SpringBoot + LiteFlow:轻松应对复杂业务逻辑,简直不要太香!
 LiteFlow是一个非常强大的现代化的规则引擎框架,融合了编排特性和规则引擎的所有特性。它是一个编排式的规则引擎框架,组件编排,帮助解耦业务代码,让每一个业务片段都是一个组件。
LiteFlow是一个非常强大的现代化的规则引擎框架,融合了编排特性和规则引擎的所有特性。它是一个编排式的规则引擎框架,组件编排,帮助解耦业务代码,让每一个业务片段都是一个组件。
LiteFlow简介
LiteFlow是什么?
LiteFlow是一款专注于逻辑驱动流程编排的轻量级框架,它以组件化方式快速构建和执行业务流程,有效解耦复杂业务逻辑。通过支持热加载规则配置,开发者能够即时调整流程步骤,将复杂的业务如价格计算、下单流程等拆分为独立且可复用的组件,从而实现系统的高度灵活性与扩展性,避免了牵一发而动全身的问题。旨在优化开发流程,减少冗余工作,让团队能够更聚焦于核心业务逻辑,而将流程控制层面的重任托付给该框架进行自动化处理。
LiteFlow整合了流程编排与规则引擎的核心特性,提供XML、JSON或YAML格式的灵活流程定义,以及本地文件系统、数据库、ZooKeeper、Nacos、Apollo、Redis等多种规则文件存储方案。其内建插件如liteflow-rule-nacos,以及开放的扩展机制,赋予开发人员自定义规则解析器的能力,满足多样化场景下的规则管理需求。
对于基于角色任务流转的场景,
LiteFlow并非最佳选择,推荐使用Flowable或Activiti等专门的工作流引擎。
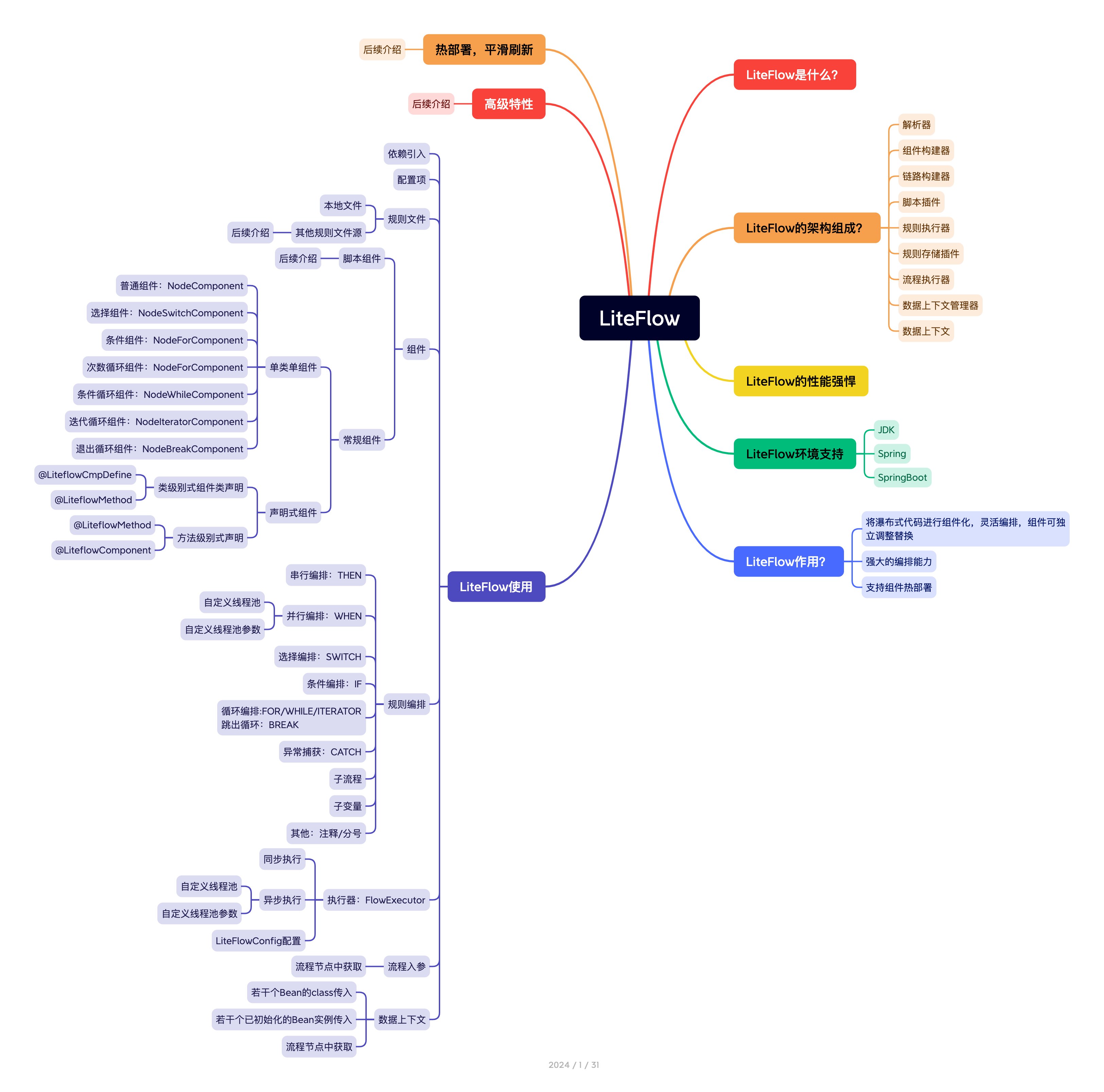
LiteFlow的架构
LiteFlow是从获取上下文开始的,这个上下文通常包含了执行流程所需的数据和环境信息。通过解析这些上下文数据,LiteFlow能够理解并执行对应的规则文件,驱动业务流程的执行。在LiteFlow中,业务流程被组织成一系列的链路(或节点),每个链路代表一个业务步骤或决策点。这些链路上的节点,也就是业务组件,是独立的,可以支持多种脚本语言,如Groovy、JavaScript、Python、Lua等,以便根据具体业务需求进行定制。下图为LiteFlow的整体架构图。
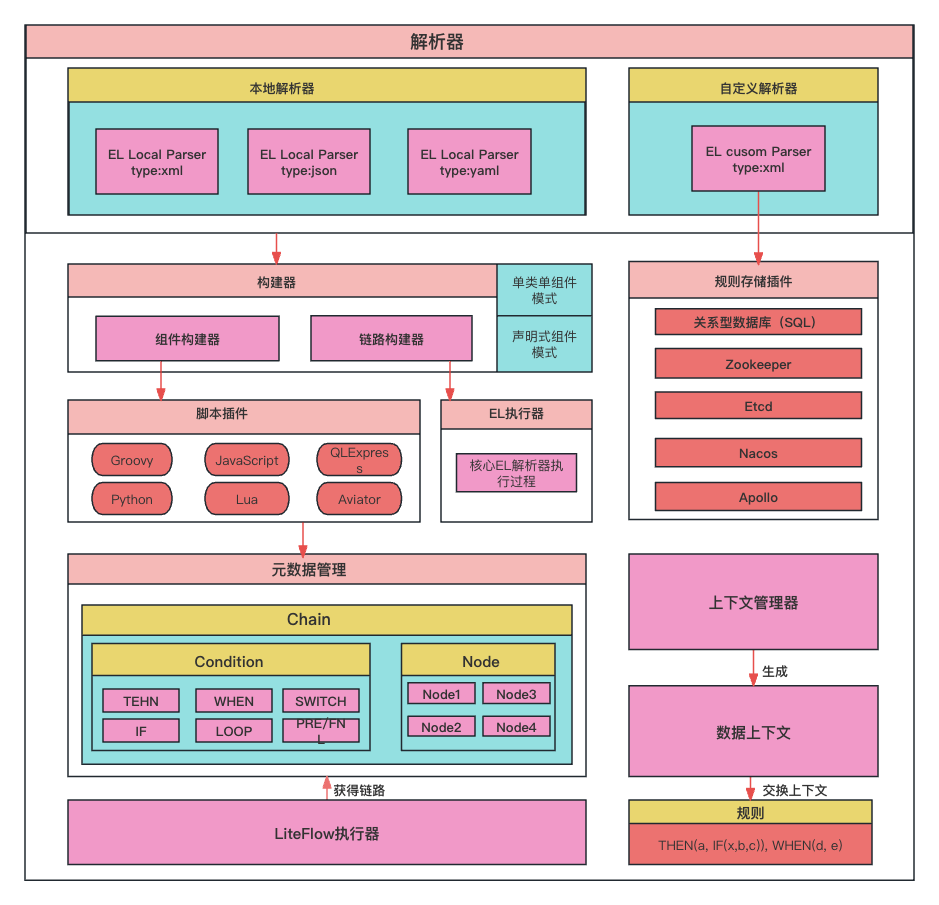
LiteFlow的作用
-
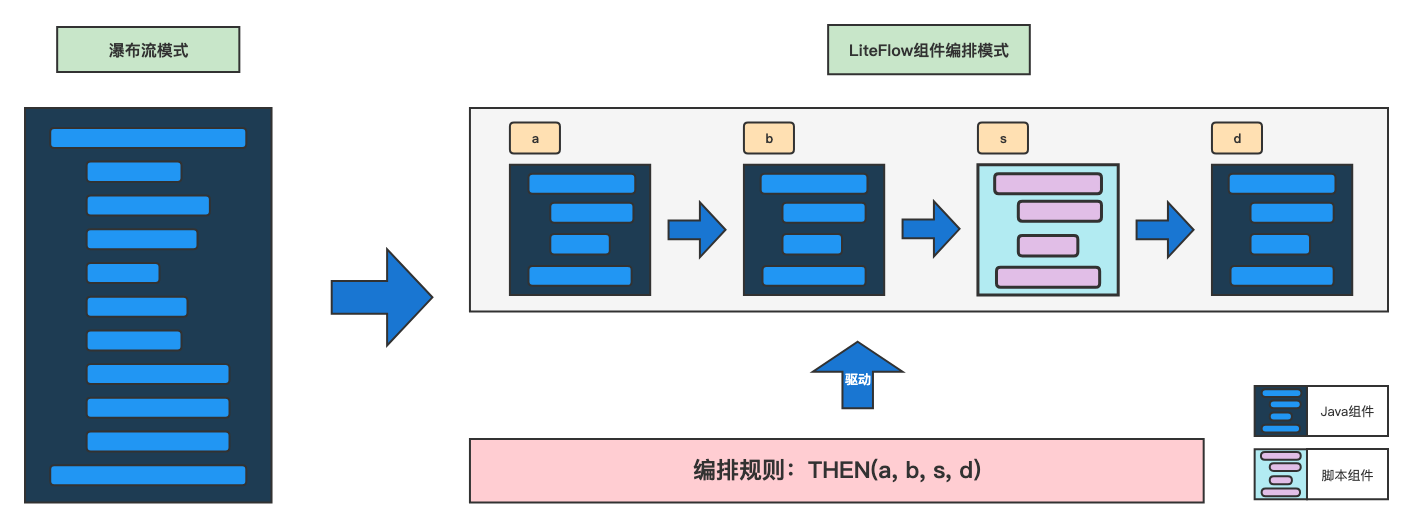
LiteFlow将瀑布式代码进行组件化、灵活的编排体系,组件可独立调整替换,规则引擎语法简单易学。
利用LiteFlow可以把传统的瀑布式代码重构为以组件为中心的概念体系,从而获得灵活的编排能力。在这种结构里,各个组件彼此分离,允许轻松调整和替换。组件本身可通过脚本定制,而且组件间的过渡完全受规则引导。此外,LiteFlow具备简单易懂的DSL规则引擎语法,能快速入门掌握。
![image.png]()
-
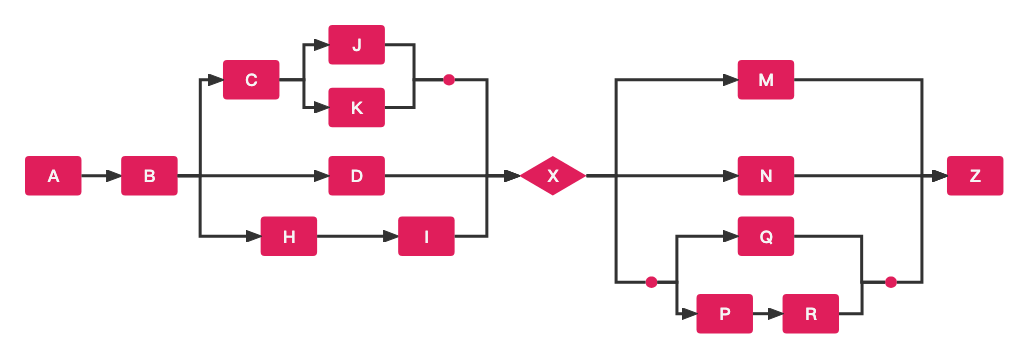
LiteFlow强大的编排能力
LiteFlow的编排语法强大到可以编排出任何你想要的逻辑流程。如下图复杂的语法,如果使用瀑布式的代码去写,那种开发以及维护难度可想而知,但是使用LiteFlow你可以轻松完成逻辑流程的编排,易于维护。
![image.png]()
-
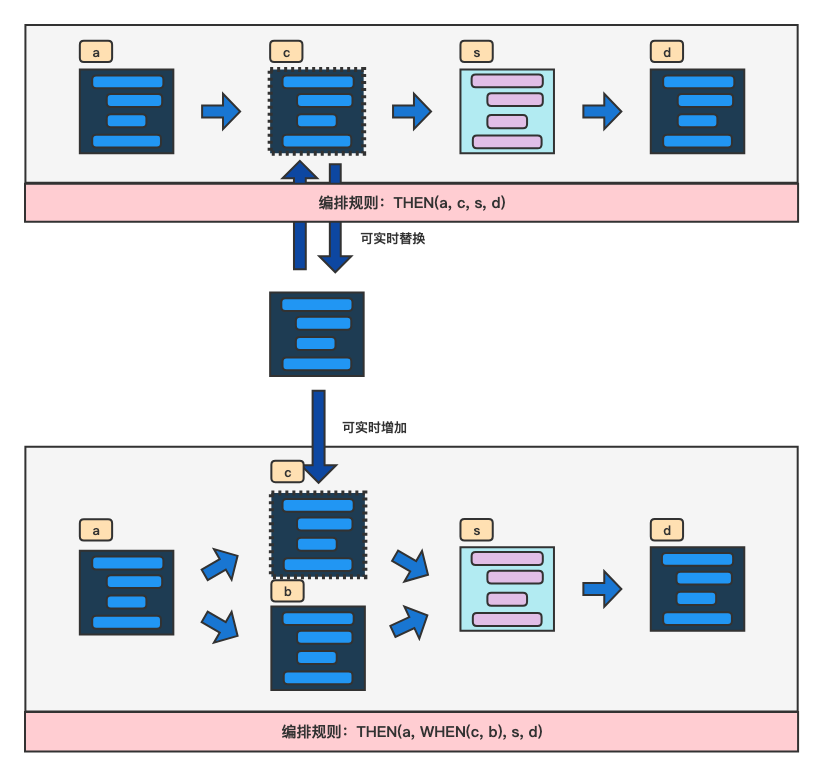
LiteFlow支持组件热部署
通过LiteFlow,你可以实现组件的实时热替换,同时也能在已有的逻辑流程中随时插入新的组件,以此动态调整你的业务逻辑。
![image.png]()
LiteFlow的环境支持
- JDK
LiteFlow要求的最低的JDK版本为8,支持JDK8~JDK17所有的版本。当然如果使用JDK11以上,确保LiteFlow的版本为v2.10.6及其以上版本。
如果你使用JDK11及其以上的版本,请确保jvm参数加上以下参数:--add-opens java.base/sun.reflect.annotation=ALL-UNNAMED
-
Spring
LiteFlow要求的Spring的最低版本为Spring 5.0。支持的范围是Spring 5.X ~ Spring 6.X。 -
SpringBoot
LiteFlow要求的Springboot的最低的版本是2.0。支持的范围是Springboot 2.X ~ Springboot 3.X。
LiteFlow的性能
LiteFlow框架在启动时完成大部分工作,包括解析规则、注册组件和组装元信息,执行链路时对系统资源消耗极低。在设计之初就注重性能表现,对核心代码进行了优化。
实际测试中,LiteFlow表现出色,50多个业务组件组成的链路在压测中单点达到1500 TPS,成功应对双11、明星顶流带货等大规模流量挑战。
尽管LiteFlow框架自身性能卓越,但实际执行效率取决于业务组件的性能。若组件包含大量循环数据库查询、不良SQL 或大量RPC同步调用,整体TPS也会较低。但这归咎于业务组件的性能问题,而非LiteFlow框架本身的性能问题。整体系统吞吐量的高低不只依赖于某个框架,而是需要整体优化业务代码才能提升。
数据来源于LiteFlow官方文档说明。
LiteFlow使用
以下我们结合SpringBoot环境使用。
LiteFlow在使用上可以按照引入依赖,LiteFlow相关配置,规则文件,定义组件,节点编排,执行流程进行。
引入依赖
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-spring-boot-starter</artifactId>
<version>2.11.1</version>
</dependency>
目前liteflow的稳定版本已经更新到2.11.4.2。本文依托于2.11.1做讲解演示。好多新的功能均在2.9.0以后的版本中才有。
配置项
LiteFlow有诸多配置项,大多数配置项有默认值,可以不必配置,同时官方也建议某个配置项不了解它有什么用时,就不要去随意的改它的值。
liteflow:
#规则文件路径
rule-source: config/flow.el.xml
#-----------------以下非必须-----------------
#liteflow是否开启,默认为true
enable: true
#liteflow的banner打印是否开启,默认为true
print-banner: true
#zkNode的节点,只有使用zk作为配置源的时候才起作用,默认为/lite-flow/flow
zk-node: /lite-flow/flow
#上下文的最大数量槽,默认值为1024
slot-size: 1024
#FlowExecutor的execute2Future的线程数,默认为64
main-executor-works: 64
#FlowExecutor的execute2Future的自定义线程池Builder,LiteFlow提供了默认的Builder
main-executor-class: com.yomahub.liteflow.thread.LiteFlowDefaultMainExecutorBuilder
#自定义请求ID的生成类,LiteFlow提供了默认的生成类
request-id-generator-class: com.yomahub.liteflow.flow.id.DefaultRequestIdGenerator
