学会这7种SQL进阶用法,让你少走99%的弯路!
 掌握这几种SQL进阶用法,你将能够更高效地处理各种复杂的数据操作,并少走很多弯路。这些技巧能够提高你的SQL查询能力,使得你在日常的数据处理工作中更得心应手。
掌握这几种SQL进阶用法,你将能够更高效地处理各种复杂的数据操作,并少走很多弯路。这些技巧能够提高你的SQL查询能力,使得你在日常的数据处理工作中更得心应手。
引言
在日常业务开发中,熟练掌握SQL语言是至关重要的。除了基础的增删改查操作外,了解和掌握一些进阶的SQL用法能够让你更高效地处理各种复杂的数据操作。本文将介绍几种SQL进阶用法,让你少走99%的弯路,提高数据处理效率。
自定义排序
在MySQL中,你可以通过使用自定义排序来指定特定字段的排序顺序。通常情况下,MySQL的排序是按照默认的升序(ASC)或降序(DESC)进行的。但是,有时候你可能需要按照特定的顺序进行排序,而不仅仅是升序或降序。这时就可以使用自定义排序。
下面我们来通过一个示例来讲解自定义排序。
假设你有一个students表,其中包含学生的姓名和成绩。现在,你想按照自定义的顺序对学生进行排序,而不是按照成绩的大小。例如,你想按照"A"、"B"、"C"、"D"、"E"这样的顺序进行排序。
在MySql8.0以前我们需要使用ORDER BY结合CASE语句来自定义一个排序规则去实现。例如:
SELECT *
FROM students
ORDER BY
CASE
WHEN grade = 'A' THEN 1
WHEN grade = 'B' THEN 2
WHEN grade = 'C' THEN 3
WHEN grade = 'D' THEN 4
WHEN grade = 'E' THEN 5
ELSE 6 -- 处理其他情况,例如如果有其他成绩值
END;
执行结果如下:
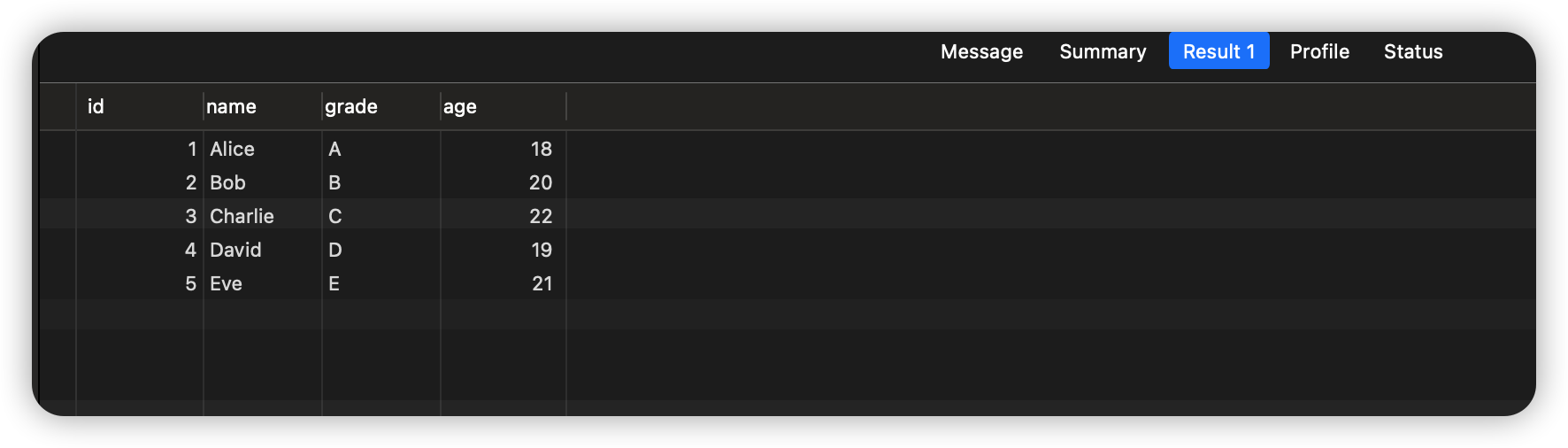
