8, 16])
tensor([[[ 1.3417e-01, 1.1093e-01, -2.4555e-01, 6.8385e-02, -3.8006e-01,
2.3174e-01, 7.6164e-02, -2.1351e-01, -1.4382e-01, 1.1107e-01,
-1.8447e-01, -5.5783e-01, -1.4134e-01, 7.6280e-02, 2.5153e-01,
1.0378e-01],
[ 1.9182e-01, -1.4097e-01, -2.5283e-01, -2.0518e-01, 2.9376e-01,
2.0244e-01, -4.4701e-01, 7.4258e-02, -3.9429e-01, -4.1144e-02,
-5.9280e-02, -8.6293e-02, 1.7004e-01, 1.8310e-01, 3.3961e-01,
1.1057e-01],
[-2.9396e-01, -4.1425e-02, -2.5511e-01, 1.2819e-01, -1.7786e-01,
4.4684e-02, 5.4300e-02, 1.2373e-01, -1.0949e-01, -1.1797e-01,
-6.6932e-02, -2.6615e-01, -1.0273e-01, -1.5250e-01, 2.0982e-01,
-4.0366e-02],
[-9.1636e-02, -1.7490e-01, -3.3946e-01, -1.7884e-01, -3.5593e-01,
-4.5145e-02, -3.2719e-01, -1.1069e-02, -1.8123e-01, 8.8800e-02,
3.3689e-01, 7.5611e-02, -1.1461e-01, 1.1310e-01, 4.3917e-01,
4.3209e-02],
[-4.5912e-01, 2.6964e-01, -2.6610e-01, 1.4078e-02, -3.0743e-02,
2.4254e-01, -3.6379e-02, -5.8787e-02, 1.9660e-01, 3.5932e-02,
-4.5984e-02, -6.7990e-02, -2.9700e-01, 1.4189e-01, -1.8904e-01,
0.0000e+00],
[-5.5832e-03, 1.6764e-01, -1.5194e-01, -1.4429e-01, 1.5916e-01,
4.7208e-02, 1.9909e-01, -1.2204e-02, -2.7100e-01, 1.7786e-02,
5.0073e-02, -1.8628e-01, 4.3945e-02, 1.7625e-01, -7.5076e-02,
-3.3772e-01],
[ 2.0197e-01, -1.7255e-01, -1.3041e-01, -1.5715e-02, -2.6762e-01,
2.5869e-01, -1.3914e-01, -1.3466e-01, 1.8002e-01, -7.5996e-02,
-2.6073e-01, -2.5468e-01, 4.7794e-03, 1.8710e-02, 6.4020e-02,
-1.1411e-02],
[-2.5007e-01, 2.6824e-01, -3.7301e-02, -6.0737e-02, -8.7058e-02,
2.6140e-02, 8.5899e-02, -1.3052e-01, 3.2917e-02, 1.8905e-01,
2.4927e-02, -2.7560e-02, -2.8590e-01, -1.4551e-02, -1.0113e-01,
-6.6401e-02]],
[[-6.3876e-01, -5.3404e-02, -2.6281e-01, -2.0874e-01, 2.3647e-01,
4.9948e-01, -1.3748e-01, -2.3364e-01, 3.6909e-01, -2.2469e-01,
2.0793e-01, 2.7072e-02, -2.3465e-01, 4.6053e-01, -7.6847e-02,
-3.1576e-01],
[ 2.0109e-02, -2.2624e-01, -3.5281e-01, -1.4711e-01, -2.3936e-01,
-1.5849e-02, 3.8982e-01, -5.5862e-02, -1.9366e-01, 3.1780e-01,
2.5695e-02, -6.0848e-02, 2.3440e-01, -1.1256e-01, 6.4279e-02,
0.0000e+00],
[-1.9468e-01, -6.3609e-03, -4.6617e-02, 3.2987e-01, -2.6136e-01,
7.7010e-02, -7.7298e-02, 1.0340e-01, -2.4129e-01, 6.8477e-02,
-4.9273e-02, 2.2779e-02, -2.8955e-01, 1.6193e-01, 1.4783e-01,
-1.5242e-01],
[-8.3669e-02, 5.0233e-03, -2.7716e-01, 2.5612e-01, -2.1062e-02,
2.9610e-02, 6.7794e-03, 1.9538e-01, 2.3352e-03, -4.6025e-02,
-1.8903e-01, -8.4252e-02, -3.0232e-01, -4.4359e-02, -3.9334e-02,
2.1277e-02],
[-8.7852e-02, -1.4372e-02, -1.3006e-01, -1.6036e-02, -2.9728e-01,
-6.1318e-02, 1.1417e-01, -1.0770e-01, -1.7065e-01, -2.8227e-02,