#并行节点的线程池Builder,LiteFlow提供了默认的Builder
thread-executor-class: com.yomahub.liteflow.thread.LiteFlowDefaultWhenExecutorBuilder
#异步线程最长的等待时间(只用于when),默认值为15000
when-max-wait-time: 15000
#异步线程最长的等待时间(只用于when),默认值为MILLISECONDS,毫秒
when-max-wait-time-unit: MILLISECONDS
#when节点全局异步线程池最大线程数,默认为16
when-max-workers: 16
#并行循环子项线程池最大线程数,默认为16
parallelLoop-max-workers: 16
#并行循环子项线程池等待队列数,默认为512
parallelLoop-queue-limit: 512
#并行循环子项的线程池Builder,LiteFlow提供了默认的Builder
parallelLoop-executor-class: com.yomahub.liteflow.thread.LiteFlowDefaultParallelLoopExecutorBuilder
#when节点全局异步线程池等待队列数,默认为512
when-queue-limit: 512
#是否在启动的时候就解析规则,默认为true
parse-on-start: true
#全局重试次数,默认为0
retry-count: 0
#是否支持不同类型的加载方式混用,默认为false
support-multiple-type: false
#全局默认节点执行器
node-executor-class: com.yomahub.liteflow.flow.executor.DefaultNodeExecutor
#是否打印执行中过程中的日志,默认为true
print-execution-log: true
#是否开启本地文件监听,默认为false
enable-monitor-file: false
#是否开启快速解析模式,默认为false
fast-load: false
#简易监控配置选项
monitor:
#监控是否开启,默认不开启
enable-log: false
#监控队列存储大小,默认值为200
queue-limit: 200
#监控一开始延迟多少执行,默认值为300000毫秒,也就是5分钟
delay: 300000
#监控日志打印每过多少时间执行一次,默认值为300000毫秒,也就是5分钟
period: 300000
只要使用规则,则必须配置
rule-source配置,但是如果你是用代码动态构建规则,则rule-source自动失效。
规则文件
从上面LiteFlow的整体架构图中可以看出LiteFlow支持多种规则文件源配置:本地文件,数据库,zk,Nacos,Apollo,Etcd,Redis以及自定义配置源。本文将会以本地规则文件为例讲解,其余配置源将在后续文章中讲解实时修改流程中在进行分享,
LiteFlow支持3种规则文件格式:XML,JSON,YML,3种文件的配置相差无几。LiteFlow的组成很轻量,主要由Node以及Chain元素构成。值得一提的是:如果在非Spring环境下,Node节点是必须的,配置配置,否则会导致报错找不到节点。当然在Spring环境下,我们可以不必配置Node节点,只需要将相应的节点注册到Spring上下文即可。
<?xml version="1.0" encoding="UTF-8"?>
<flow>
<chain name="chain1">
THEN(a, b, c);
</chain>
<chain name="scChain">
SWITCH(s1).to(s2, THEN(a,b).id("d"));
</chain>
</flow>
组件
在介绍具体的组件之前,我们先来了解下@LiteflowComponent注解。
@Target({ ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Component
public @interface LiteflowComponent {
@AliasFor(annotation = Component.class, attribute = "value")
String value() default "";
@AliasFor(annotation = Component.class, attribute = "value")
String id() default "";
/**
* 可以给节点起别名
**/
String name() default "";
}
@LiteflowComponent继承自@Component注解,在Spring环境中,可以将组件注入到容器中。它的value或者id即对应规则文件中的node的id。例如上述规则文件中的a,b,c等。
普通组件:NodeComponent
普通组件节点需要继承NodeComponent,需要实现process方法。可用于THEN和WHEN编排中。
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
System.out.println("执行A规则");
}
}
当然NodeComponent中还有一些其他方法可以重写,以达到自己的业务需求。例如:
- isAccess():表示是否进入该节点,可以用于业务参数的预先判断。
- isContinueOnError():表示出错是否继续往下执行下一个组件,默认为false
- isEnd():是否结束整个流程(不往下继续执行)。
如果返回true,则表示在这个组件执行完之后立马终止整个流程。此时由于是用户主动结束的流程,属于正常结束,所以流程结果中(LiteflowResponse)的isSuccess是true。 - beforeProcess()和afterProcess():流程的前置和后置处理器,其中前置处理器,在
isAccess之后执行。 - onSuccess()和onError():流程的成功失败事件回调
- rollback():流程失败后的回滚方法。
在任意组件节点的内部,还可以使用this关键字调用对应的方法:
- 获取流程初始入参参数
我们在组件节点内部可以通过this.getRequestData()去获取流程初始的入参。例如:
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
DataRequest dataRequest = this.getRequestData();
System.out.println("执行A规则");
}
}
- 获取上下文
在组件节点里,随时可以通过方法this.getContextBean(clazz)获取当前你自己定义的上下文,从而可以获取到上下文的数据。例如:
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
ConditionContext context = this.getContextBean(ConditionContext.class);
System.out.println("执行A规则");
}
}
- setIsEnd
是否立即结束整个流程 ,用法为this.setIsEnd(true)。
还有一些其他的方法,可以参考源码。