而在MySql8.0之后可以直接使用自定义排序规则通过FIELD()函数来实现自定义排序。FIELD()函数接受一个字段和一个值列表作为参数,并返回该字段在值列表中的位置。上述示例我们可以改造为:
SELECT *
FROM students
ORDER BY FIELD(grade,'A','B','C','D','E');
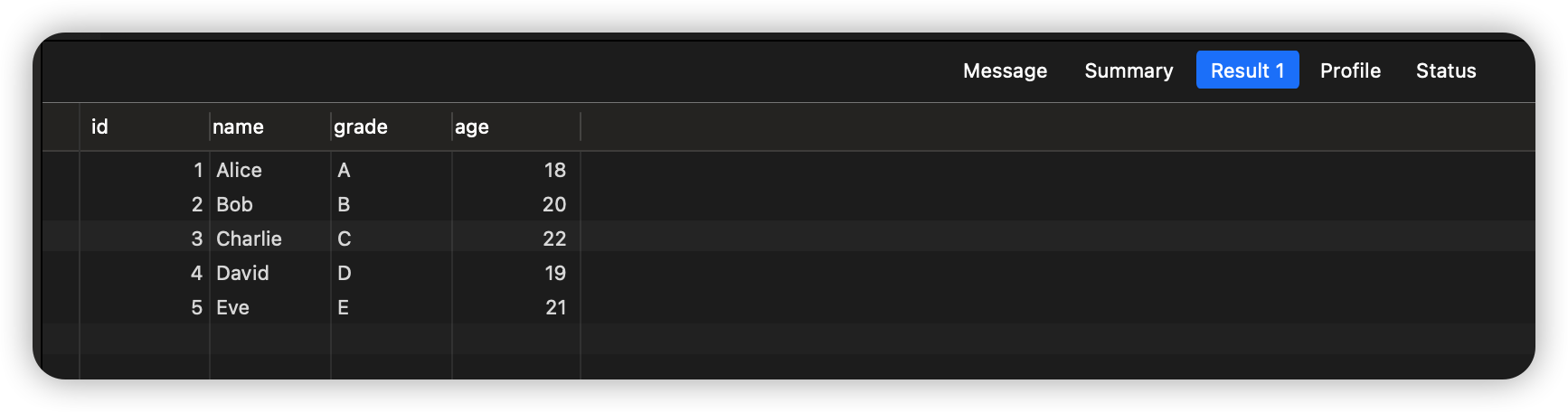
再例如我们在按照自定义的名称的规则排序:
SELECT *
FROM students
ORDER BY FIELD(name, 'Eve','David','Charlie','Bob','Alice');
执行结果:
需要注意的是,FIELD()函数会返回字段在值列表中的位置,如果字段的值不在值列表中,则返回0。所以如果你的字段可能包含不在值列表中的值,可能需要在排序时进行适当的处理。
这种方法相对简单,并且在某些情况下非常方便,但也有一些限制。特别是,当值列表很长时,这种方法可能不够灵活,因为需要在ORDER BY子句中硬编码所有的值。
空值NULL排序
在MySQL中,当涉及到NULL值排序时,通常,NULL值在升序排序(ASC)中被视为小于任何非NULL值,而在降序排序(DESC)中则被视为大于任何非NULL值。
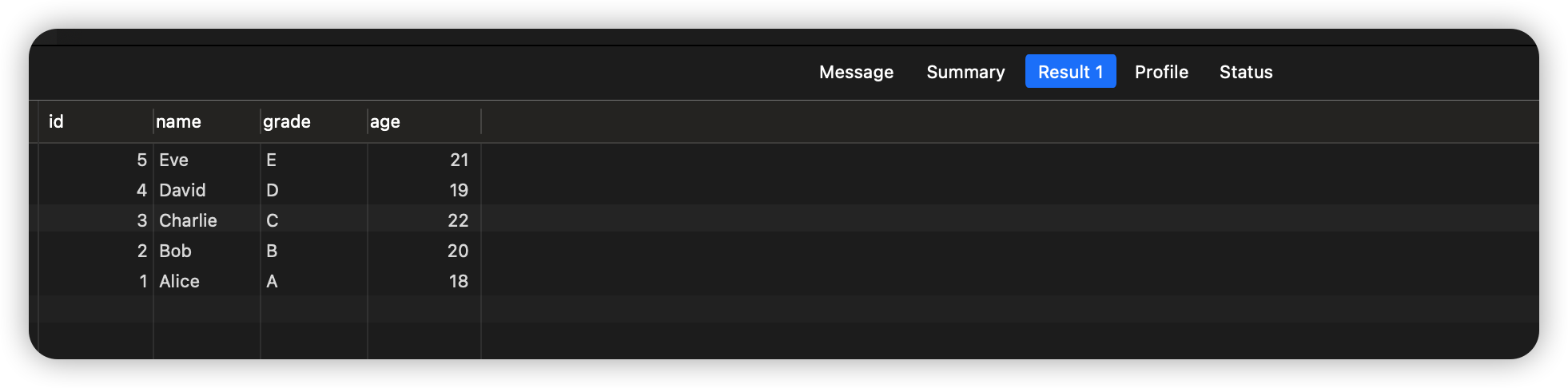
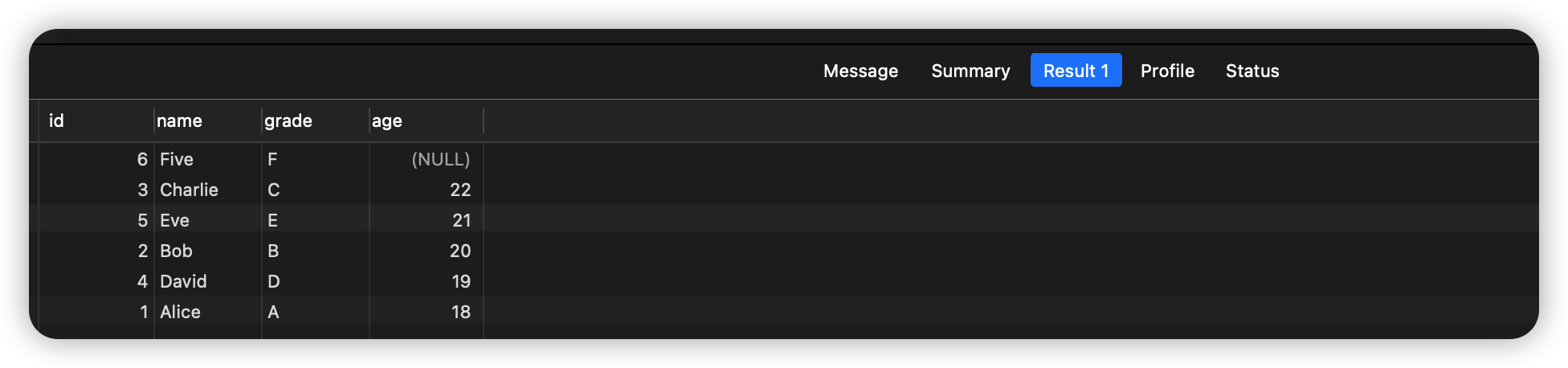
SELECT * FROM students ORDER BY age ASC;
执行结果:
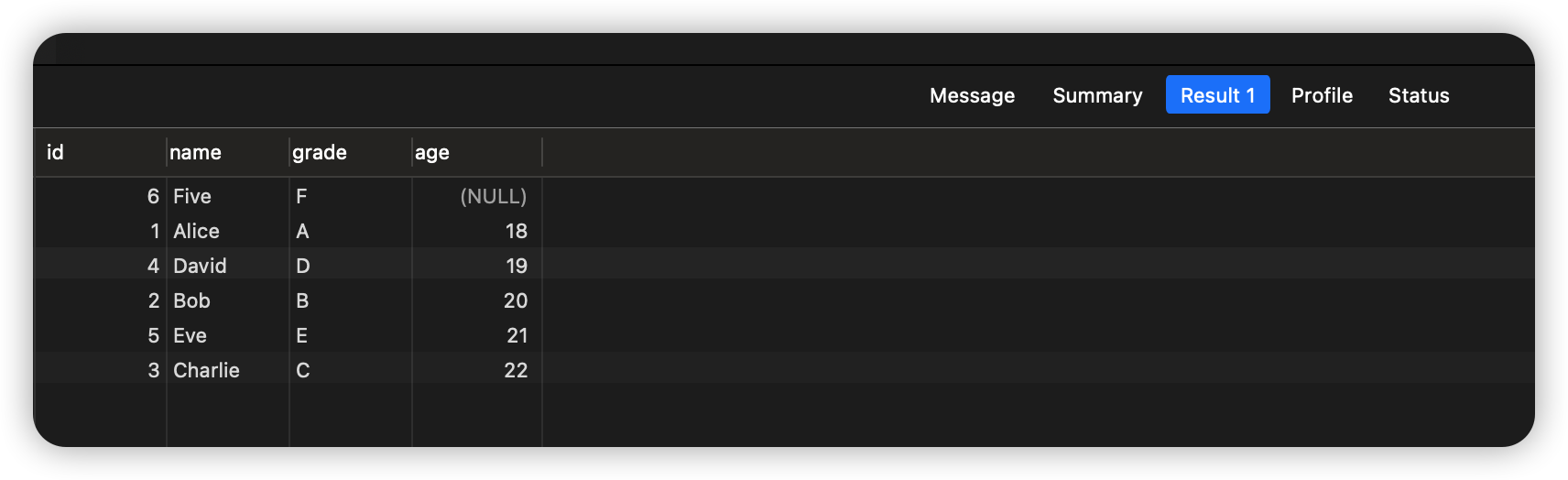
SELECT * FROM students ORDER BY age DESC;
执行结果:
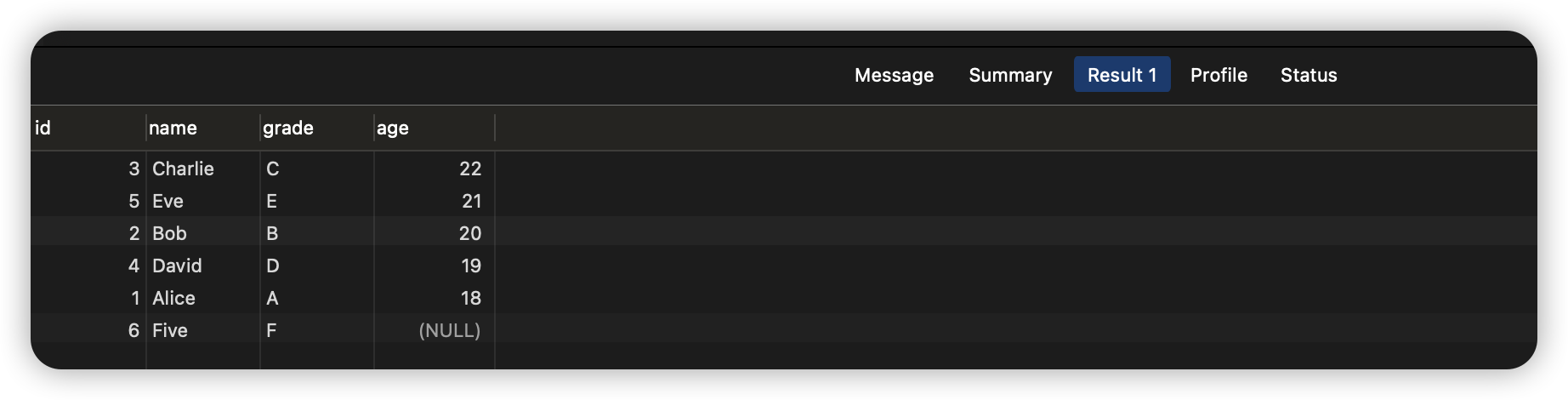
如果你希望NULL值出现在排序结果的末尾或开头,可以使用COALESCE或IFNULL函数或者ORDER BY IF(ISNULL(字段), 0, 1)来替换NULL值,从而显式控制其排序位置:
- 升序时将NULL值放在最后面:
SELECT * FROM students ORDER BY COALESCE(age, 999999) ASC;
或者
SELECT * FROM students ORDER BY IFNULL(age, 999999) ASC;
或者
SELECT * FROM students ORDER BY IF(ISNULL(age), 1, 0), age ASC;
执行结果如下:
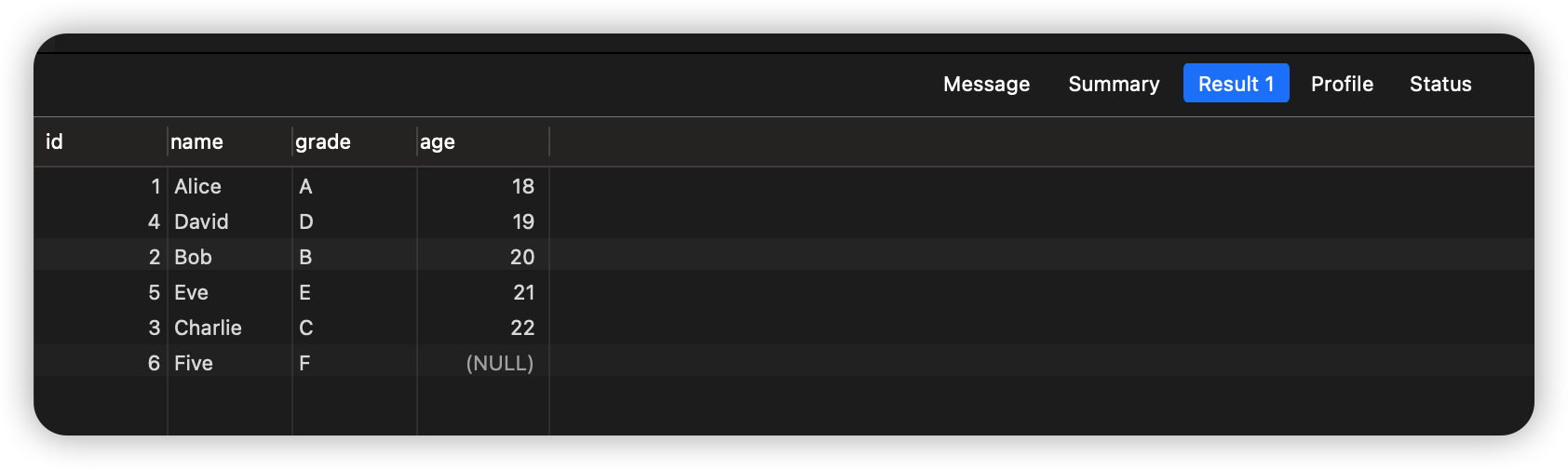
- 降序时把NULL值放在最前面:
SELECT * FROM students ORDER BY COALESCE(age, 999999) DESC;
或者
SELECT * FROM students ORDER BY IFNULL(age, 999999) DESC;
或者
SELECT * FROM students ORDER BY IF(ISNULL(age), 0, 1), age DESC;
执行结果如下:
假如对需要排序的列的最大最小的边界值可以确定,即逻辑上不会出现这么大的值的时候上述三种方式都可以实现,否则建议使用ORDER BY IF(ISNULL(age), 0, 1)的方式,当然也建议不管那种情况都要使用这种方式。
CASE表达式
CASE表达式是一种条件表达式,类似于其他编程语言中的switch语句。它允许根据条件的不同返回不同的值。
CASE表达式的基本语法如下:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE resultN
END
condition1、condition2等是条件,可以是任何逻辑表达式。result1、result2等是对应条件为真时要返回的结果。ELSE子句是可选的,用于处理所有条件都不满足的情况,如果省略了ELSE子句且所有条件都不满足,则返回NULL。