6.7487e-02, -1.3445e-01, -3.0623e-01, -9.8015e-03, 1.1008e-01,
-7.2674e-03],
[-6.6961e-01, 2.4547e-01, -1.6144e-01, -3.1311e-02, -1.2787e-01,
3.8147e-01, -3.2428e-01, 1.5422e-01, -1.9778e-01, -3.2857e-01,
4.7379e-01, -4.5201e-01, -4.3529e-01, 2.9521e-02, 3.3131e-01,
1.0500e-02],
[-1.2021e-01, -3.7174e-02, -1.1262e-01, 2.7953e-02, -9.0682e-02,
6.3620e-02, -1.0968e-01, 3.9663e-01, -3.0556e-01, -1.7335e-01,
5.7721e-02, -8.9344e-02, -4.1475e-02, 2.0201e-02, -2.1026e-01,
1.2182e-01],
[ 3.0891e-01, -7.6200e-03, 2.1607e-02, 0.0000e+00, -2.8166e-01,
4.8711e-01, 3.8212e-01, -2.6218e-01, -2.3246e-01, -4.2424e-01,
-1.6893e-01, -2.9599e-01, -7.0241e-02, 1.1685e-01, 2.6715e-01,
5.5360e-01]],
[[-1.2086e-01, 3.5036e-02, -1.8797e-01, -3.5511e-01, -4.3894e-04,
1.7460e-01, -2.8875e-02, -4.4957e-03, 2.3047e-01, -9.3928e-02,
2.0343e-02, -8.4059e-03, -9.3469e-02, 1.6070e-01, -7.3146e-02,
-1.4924e-01],
[-3.9964e-01, 1.2141e-01, -5.3241e-02, -1.4206e-01, 2.4489e-01,
-2.4503e-01, 2.4453e-01, -1.5968e-02, 1.4466e-01, 3.3879e-01,
1.0346e-01, -1.4529e-01, 2.8582e-01, -3.6586e-01, -7.4564e-02,
-4.0463e-01],
[-3.5863e-01, -5.8021e-02, -1.0369e-01, 1.4175e-01, -1.9414e-02,
-4.8978e-02, -7.9290e-02, 1.1019e-01, -2.2702e-01, 1.9268e-02,
2.6040e-01, -2.4226e-01, 1.0366e-01, 3.6935e-01, -1.6067e-01,
-1.7965e-01],
[-3.5187e-01, 3.4680e-01, 8.0099e-02, -1.0024e-01, 1.3804e-01,
1.6812e-01, -6.0130e-02, 1.0213e-01, -3.9994e-01, 3.6647e-01,
3.3931e-02, -1.7215e-01, -5.5440e-02, 3.2373e-01, -1.0209e-01,
2.9533e-01],
[-7.5817e-02, -8.3176e-02, -1.4078e-01, -1.5924e-01, 2.0016e-02,
1.9500e-01, 1.8137e-02, -7.3472e-02, 1.7299e-02, -1.4620e-01,
-1.6083e-01, -2.2624e-01, 3.7448e-02, 9.1983e-02, -2.2914e-02,
6.3062e-02],
[-2.3772e-01, 1.6915e-01, 8.1636e-02, 7.9889e-02, -8.3822e-03,
-1.0003e-01, 6.9016e-02, 1.2703e-01, -1.3275e-01, 1.5558e-01,
6.0512e-02, -1.1761e-01, -1.0828e-02, -1.1681e-01, -1.5350e-01,
4.8887e-02],
[-1.7649e-01, 5.7851e-02, -1.5014e-01, 3.3823e-01, 3.4926e-02,
1.4101e-01, 5.6636e-02, 2.0626e-01, -4.6374e-02, 8.1023e-02,
6.7515e-02, -3.1627e-02, 8.6018e-02, 2.4232e-02, -4.6138e-03,
-1.3255e-02],
[-6.4531e-02, 1.5574e-01, 1.8362e-01, 5.3845e-02, 6.0622e-02,
1.8494e-01, 5.5855e-03, 7.3159e-02, 3.1028e-01, -7.1398e-02,
3.8218e-02, 3.1418e-02, 7.2016e-02, -7.6856e-02, 1.2827e-02,
4.2569e-02]],
[[ 2.0210e-01, 1.8769e-01, -1.9668e-01, 1.3025e-01, -3.0343e-02,
3.6144e-01, -4.0934e-01, 1.1732e-01, 4.9774e-02, 2.6914e-01,
-2.1882e-01, -1.0531e-01, -1.6489e-01, -3.8289e-01, -3.1870e-02,
9.2205e-02],
[-9.9752e-02, 9.2395e-02, -2.8920e-02, -2.5692e-01, -1.1188e-01,