选择组件:NodeSwitchComponent
实际业务中,我们针对不同的业务类型,有不同的业务处理逻辑,例如上一篇文章中的订单类型一样,此时就需要节点动态的判断去执行哪些节点或者链路,所以就出现了选择组件。
选择组件需要实现NodeSwitchComponent,并且需要实现processSwitch()方法。用于SWITCH编排中。
processSwitch()方法返回值是一个String,即下一步流程执行的节点ID或者链路tag。
@LiteflowComponent("s)
public class SwitchComponent extends NodeSwitchComponent {
@Override
public String processSwitch() throws Exception {
System.out.println("执行switch规则");
return "a";
}
}
规则文件中,配置的SWITCH编排信息为:
<chain name="scChain">
SWITCH(s).to(a, b, c);
</chain>
此时s节点就会返回要执行的节点id为a,即要执行a流程。通常switch的节点的逻辑我们需要具体结合业务类型,例如订单类型枚举去使用。
除了可以返回id以外,我们还可以返回tag(标签)。例如我们在规则文件中这么写:
在规则表达式中我们可以这样使用:
<chain name="scChain">
SWITCH(s).to(a.tag("td"), b.tag("td"), c.tag("td));
</chain>
然后在SWITCH中返回tag:
@LiteflowComponent("s)
public class SwitchComponent extends NodeSwitchComponent {
@Override
public String processSwitch() throws Exception {
System.out.println("执行switch规则");
return ":td" // 进入 b 节点,含义:选择第一个标签为td的节点
return "tag:td" // 进入 b 节点,含义:选择第一个标签为td的节点
return "a"; // 进入 b 节点,含义:选择targetId是b的节点
return "b:"; // 进入 b 节点,含义:选择第一个targetId是b的节点
return "b:td"; // 进入 b 节点,含义:选择targetId是b且标签是td的节点
return ":"; // 进入 b 节点,含义:选择第一个节点
return "d"; // 进入 d 节点,含义:选择targetId是d的节点
return "d:"; // 进入 d 节点,含义:选择第一个targetId是d的节点
return "d:td"; // 进入 d 节点,含义:选择targetId是d且标签是td的节点
return "b:x"; // 报错,原因:没有targetId是b且标签是x的节点
return "x"; // 报错,原因:没有targetId是x的节点
return "::"; // 报错,原因:没有找到标签是":"的节点
}
}
NodeSwitchComponent继承至NodeComponent,其节点的内部可以覆盖的方法和this关键字NodeComponent。
条件组件:NodeForComponent
条件组件,也是IF组件,返回值是一个boolean。需要继承NodeForComponent,实现processIf()方法。可用于IF...ELIF...ELSE编排。例如:
<chain name = "ifChain">
IF(x, a, b);
</chain>
该例中x就是一个条件组件,如果x返回true,则会执行a节点,否则执行b节点。
@LiteflowComponent("x")
public class IfXComponent extends NodeIfComponent {
@Override
public boolean processIf() throws Exception {
System.out.println("执行X节点");
return false;
}
}
NodeIfComponent继承至NodeComponent,其节点内部可以覆盖的方法和this关键字NodeComponent。
次数循环组件:NodeForComponent
次数循环组件。返回的是一个int值的循环次数。继承NodeForComponent,实现processFor()方法, 主要用于FOR...DO...表达式。在紧接着DO编排中的节点中,可以通过this.getLoopIndex()获取下标信息,可以从对应数组或者集合中通过下表获取对应的元素信息。
<chain name = "forChain">
FOR(f).DO(a);
</chain>
@LiteflowComponent("f")
public class ForComponent extends NodeForComponent {
@Override
public int processFor() throws Exception {
DataContext dataContext = this.getContextBean(DataContext.class);
List<String> dataList = dataContext.getDataList();
return dataList.size();
}
}
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
Integer loopIndex = this.getLoopIndex();
DataContext dataContext = this.getContextBean(DataContext.class);
List<String> dataList = dataContext.getDataList();
String str = dataList.get(loopIndex);
System.out.println("执行A规则:"+str);
}
}
其中f组件相当于定义一个数组或者集合的元素个数,类似
for(int i=0;i<size;i++){ // size = f
//逻辑处理 = a
}
NodeForComponent继承至NodeComponent,其节点内部可以覆盖的方法和this关键字NodeComponent。
条件循环组件:NodeWhileComponent
条件循环组件,主要用于WHILE...DO...表达式。继承NodeWhileComponent,需要实现processWhile()方法。processWhile()方法返回一个boolean类型的值,即while循环跳出的条件,如果为false则循环结束,同次数循环,可以在DO编排中的节点中,可以通过this.getLoopIndex()获取下标信息,可以从对应数组或者集合中通过下表获取对应的元素信息。
<chain name = "whileChain">
WHILE(w).DO(a);
</chain>
@LiteflowComponent("w")
public class WhileComponent extends NodeWhileComponent {
@Override