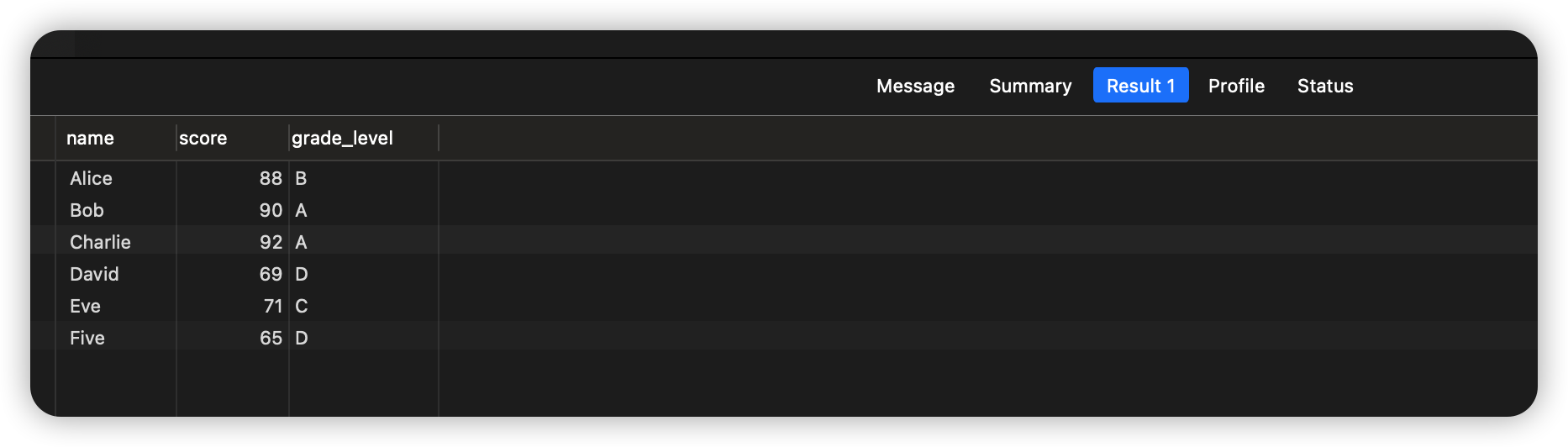
SELECT
name,
score,
CASE
WHEN score >= 90 THEN 'A'
WHEN score >= 80 THEN 'B'
WHEN score >= 70 THEN 'C'
ELSE 'D'
END AS grade_level
FROM
students;
执行结果如下:
CASE表达式在SQL查询中用途广泛,可用于SELECT、UPDATE的SET等语句中,实现动态计算列值、根据条件更新值等功能。
分组连接函数:GROUP_CONCAT
GROUP_CONCAT函数用于将每个组内的行连接成一个字符串,并返回该字符串。通常在对结果集进行分组后,需要将每个分组内的多个值合并成一个字符串时使用。该函数在MySQL中非常有用,特别是在处理与分组相关的数据时。
GROUP_CONCAT函数的语法:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
DISTINCT:可选项,用于去除重复的值。expr:要连接的表达式。ORDER BY:可选项,用于指定连接后的字符串的排序方式。SEPARATOR:可选项,用于指定连接后的字符串的分隔符,默认为逗号,。
SELECT
class,
GROUP_CONCAT( NAME ) AS students_list
FROM
students
GROUP BY
class;
查询结果:
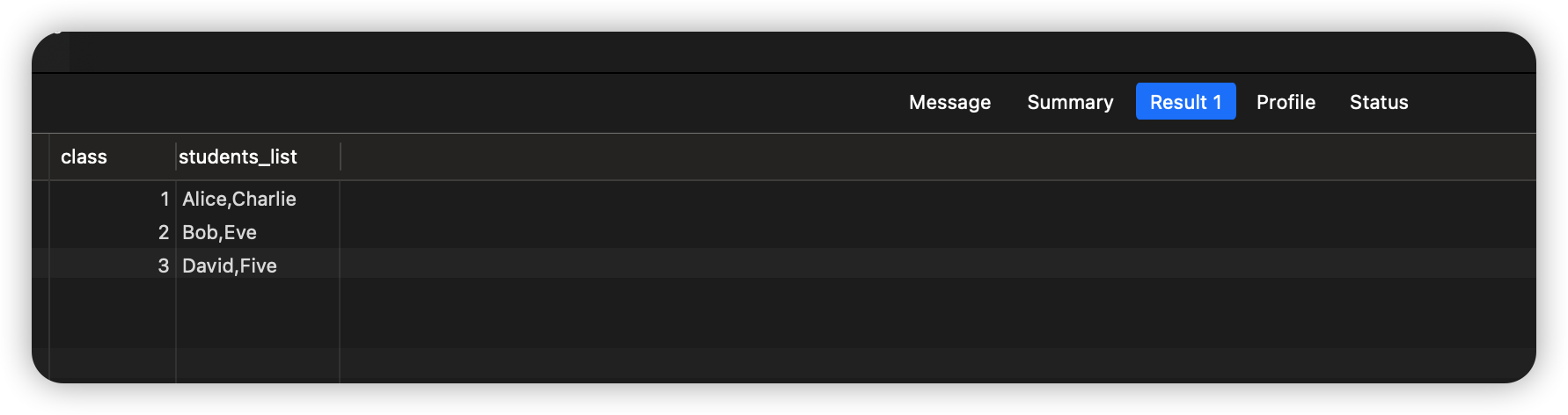
使用GROUP_CONCAT函数时,还可以通过ORDER BY子句可以指定连接后的字符串的排序方式。
SELECT
class,
GROUP_CONCAT( NAME ORDER BY age DESC SEPARATOR ';') AS students_list
FROM
students
GROUP BY
class;
执行结果:
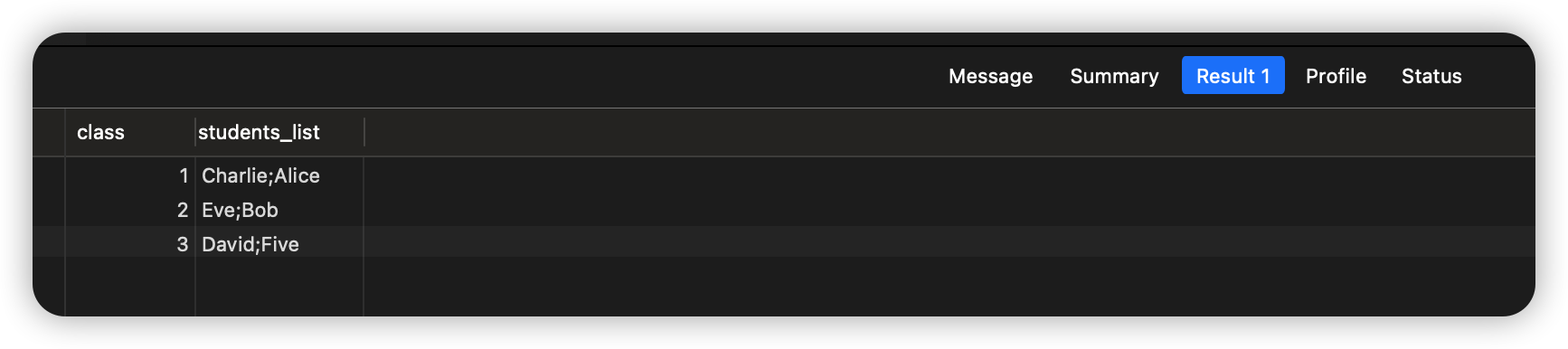
默认情况下
GROUP_CONCAT函数的最大连接长度是1024个字符。如果你的连接超过了这个限制,可以使用SET SESSION group_concat_max_len = val;语句来调整最大连接长度。
分组统计数据后在进行统计汇总:WITH ROLLUP
WITH ROLLUP是MySQL中用于执行聚合查询并生成总计行(rollup summary)的选项之一。它允许在GROUP BY子句中创建一个额外的行,该行包含了对分组数据的汇总信息。这在需要同时查看详细数据和总计数据时非常有用。
使用WITH ROLLUP时,查询结果会包含每个分组的详细数据,以及一个总计行,该总计行汇总了所有分组的数据。
SELECT
class,
AVG( age )
FROM
students
WHERE
age IS NOT NULL
GROUP BY
class WITH ROLLUP;
查询结果:
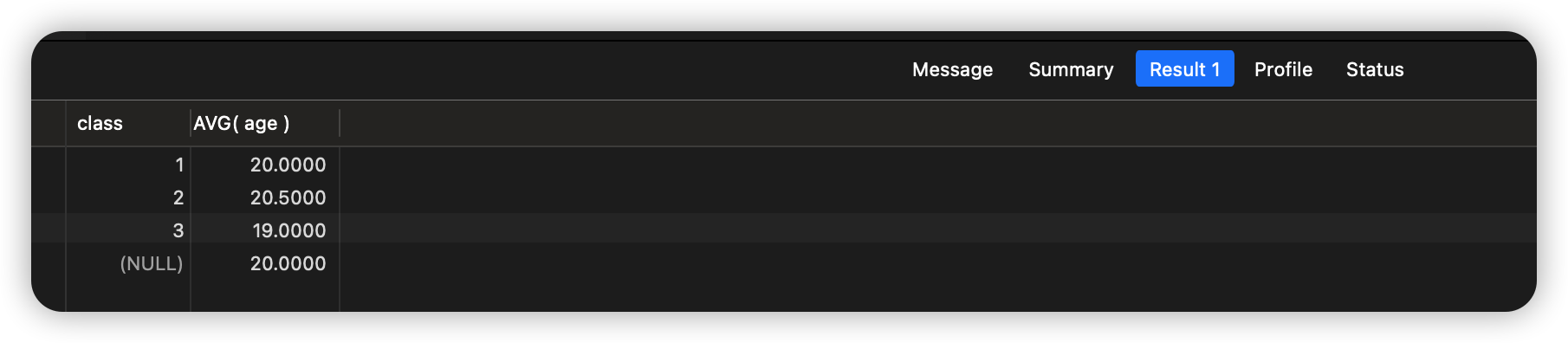
结果中包含了每个年级的平均年龄,并且返回所有的班级的学生平均年龄。
需要注意的是,总计行中分组键列的值为NULL,表示汇总了所有分组的数据。这使得我们可以通过检查分组键列是否为NULL来确定行是否为总计行。
子查询提取:WITH AS
在MySQL中,WITH AS子句(也称为子查询提取函数)允许你在一个查询中创建一个临时的命名子查询(也称为公共表表达式),然后在该查询的后续部分引用这个子查询。这有助于提高查询的可读性和简洁性,尤其是当查询中需要多次引用相同的子查询时。
WITH AS子句的基本语法:
WITH cte_name AS (
SELECT columns
FROM table
WHERE conditions
)
SELECT columns
FROM cte_name
WHERE conditions;
假如我们查询分数大于80的,并且评级为A的并且不是2班的学生信息:
WITH s1 AS ( SELECT * FROM students WHERE score > 80 ),
s2 AS ( SELECT * FROM students WHERE class = 2 )
SELECT
*
FROM
s1
WHERE
s1.id NOT IN ( SELECT s2.id FROM s2 )
AND s1.grade = 'A';
结果如下:

WITH AS是从MySql 8.0.1开始提供
优雅处理数据插入、更新时主键或者唯一键冲突
在日常开发中,我们尝尝在插入数据时会遇到唯一键冲突导致插入失败的问题。如下:
假如我们的唯一键为:
ALTER TABLE students ADD UNIQUE KEY `uk_class_name` (`name`,`class`) USING BTREE;
我们执行以下sql:
SELECT * FROM students WHERE class = 1 and name = 'Alice';
查询结果:

此时我们在插入一条数据:
INSERT INTO students (name, grade, age, score, class) VALUES ('Alice', 'A', 18, 98, 1);
发现报错:
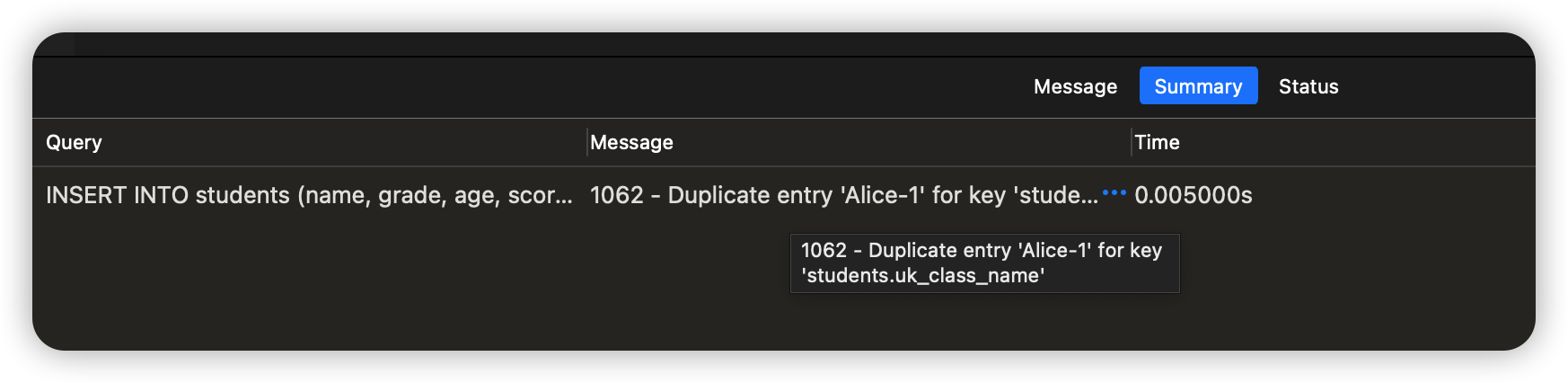
我们通常的做法时先按照唯一键查询一遍数据,如果存在则先删除数据,在进行插入。这种做法略显麻烦,并且可能会误删数据。此时我们就可以采取以下三种方法区优雅处理。
IGNORE
IGNORE关键字用于在执行插入、更新或删除操作时,忽略特定类型的错误,而不是中止整个操作。特别是在插入或更新数据时,如果存在唯一索引冲突或主键冲突,使用IGNORE关键字可以使得操作继续进行而不是因为错误而中断。
语法如下:
INSERT IGNORE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