-1.1143e-01, 1.3397e-02, 5.6234e-02, -1.0555e-01, 9.1558e-02,
-2.3012e-03, -3.2222e-02, 2.4481e-01, -2.8327e-01, 2.1620e-01,
-1.5850e-01],
[ 1.2875e-01, -2.6904e-01, -7.9317e-02, -1.2963e-01, -1.2143e-01,
7.1026e-02, -1.1939e-01, -1.1855e-01, -1.8184e-01, 0.0000e+00,
-1.4198e-02, -3.0389e-01, 6.5546e-02, 9.1086e-02, -9.4632e-02,
1.8618e-01],
[-2.0786e-02, 1.4516e-01, -1.3220e-01, 1.3921e-01, 1.7829e-01,
-1.4111e-02, -3.4633e-01, -4.7371e-02, -4.7787e-02, -1.8962e-01,
-1.9354e-01, -2.4214e-01, 1.1013e-01, -1.9617e-01, 2.5493e-01,
3.4730e-01],
[-5.4845e-01, 2.5084e-01, -1.0371e-01, -6.2493e-02, -3.7305e-02,
1.6065e-01, -1.7192e-01, -6.4060e-02, 4.9870e-03, -6.9887e-02,
-1.5461e-01, 5.9830e-02, -1.9310e-01, 3.0933e-01, 2.9058e-02,
-1.3181e-02],
[ 2.9374e-02, 9.0106e-02, -8.0455e-02, -1.0477e-02, -8.0961e-02,
2.1516e-01, 2.1472e-01, 2.1785e-01, -1.0351e-01, 3.7596e-02,
-1.6474e-01, -2.7524e-01, -5.1199e-02, 1.2154e-01, 3.4960e-01,
-7.3452e-02],
[-2.4363e-01, 1.5423e-01, 1.7253e-01, 5.5599e-02, -3.2306e-01,
-2.2492e-01, -1.3928e-01, -1.2843e-01, -7.6602e-02, 7.1145e-02,
6.7872e-02, -4.5576e-02, -2.1637e-01, 1.9620e-01, 1.7479e-01,
-5.0744e-02],
[-7.6033e-02, -4.9744e-02, -9.0483e-03, -8.7191e-02, -1.7135e-01,
1.3433e-01, 9.9669e-02, -2.3106e-02, -4.5381e-02, -1.6201e-01,
5.6047e-02, -2.6401e-01, -2.2614e-01, 5.3300e-02, 1.8945e-01,
5.8252e-02]]], grad_fn=<IndexPutBackward0>)
"""
引入专家容量(Introducing Expert Capacity)
在预训练混合专家语言模型或任何大型语言模型时,这个过程通常需要跨越多个GPU,并且常常需要多台机器。这些硬件资源上的训练并行化方式对于平衡计算负载至关重要。然而,如果某些专家或一组专家过于受宠——反映出对利用而非探索的偏见——这不仅可能导致模型潜在的性能问题,还可能导致集群中计算负载的不平衡。
Switch Transformer 实现使用了专家容量来规避这个问题。专家容量决定了在训练或推理过程中每个专家负责多少个token。它是根据批次中的token数量和可用的专家数量来定义的,通常通过一个容量因子进行调整。这个因子在分配中提供了灵活性,提供了一个缓冲区来应对数据分布的变化,并确保没有单个专家因为过载而成为瓶颈。在训练这些大型模型数周甚至数月的过程中,硬件故障是常见的,因此这一点非常重要。
以下是通常如何计算专家容量的:
专家容量 = (每批次的token数量 / 专家数量) × 容量因子
其中:
每批次的token数量是需要处理的一个批次中存在的token的总数。
专家数量是MoE层中可用于处理数据的专家的总数。
容量因子是一个乘数,用于调整基本容量(每批次的token数量除以专家数量)。容量因子大于1允许每个专家处理高于均匀分配份额的缓冲区,以适应token分配的不平衡。这个值的一般范围是1-1.25。
以下代码块对实现简单版本的专家容量做了一些调整:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个SparseMoE类,实现稀疏的混合专家模型
class SparseMoE(nn.Module):
def __init__(self, n_embed, num_experts, top_k, capacity_factor=1.0):
super(SparseMoE, self).__init__()
# 初始化门控网络,用于选择专家
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)
# 初始化专家列表,每个专家都是一个Expert网络
self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
# 设置top-k值,表示每个token选择多少个专家
self.top_k = top_k
# 设置容量因子,用于调整每个专家的处理能力
self.capacity_factor = capacity_factor
# 设置专家的总数
self.num_experts = num_experts