public boolean processWhile() throws Exception {
DataContext dataContext = this.getContextBean(DataContext.class);
Integer count = Optional.ofNullable(dataContext.getCount()).orElse(0);
List<String> dataList = dataContext.getDataList();
return count < dataList.size();
}
}
NodeWhileComponent继承至NodeComponent,其节点内部可以覆盖的方法和this关键字NodeComponent。
迭代循环组件:NodeIteratorComponent
迭代循环组件,相当于Java语言的Iterator关键字,功能上相当于for循环,主要用于ITERATOR...DO...表达式。需要继承NodeIteratorComponent,实现processIterator()方法。在DO编排的节点中,可以通过this.getCurrLoopObj()获取集合中的信息。这个组件在使用liteflow的循环组件时用的比较多,就像日常开发代码,集合遍历大部分都会使用for循环(特殊情况必须使用下标除外)。
<chain name = "iteratorChain">
ITERATOR(iterator).DO(a);
</chain>
@LiteflowComponent("iterator")
public class MyIteratorComponent extends NodeIteratorComponent {
@Override
public Iterator<?> processIterator() throws Exception {
DataContext dataContext = this.getContextBean(DataContext.class);
return Optional.ofNullable(dataContext.getDataList())
.orElse(Lists.newArrayList()).iterator();
}
}
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
String str = this.getCurrLoopObj();
System.out.println("执行A规则:"+str);
}
}
NodeIteratorComponent继承至NodeComponent,循环组件节点的内部可以覆盖的方法和this关键字NodeComponent。
退出循环组件:NodeBreakComponent
退出循环组件,即BREAK组件。返回的是一个布尔值的循环退出标志。 需要继承NodeBreakComponent,实现processBreak方法。主要用于FOR...DO...BREAK,WHILE...DO...BREAK,ITERATOR...DO...BREAK表达式。即Java的for,while循环退出。
<chain name = "iteratorChain">
ITERATOR(iterator).DO(a).BREAK(break_flag);
</chain>
@LiteflowComponent("break_flag")
public class BreakComponent extends NodeBreakComponent {
@Override
public boolean processBreak() throws Exception {
String str = this.getCurrLoopObj();
return Objects.equals("c", str);
}
}
同理NodeBreakComponent也是继承NodeComponent,其节点内部可以覆盖的方法和this关键字NodeComponent。
接下来我们聊一下组件的另外一种定义方式:声明式组件。我比较喜欢用。。。
声明式组件
在上述介绍组件时,都是通过定义一个类继承某一个组件,例如NodeComponent或者NodeIteratorComponent,这样的定义组件会有一些弊端,比如当你的业务庞大时类也会快速的膨胀增加,即使一个跳出循环或者循环组件都要单独去定义一个类(个人认为循环组件其实不会包含太多的复杂业务逻辑),再比如说Java中类是单继承,这样就会造成这个写组件类无法再去继承一些其他的超类供我们使用。基于此,LiteFlow推出依靠注解完成组件的声明,即使一个普通类中的方法不需要继承任何组件类,也可以声明为一个组件,一个类可以定义很多个组件。可以分别对类或者方法进行生命组件。目前声明式组件只能在springboot环境中使用。
类级别声明
类级别式声明主要用处就是通过注解形式让普通的java bean变成LiteFlow的组件。无需通过继承类或者实现接口的方式。但是类级别声明有一个缺点就是他和常规组件一样,需要一个类对应一个组件。使用@LiteflowCmpDefine注解,通过NodeTypeEnum指定当前类是什么类型的组件。NodeTypeEnum值如下:
public enum NodeTypeEnum {
COMMON("common", "普通", false, NodeComponent.class),
SWITCH("switch", "选择", false, NodeSwitchComponent.class),
IF("if", "条件", false, NodeIfComponent.class),
FOR("for", "循环次数", false, NodeForComponent.class),
WHILE("while", "循环条件", false, NodeWhileComponent.class),
BREAK("break", "循环跳出", false, NodeBreakComponent.class),
ITERATOR("iterator", "循环迭代", false, NodeIteratorComponent.class),
SCRIPT("script", "脚本", true, ScriptCommonComponent.class),
SWITCH_SCRIPT("switch_script", "选择脚本", true, ScriptSwitchComponent.class),
IF_SCRIPT("if_script", "条件脚本", true, ScriptIfComponent.class),
FOR_SCRIPT("for_script", "循环次数脚本", true, ScriptForComponent.class),
WHILE_SCRIPT("while_script", "循环条件脚本", true, ScriptWhileComponent.class),
BREAK_SCRIPT("break_script", "循环跳出脚本", true, ScriptBreakComponent.class);
}
组件类中的再通过@LiteflowMethod注解将方法映射为组件方法。通过@LiteflowMethod中value值指定方法类型LiteFlowMethodEnum,通过nodeType指定节点类型NodeTypeEnum。LiteFlowMethodEnum对应各组件中的抽象类方法(isMainMethod=true)(或者可覆盖的方法)。