UPDATE IGNORE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
上述插入语句的示例中,我们使用IGNORE关键字:
INSERT IGNORE INTO students (name, grade, age, score, class) VALUES ('Alice', 'A', 18, 98, 1);
执行成功。

查询数据发现,数据没有变化:

如果UPDATE使用了IGNORE关键字,在更新数据时忽略那些会导致错误的行,比如更新更新后会违反唯一约束。
UPDATE IGNORE students SET name = 'Alice' WHERE id = 3;
此时会执行成功:

IGNORE在使用时应该谨慎,它可能会掩盖潜在的业务逻辑错误或数据一致性问题。并且在事务安全性和完整性要求较高的场景下可能并不适用。
REPLACE
REPLACE INTO是MySQL中用于向表中插入或替换数据的一种特殊语法。它类似于INSERT INTO语句,但是在插入数据时,如果发现表中已存在具有相同唯一索引或主键的记录,则会删除现有记录,然后插入新记录,而不是抛出错误或导致插入操作失败。即有则删除在插入,没有则插入。
语法如下:
REPLACE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
你也可以使用REPLACE INTO与SELECT语句结合使用来替换表中的数据:
REPLACE INTO table_name (column1, column2, ...)
SELECT column1, column2, ...
FROM another_table
WHERE condition;
我们执行如下sql:
REPLACE INTO students (name, grade, age, score, class) VALUES ('Alice', 'A', 18, 98, 1);