def forward(self, x):
# 假设x的形状为[batch_size, seq_len, n_embd]
batch_size, seq_len, _ = x.shape
# 通过门控网络获取门控输出和选择的专家索引
gating_output, indices = self.router(x)
# 初始化最终输出,形状与x相同
final_output = torch.zeros_like(x)
# 将批次和序列维度展平,以便独立处理每个token
flat_x = x.view(-1, x.size(-1)) # 现在形状为[batch_size * seq_len, n_embd]
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# 计算每批次token的总数
tokens_per_batch = batch_size * seq_len * self.top_k
# 计算每个专家的容量
expert_capacity = int((tokens_per_batch / self.num_experts) * self.capacity_factor)
# 初始化用于更新的张量
updates = torch.zeros_like(flat_x)
# 遍历每个专家
for i, expert in enumerate(self.experts):
# 获取选择的专家的mask
expert_mask = (indices == i).any(dim=-1)
# 将mask展平
flat_mask = expert_mask.view(-1)
# 获取选择的索引
selected_indices = torch.nonzero(flat_mask).squeeze(-1)
# 限制选择的索引数量不超过专家的容量
limited_indices = selected_indices[:expert_capacity] if selected_indices.numel() > expert_capacity else selected_indices
# 如果有选择的索引,则处理它们
if limited_indices.numel() > 0:
# 获取专家的输入
expert_input = flat_x[limited_indices]
# 获取专家的输出
expert_output = expert(expert_input)
# 获取门控分数
gating_scores = flat_gating_output[limited_indices, i].unsqueeze(1)
# 计算加权输出
weighted_output = expert_output * gating_scores
# 更新最终输出
updates.index_add_(0, limited_indices, weighted_output)
# 将更新的张量重新整形以匹配x的原始维度
final_output += updates.view(batch_size, seq_len, -1)
# 返回最终输出
return final_output
模型核心代码
import torch
import torch.nn as nn
# 定义一个Transformer块,包含自注意力机制和稀疏混合专家模型(SparseMoE)
class Block(nn.Module):
""" Mixture of Experts Transformer块:先进行通信(自注意力),然后进行计算(稀疏MoE) """
def __init__(self, n_embed, n_head, num_experts, top_k):
# n_embed: 嵌入维度,n_head: 我们想要的头(head)的数量
super().__init__()
# 计算每个头的尺寸
head_size = n_embed // n_head
# 初始化多头自注意力层
self.sa = MultiHeadAttention(n_head, head_size)
# 初始化稀疏混合专家模型层
self.smoe = SparseMoE(n_embed, num_experts, top_k)
# 初始化两个层归一化层,一个用于自注意力之前,一个用于稀疏MoE之前
self.ln1 = nn.LayerNorm(n_embed)
self.ln2 = nn.LayerNorm(n_embed)
def forward(self, x):
# 应用多头自注意力机制,并通过残差连接添加到输入上
x = x + self.sa(self.ln1(x))
# 应用稀疏混合专家模型,并通过残差连接添加到自注意力层的输出上
x = x + self.smoe(self.ln2(x))
# 返回最终的输出
return x
# 定义一个稀疏混合专家语言模型类,结合了嵌入、位置编码、Transformer块和语言模型头
class SparseMoELanguageModel(nn.Module):
def __init__(self):
super().__init__()
# 每个token直接从查找表中读取下一个token的logits
self.token_embedding_table = nn.Embedding(vocab_size, n_embed)
self.position_embedding_table = nn.Embedding(block_size, n_embed)
# 初始化多个Transformer块
self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embed) # 最后的层归一化层
self.lm_head = nn.Linear(n_embed, vocab_size) # 语言模型头
def forward(self, idx, targets=None):