public enum LiteFlowMethodEnum {
PROCESS("process", true),
PROCESS_SWITCH("processSwitch", true),
PROCESS_IF("processIf", true),
PROCESS_FOR("processFor", true),
PROCESS_WHILE("processWhile", true),
PROCESS_BREAK("processBreak", true),
PROCESS_ITERATOR("processIterator", true),
IS_ACCESS("isAccess", false),
IS_END("isEnd", false),
IS_CONTINUE_ON_ERROR("isContinueOnError", false),
GET_NODE_EXECUTOR_CLASS("getNodeExecutorClass", false),
ON_SUCCESS("onSuccess", false),
ON_ERROR("onError", false),
BEFORE_PROCESS("beforeProcess", false),
AFTER_PROCESS("afterProcess", false),
GET_DISPLAY_NAME("getDisplayName", false),
ROLLBACK("rollback", false)
;
private String methodName;
private boolean isMainMethod;
}
对于方法的要求:
组件内的方法的参数必须传入NodeComponent类型的参数,而且必须是第一个参数。这个参数值就替代常规组件中的this,从这个参数中可以获取流程入参,上线文等信息。然后方法的返回值必须跟常规组件中的抽象方法的返回值保持一致,否则可能吹出现错误。对于方法名称并无限制。
- 普通组件:
@Component("d")
@LiteflowCmpDefine(value = NodeTypeEnum.COMMON)
public class MyDefineCmp {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON)
public void processA(NodeComponent nodeComponent){
System.out.println("processA");
}
@LiteflowMethod(value = LiteFlowMethodEnum.BEFORE_PROCESS, nodeType = NodeTypeEnum.COMMON)
public void beforeA(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("beforeA");
}
@LiteflowMethod(value = LiteFlowMethodEnum.AFTER_PROCESS, nodeType = NodeTypeEnum.COMMON)
public void afterA(NodeComponent nodeComponent){
System.out.println("afterA");
}
}
- 条件组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.IF参数。
@Component("define_if")
@LiteflowCmpDefine(NodeTypeEnum.IF)
public class MyDefineIfCpm {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_IF, nodeType = NodeTypeEnum.IF)
public boolean processIf(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行if");
return false;
}
}
- 选择组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.SWITCH参数。
@Component("define_w")
@LiteflowCmpDefine(NodeTypeEnum.SWITCH)
public class MyDefineSwitchCpm {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_SWITCH, nodeType = NodeTypeEnum.SWITCH)
public String processSwitch1(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行switch");
return "b";
}
}
- 次数循环组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.FOR参数。
@Component("define_for")
@LiteflowCmpDefine(NodeTypeEnum.FOR)
public class MyDefineForCmp {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_FOR, nodeType = NodeTypeEnum.FOR)
public int processFor(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行for");
return 10;
}
}
- 条件循环组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.WHILE参数。
@Component("define_while")
@LiteflowCmpDefine(NodeTypeEnum.WHILE)
public class MyDefineWhileCmp {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_WHILE, nodeType = NodeTypeEnum.WHILE)
public boolean processWhile(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行while");
return true;
}
}
- 迭代循环组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.ITERATOR参数。
@Component("define_iterator")
@LiteflowCmpDefine(NodeTypeEnum.ITERATOR)
public class MyDefineIteratorCpm {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_ITERATOR, nodeType = NodeTypeEnum.ITERATOR)
public Iterator<String> processSwitch1(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行iterator");