执行成功,查询这条记录:
此时我们发现记录的id重新生成了,并且数据页是插入的最新的数据。
REPLACE INTO会首先尝试删除表中具有相同唯一索引或主键的记录,然后再插入新记录。因此,在使用REPLACE INTO时应当谨慎,以确保不会意外删除需要保留的数据。
ON DUPLICATE KEY UPDATE
在MySQL中,ON DUPLICATE KEY UPDATE是用于在执行INSERT语句时,如果发生唯一键冲突(即违反了唯一索引或主键约束),则执行后面的更新操作。
当你想要向表中插入一行数据,但是如果这一行数据已经存在(即主键或唯一索引已经存在),则更新该行数据而不是插入新的行,即有则更新,没有则插入。
语法如下:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATE column1 = value1, column2 = value2, ...;
我们执行以下sql:
INSERT IGNORE INTO students ( NAME, grade, age, score, class )
VALUES
( 'Alice', 'A', 18, 98, 1 )
ON DUPLICATE KEY UPDATE score = 100,
grade = 'B';
执行成功,重新看一下这条数据:

数据已执行了更新操作。
这种方式适用于需要维护唯一记录(如用户名、邮箱等)的情况下,无需预先检查是否存在重复,就能保证数据的一致性和完整性。同时,它也减少了对数据库的请求次数,提高了处理效率。
总结
掌握以上这几种SQL进阶用法,能够让你在日常的数据处理工作中更加得心应手,少走很多弯路。通过优化查询逻辑、处理异常情况以及执行插入或更新操作,你可以更高效地管理和操作数据库,提升工作效率,从而更好地应对各种复杂的数据处理需求。
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号