# idx和targets都是(B,T)的张量,其中包含整数
B, T = idx.shape
# 获取token嵌入和位置嵌入
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
# 将token嵌入和位置嵌入相加
x = tok_emb + pos_emb # (B,T,C)
# 应用Transformer块
x = self.blocks(x) # (B,T,C)
# 应用最后的层归一化层
x = self.ln_f(x) # (B,T,C)
# 获取logits
logits = self.lm_head(x) # (B,T,vocab_size)
# 如果targets为None,则没有损失
if targets is None:
loss = None
else:
# 获取logits和targets的形状
B, T, C = logits.shape
# 将logits重塑为(B*T,C)
logits = logits.view(B*T, C)
# 将targets重塑为(B*T)
targets = targets.view(B*T)
# 计算交叉熵损失
loss = F.cross_entropy(logits, targets)
# 返回logits和loss
return logits, loss
def generate(self, idx, max_new_tokens):
# idx是当前上下文中的索引的(B, T)数组
for _ in range(max_new_tokens):
# 裁剪idx到最后一个block_size的tokens
idx_cond = idx[:, -block_size:]
# 获取预测
logits, loss = self(idx_cond)
# 只关注最后一个时间步
logits = logits[:, -1, :] # 变为(B, C)
# 应用softmax以获取概率
probs = F.softmax(logits, dim=-1) # (B, C)
# 从分布中采样
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# 将采样的索引追加到运行序列中
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
# 返回idx
return idx
初始化模型
def kaiming_init_weights(m):
if isinstance (m, (nn.Linear)):
init.kaiming_normal_(m.weight)
model = SparseMoELanguageModel()
model.apply(kaiming_init_weights)
训练模型
# 将模型移动到指定的设备上,例如,如果使用GPU,则设备为'cuda'
m = model.to(device)
# 打印模型中参数的数量,单位为M(百万)
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# 创建一个PyTorch优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 设置MLFlow实验
# mlflow.set_experiment("makeMoE")
# 使用with语句确保MLFlow运行被正确启动和结束
with mlflow.start_run():
# 如果使用mlflow.autolog(),这些参数会自动记录。在这里,我选择显式记录以保证完整性
params = {"batch_size": batch_size, "block_size": block_size, "max_iters": max_iters, "eval_interval": eval_interval,
"learning_rate": learning_rate, "device": device, "eval_iters": eval_iters, "dropout": dropout, "num_experts": num_experts, "top_k": top_k}
mlflow.log_params(params)
for iter in range(max_iters):
# 每隔eval_interval迭代评估一次在训练集和验证集上的损失
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
metrics = {"train_loss": float(losses['train']), "val_loss": float(losses['val'])}
mlflow.log_metrics(metrics, step=iter)
# 采样一个批次的训练数据
xb, yb = get_batch('train')
# 评估损失
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True) # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 应用梯度下降更新权重
测试模型
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))
总结
与传统的transformer模型架构不同的是,MoE架构引入了两个特殊的层——门控层和专家层,这个两个层代替了原有的前馈层——feed forward layer,从而实现了一个从稠密模型到稀疏模型的转变,模型所有的输入在进入多头注意力层后,先回经过门控网络,它会返回前k个较大的路由概率和选择的专家索引,然后选择对应的专家进行输出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号