return dataContext.getDataList().iterator();
}
}
- 退出循环组件
声明选择组件在类和方法上都需要加上NodeTypeEnum.BREAK参数。
@Component("define_break")
@LiteflowCmpDefine(NodeTypeEnum.BREAK)
public class MyDefineWhileCmp {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_BREAK, nodeType = NodeTypeEnum.BREAK)
public boolean processBreak(NodeComponent nodeComponent){
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
System.out.println("执行break");
return true;
}
}
方法级别式声明
因为类级别式声明还是会造成类定义过多的问题,LiteFlow又提供了方法级别式声明。方法级别式声明可以让在一个类中通过注解定义多个组件。在类上使用@LiteflowComponent进行声明这是一个组件类,然后在方法使用@LiteflowMethod声明方法是一个组件节点。如下:
@Slf4j
@LiteflowComponent
public class OrderHandlerCmp {
/**
* 普通组件 等价于 继承`NodeComponent` 实现process()方法
* @param nodeComponent
*/
@LiteflowMethod(nodeType = NodeTypeEnum.COMMON, value = LiteFlowMethodEnum.PROCESS, nodeId = "common", nodeName = "普通组件")
public void processCommon(NodeComponent nodeComponent){
// 业务逻辑
}
/**
* IF组件 等价于 继承 `NodeIfComponent` 实现processIf()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.IF, value = LiteFlowMethodEnum.PROCESS_IF, nodeId = "if", nodeName = "IF组件")
public boolean processIf(NodeComponent nodeComponent){
// 业务逻辑
return false;
}
/**
* SWITCH组件 等价于 继承 `NodeSwitchComponent` 实现processSwitch()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.SWITCH, value = LiteFlowMethodEnum.PROCESS_SWITCH, nodeId = "switch", nodeName = "SWITCH组件")
public String processSwitch(NodeComponent nodeComponent){
// 业务逻辑
return "nodeId";
}
/**
* 次数循环组件 等价于 继承 `NodeForComponent` 实现processFor()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.FOR, value = LiteFlowMethodEnum.PROCESS_FOR, nodeId = "for", nodeName = "FOR组件")
public int processFor(NodeComponent nodeComponent){
// 业务逻辑
return 10;
}
/**
* 条件循环组件 等价于 继承 `NodeWhileComponent` 实现processWhile()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.WHILE, value = LiteFlowMethodEnum.PROCESS_WHILE, nodeId = "while", nodeName = "WHILE组件")
public boolean processWhile(NodeComponent nodeComponent){
// 业务逻辑
return false;
}
/**
* 迭代循环组件 等价于 继承 `NodeIteratorComponent` processIterator()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.ITERATOR, value = LiteFlowMethodEnum.PROCESS_ITERATOR, nodeId = "iterator", nodeName = "ITERATOR组件")
public Iterator<Object> processIterator(NodeComponent nodeComponent){
// 业务逻辑
List<Object> list = Lists.newArrayList();
return list.iterator();
}
/**
* 跳出循环组件 等价于 继承 `NodeBreakComponent` processBreak()方法
* @param nodeComponent
* @return
*/
@LiteflowMethod(nodeType = NodeTypeEnum.BREAK, value = LiteFlowMethodEnum.PROCESS_BREAK, nodeId = "break", nodeName = "BREAK组件")
public boolean processBreak(NodeComponent nodeComponent){
// 业务逻辑
return false;
}
}
对于方法级别声明特性来说,@LiteflowMethod注解上的nodeId一定要写。nodeName的属性。方便对声明式的组件进行命名。定义方法时,返回值要和常规组件里的对应方法返回值一致。例如普通组件的process方法是不返回的,比如IF组件的processIf方法是返回布尔值的。如果写错误,会造成一些异常。。。。
我个人是比较喜欢用这种方式进行组件的定义,可以按照业务逻辑将代码拆分成一个个的模块,在各自的模块中进行业务逻辑的实现,也会非常清晰。
EL规则
LiteFlow2.8.x以后版本提供了一款强大的规则表达式。一切复杂的流程在LiteFlow表达式的加持下,都变得非常简便明了。配合一些流程图简直是通熟易懂。让整个业务流程在处理上看起来并没有那么黑盒。它可以设置各种编排规则,包括:
- 串行编排
串行编排,即组件要顺序执行,使用THEN关键字,THEN必须大写
<chain name="thenchain">
THEN(a, b, c);
THEN(a, THEN(b, c));
</chain>
- 并行编排
并行编排即并行执行若干个个组件,使用用WHEN关键字,WHEN必须大写。
<chain name="whenchain">
WTHEN(a, b, c);
</chain>
当然,WHEN跟THEN还可以结合使用:
<chain name="testChain">
THEN(a, WHEN(b, c, d), e);
</chain>
当a节点执行完成之后,并行执行b,c,d节点,完成之后在执行e节点。
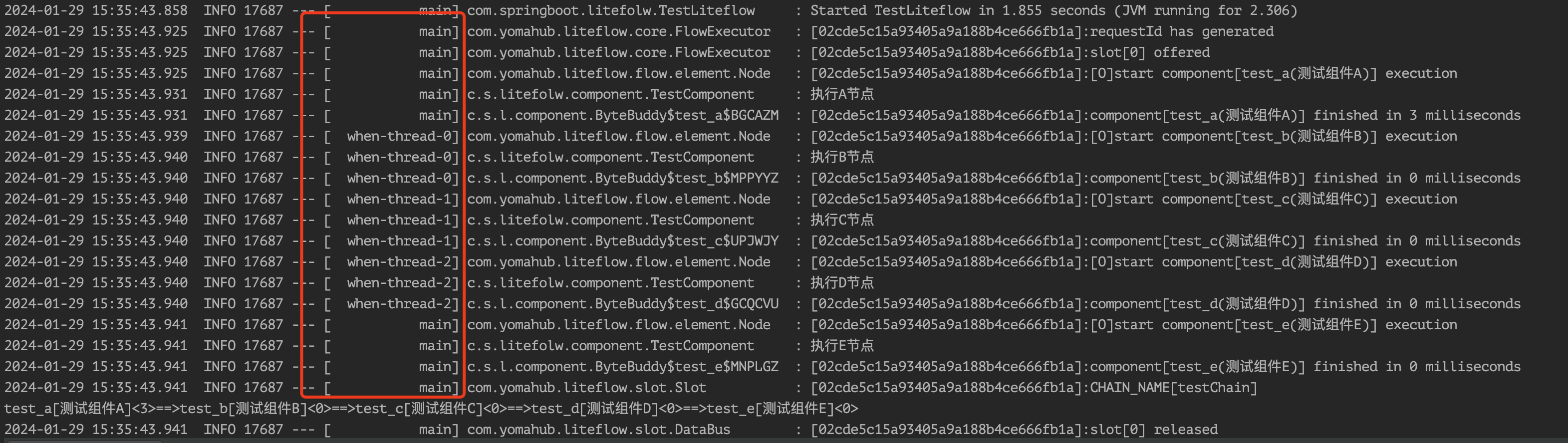
我们在看到并行执行的时候,就会联想到多线程处理,那么LiteFlow是怎么创建多线程的呢?答案是LiteFlow内部默认维护了一个when线程池,这个线程池是供给所有WHEN流程使用的。当然你可以在LiteFlow执行器执行之前给你的流程通过LiteflowConfig传入一些线程池参数或者实现ExecutorBuilder接口,自定义线程池。比如:
public class LiteFlowThreadPool implements ExecutorBuilder {
@Override
public ExecutorService buildExecutor() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("mythread-pool-%s").build();
return new ThreadPoolExecutor(
// 核心线程数,即2个常开窗口
2,
// 最大的线程数,银行所有的窗口
5,
// 空闲时间
5,
TimeUnit.SECONDS,
// 工作队列
new LinkedBlockingQueue<>(5),
// 线程工厂
threadFactory,
// 拒绝策略
new ThreadPoolExecutor.AbortPolicy()
);
}
}
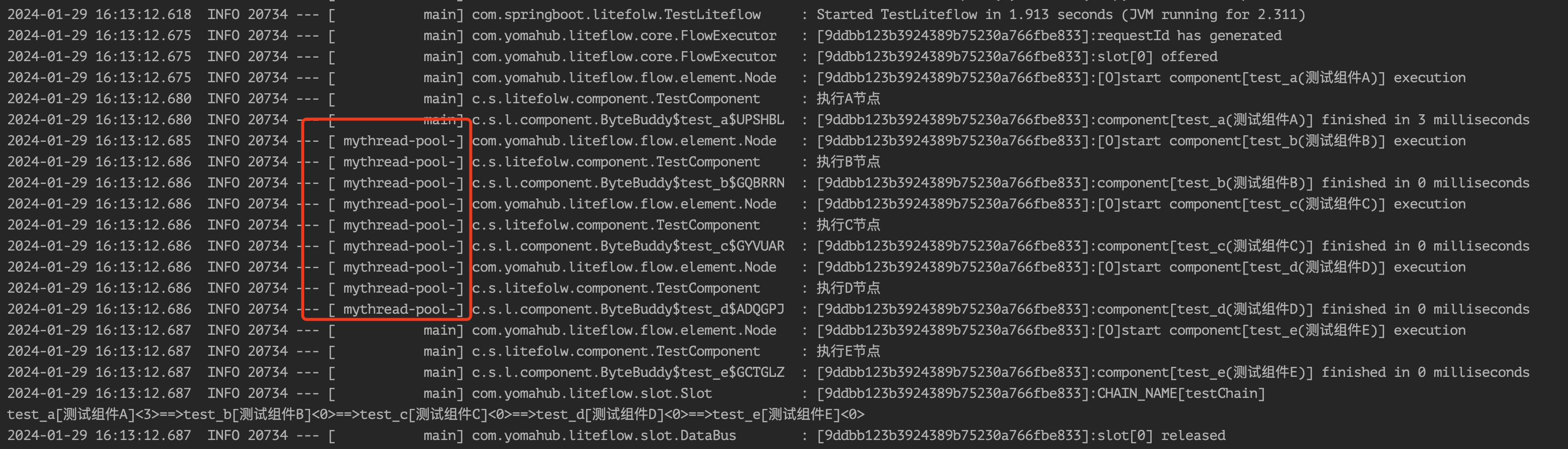
然后我们在LiteflowConfig设置并行线程执行器class路径threadExecutorClass:
LiteflowConfig liteflowConfig = new LiteflowConfig();
liteflowConfig.setThreadExecutorClass("LiteFlowThreadPool的类路径");
flowExecutor.setLiteflowConfig(liteflowConfig);
LiteflowResponse response = flowExecutor.execute2Resp("testChain", null);
执行结果,可以看见线程池使用的是自定义的:
LiteFlow从2.11.1开始,提供一个
liteflow.when-thread-pool-isolate参数,默认为false,如果设为true,则会开启WHEN的线程池隔离机制,这意味着每一个when都会有单独的线程池。
在多线程执行下,我们还有一个疑问,如果其中某个或者某几个并行分支发生异常执行失败那么后面的节点会不会收到影响?假如我们把C节点抛出一个异常,发现流程直接就结束了,并没有执行最后的E节点:
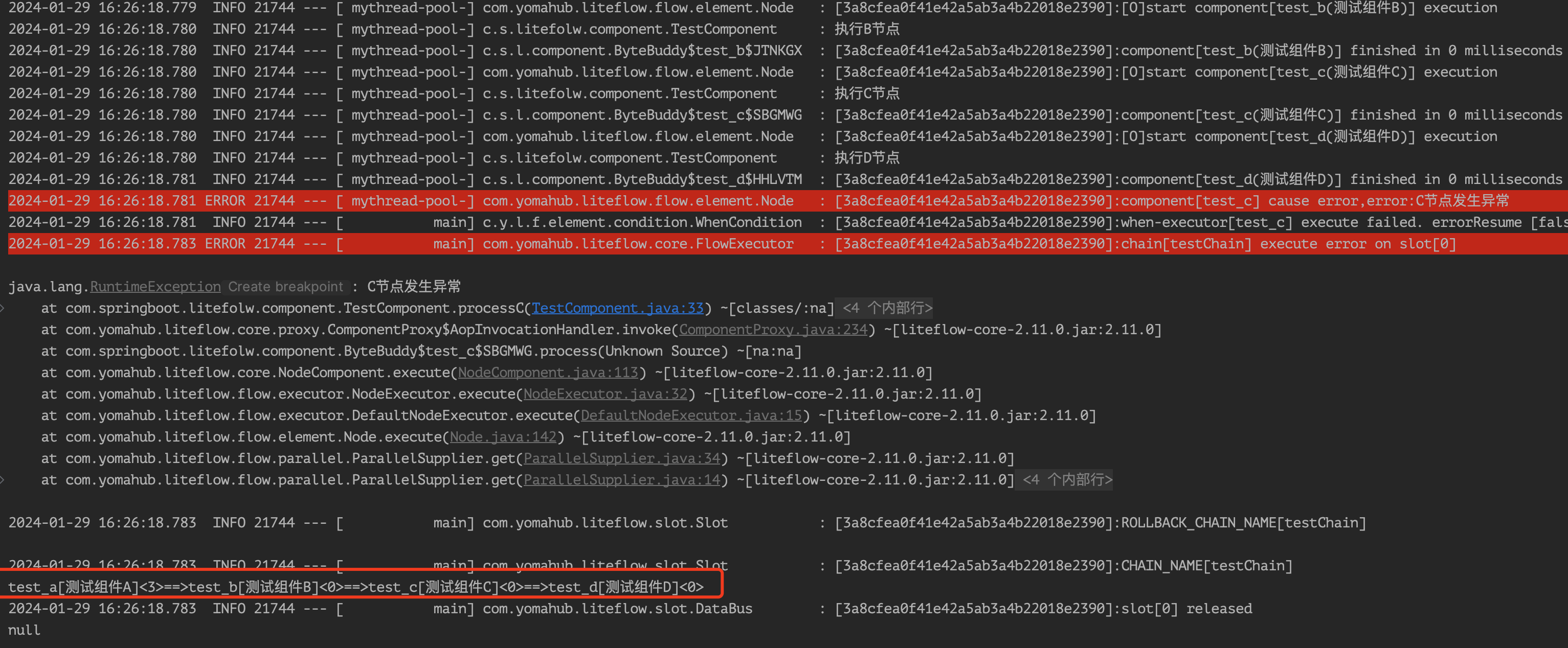
对于这种情况,LiteFlow的WHEN关键字提供了ignoreError(默认为false)来提供忽略错误的特性。我们修改流程如下:
<chain name="testChain">
THEN(test_a, WHEN(test_b, test_c, test_d).ignoreError(true), test_e);
</chain>
再次执行发现流程执行到了E节点:
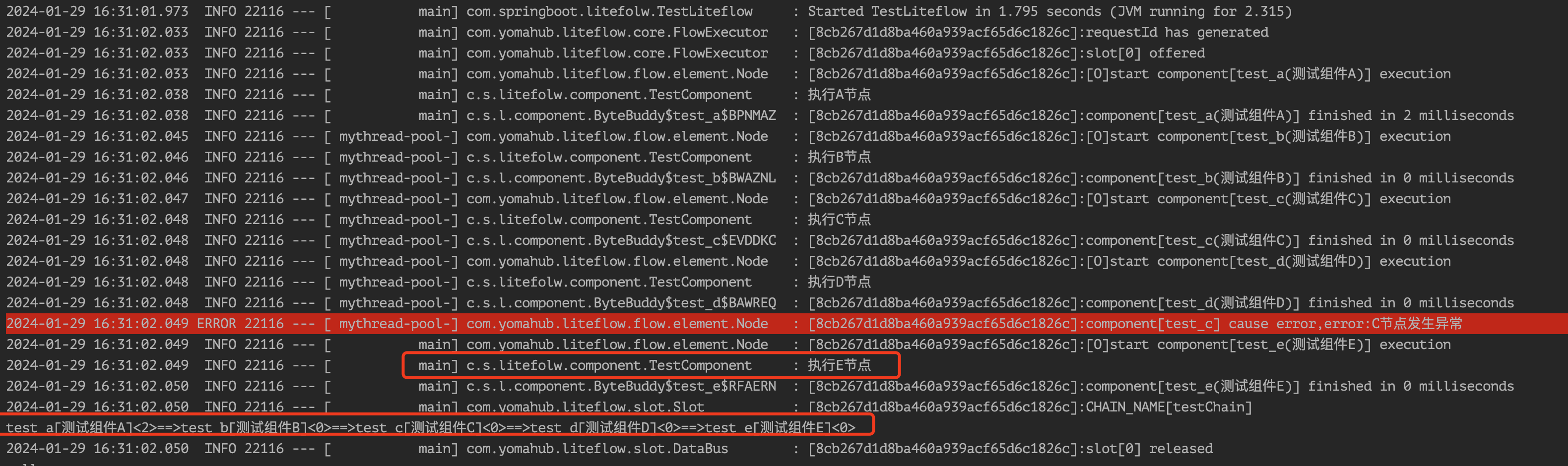
LiteFlow还提供了对WHEN并行流程中,使用子关键字any(默认为false)可以设置任一条分支先执行完即忽略其他分支,继续执行的特性。
<chain name="testChain">
THEN(test_a, WHEN(test_b, test_c, test_d).ignoreError(true).any(true), test_e);
</chain>
我们将C节点Sleep 10秒,可以发现C节点并没有执行,就执行到了E节点:
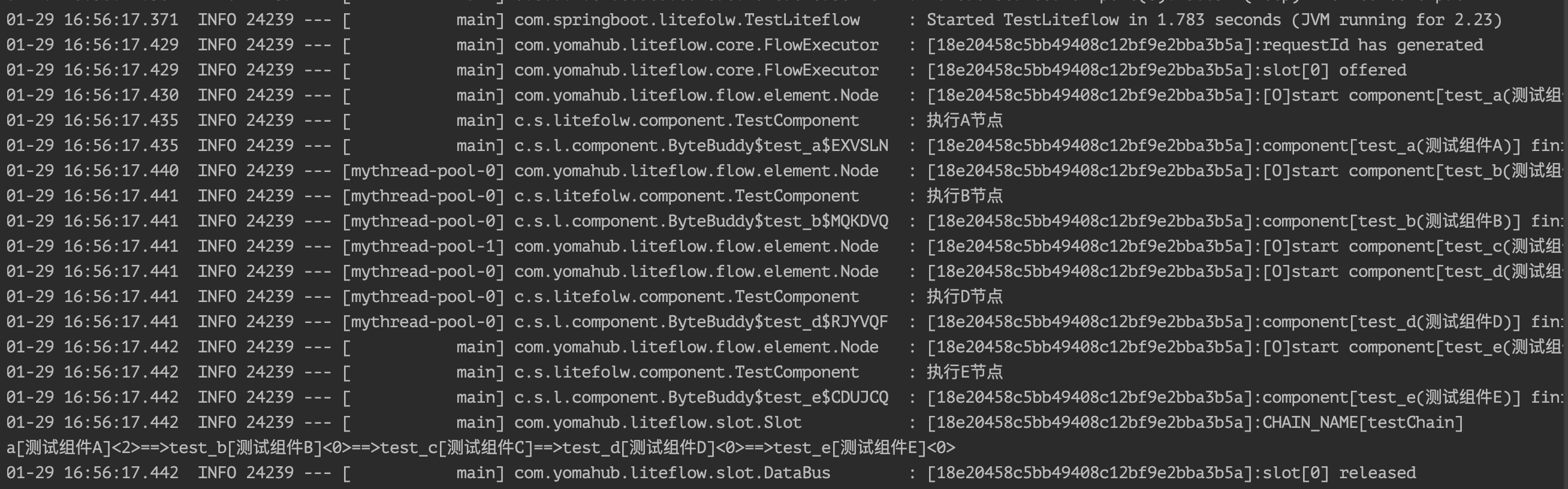
除此之外,LiteFlow还支持了并行编排中指定节点的执行则忽略其他,WHEN关键字子关键字 must (不可为空),可用于指定需等待执行的任意节点,可以为 1 个或者多个,若指定的所有节点率先完成,则继续往下执行,忽略同级别的其他任务。我们将流程调节如下:
<chain name="testChain">
THEN(test_a, WHEN(test_b, test_c, test_d).ignoreError(true).must(test_c), test_e);
</chain>
我们还是将C节点Sleep 10秒,发现流程一直等到C节点执行结束才会执行后面的节点:
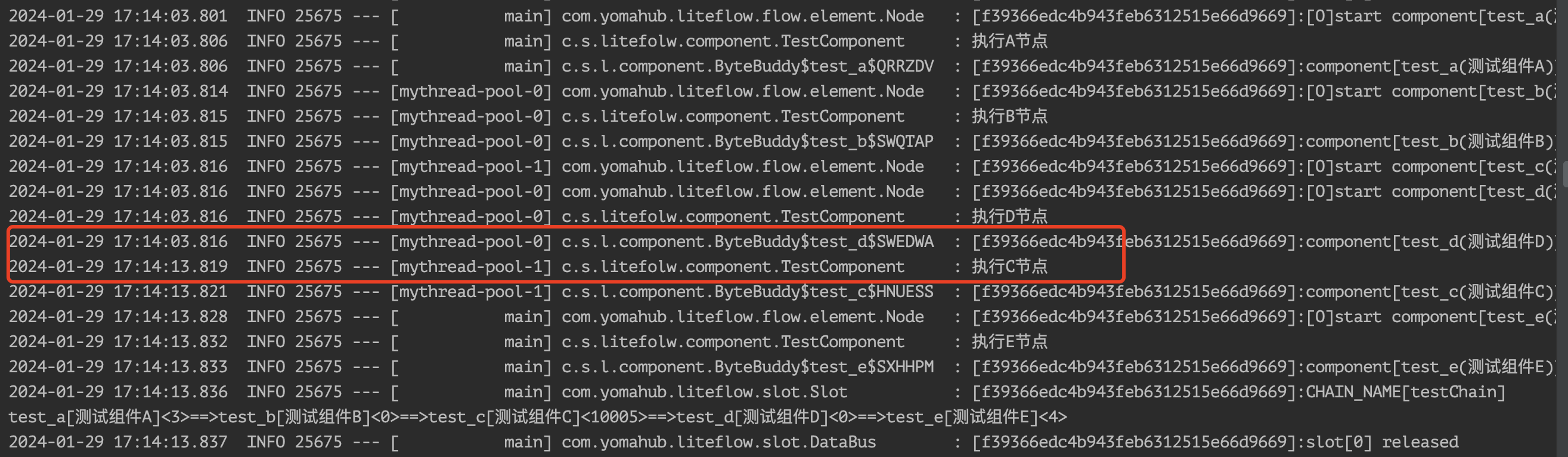
must子关键字在LiteFlow从v2.11.1版本之后才有。
- 选择编排
在实现业务逻辑过程中,我们常见的就是根据某种标识去进行不同的业务流程,通常我们也可以使用策略模式进行实现。在LiteFlow中可以通过SWITCH..TO()选择编排,即SWITCH中的流程返回后面TO中那个节点就会执行那个节点,我们只需要处理好SWITCH中条件于TO中分支的关系即可。增加一个Switch组件:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_SWITCH, nodeType = NodeTypeEnum.SWITCH, nodeId = "test_w", nodeName = "测试组件W")
public String processSwitch(NodeComponent nodeComponent){
log.info("执行W节点");
return "test_a";
}
然后我们规则编排:
<chain name="testSwitchChain">
SWITCH(test_w).TO(test_a, test_b, test_c, test_d, test_e);
</chain>
执行流程:

SWITCH还提供了子关键字DEFAULT,如果SWITCH返回的节点不是TO中的节点,则就走DEFAULT中指定的节点。
<chain name="testSwitchChain">
SWITCH(test_w).TO(test_a, test_b, test_c, test_d, test_e).DEFAULT(test_y);
</chain>

由选择组件章节中我们知道,SWITCH可以返回ID或者链路Tag,上述例子中返回的test_a就是一个节点ID(对应@LiteflowMethod中指定的nodeId中的值)。当让在规则中我们也可以给表达式设置一个id。LiteFlow中规定,每个表达式都可以有一个id值,你可以设置id值来设置一个表达式的id值。然后在选择组件里返回这个id即可。
<chain name="testSwitchChain">
SWITCH(test_w).TO(test_a, THEN(test_b, test_c, test_d).id("test_bcd"), test_e).DEFAULT(test_y);
</chain>
假如此时test_w表达式返回的是test_bcd,则流程就会执行test_b, test_c, test_d节点:
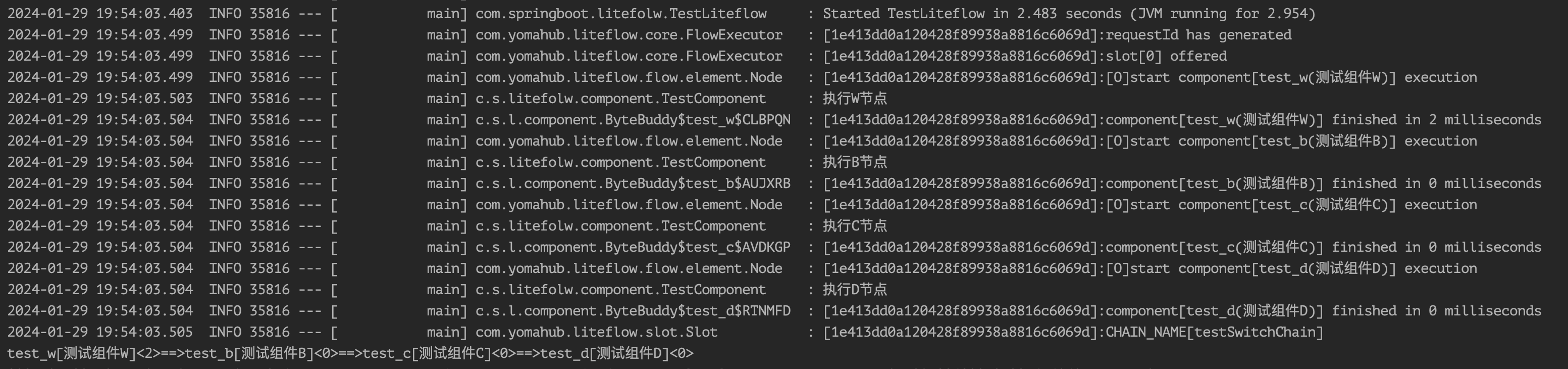
除了给表达式赋值id属性之外,还可以给表达式赋值tag属性。在SWITCH中返回tag。
<chain name="testSwitchChain">
SWITCH(test_w).TO(test_a, THEN(test_b, test_c, test_d).tag("test_tag"), test_e).DEFAULT(test_y);
</chain>
我们SWITCH组件中返回tag标签:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_SWITCH, nodeType = NodeTypeEnum.SWITCH, nodeId = "test_w", nodeName = "测试组件W")
public String processSwitch(NodeComponent nodeComponent){
log.info("执行W节点");
return "tag:test_tag";
}
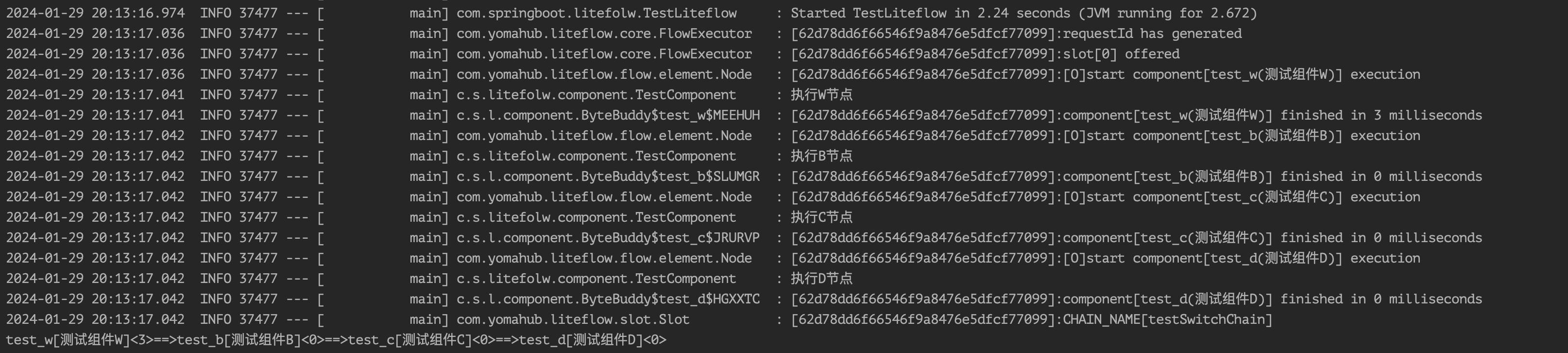
- 条件编排
条件编排类似Java中的if...else,它有IF,IF...ELIF,ELSE几种写法。其中IF以及ELIF中的表达式对应IF组件中返回的boolean结果。对与IF有二元表达式:
<chain name="testIfChain1">
IF(test_f, test_a);
</chain>
IF后面还可以跟ELSE。类似Java中的else。
<chain name="testIfChain">
IF(test_f, test_a).ELSE(test_b);
</chain>
IF还支持三元表达式,上面的二元表达式等价于如下三元表达式写法:
<chain name="testIfChain">
IF(test_f, test_a, test_b);
</chain>
上面两种表达式都可以解读为:如果test_f中返回true则执行test_a节点,否则执行test_b节点。
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_IF, nodeType = NodeTypeEnum.IF, nodeId = "test_f", nodeName = "测试组件F")
public boolean processF(NodeComponent nodeComponent){
log.info("执行F节点");
return true;
}

我们再看一下ELIF的写法,ELIF类似Java中的else if的写法,它的后面也可以跟ELSE。
<chain name="testIfChain">
IF(test_f, test_a).ELIF(test_x, test_b);
</chain>
我们在订一个test_x的IF组件:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_IF, nodeType = NodeTypeEnum.IF, nodeId = "test_f", nodeName = "测试组件F")
public boolean processF(NodeComponent nodeComponent){
log.info("执行F节点");
return false;
}
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_IF, nodeType = NodeTypeEnum.IF, nodeId = "test_x", nodeName = "测试组件X")
public boolean processX(NodeComponent nodeComponent){
log.info("执行X节点");
return true;
}
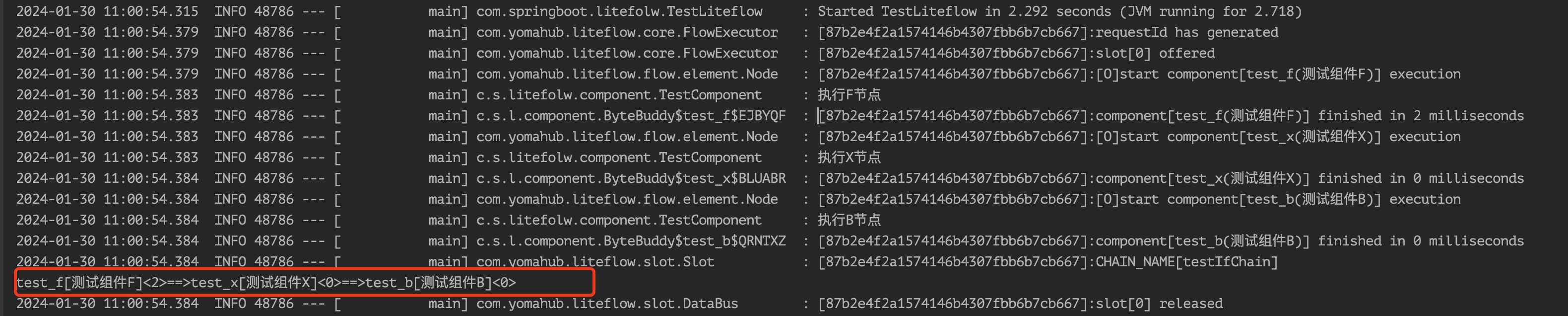
test_f节点返回false,所以不会执行test_a,继续执行test_x节点,返回true,则会执行test_b节点。
当然ELIF后面也可以使用ELSE。
<chain name="testIfChain">
IF(test_f, test_a).ELIF(test_x, test_b).ELSE(test_c);
</chain>
此时如果test_f以及test_x都返回false,就会走test_c。
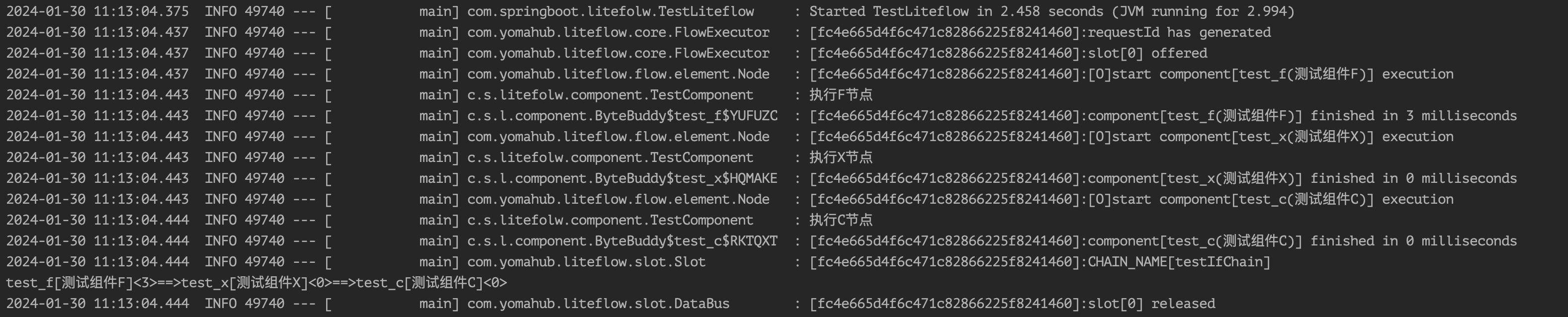
值得注意的是,当我们使用IF的二元表达式时才会去跟上ELIF以及ELSE。如果是三元表达式我们不可以使用ELIF以及ELSE,会报错。
在2.10.0以前可以使用,但是在
IF中的最后一个表达式会被ELIF或者`ELSE中的表达式
覆盖掉。本人只调研到了2.10.0,在这个版本中还是会报错。
- 循环编排
循环编排类似Java中的循环,分为次数循环(FOR...DO()),条件循环(WHILE...DO())以及迭代循环(ITERATOR...DO()),同时还涉及跳出循环编排(BREAK)。
我们定义一个固定次数的FOR循环:
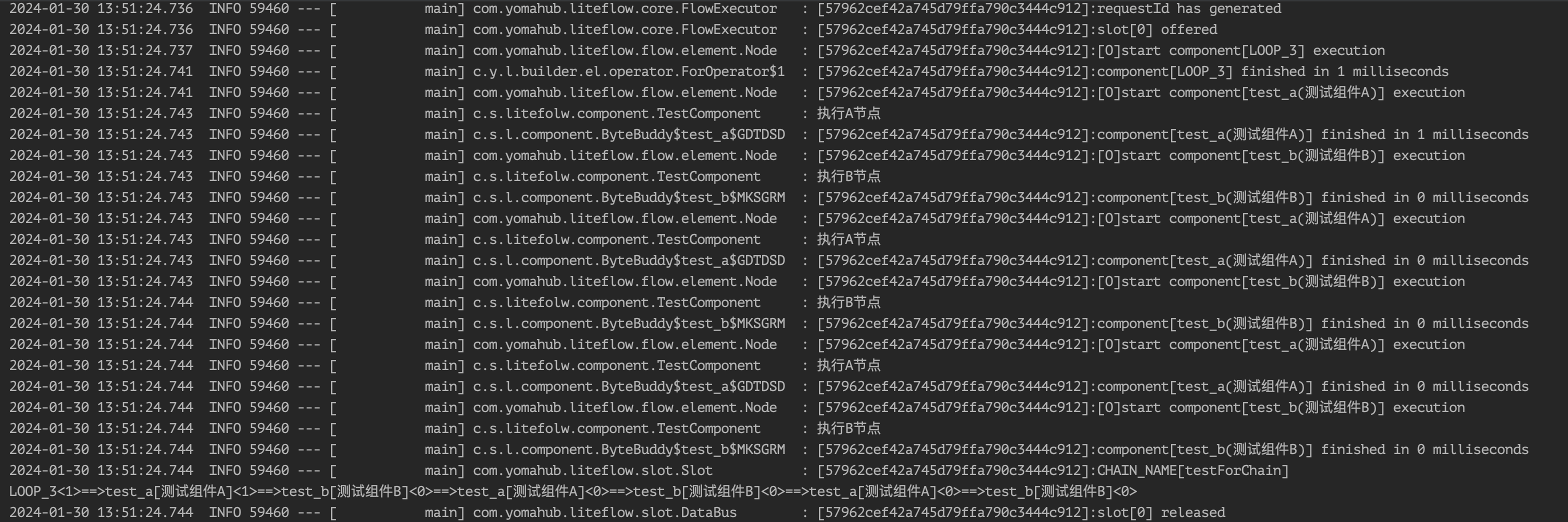
<chain name="testForChain">
FOR(3).DO(THEN(test_a, test_b));
</chain>
此时会将test_a,test_b循环执行3次。
当然实际开发中,我们需要搭配FOR循环组件使用,即在FOR循环中返回需要执行的次数:
<chain name="testForChain">
FOR(test_w).DO(THEN(test_a, test_b));
</chain>
假如test_w组件中返回次数是3,则执行效果如上固定次数。
接下来我们看一下WHILE条件循环,WHILE的表达式需要结合WHILE组件使用,返回一个
boolean类型的值,去控制循环的流程,如果为true则继续循环,否则结束循环。
<chain name="testWhileChain">
WHILE(test_h).DO(THEN(test_a, test_b));
</chain>
接下来我们继续看一下迭代循环ITERATOR,类似于Java中的for循环。这里我们要配合ITERATOR组件使用,返回一个集合的迭代器。
我们定义一个迭代循环编排:
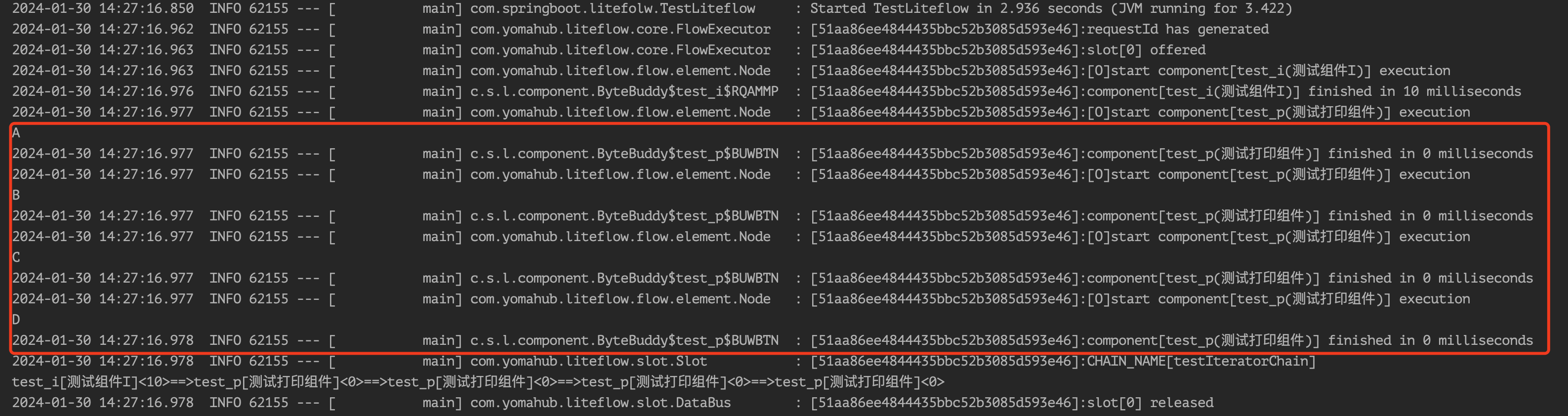
<chain name = "testIteratorChain">
ITERATOR(test_i).DO(test_p);
</chain>
然后我们在定义一个迭代组件以及一个普通组件用于打印集合中的元素:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_ITERATOR, nodeType = NodeTypeEnum.ITERATOR, nodeId = "test_i", nodeName = "测试组件I")
public Iterator<String> processI(NodeComponent nodeComponent){
List<String> list = Lists.newArrayList("A", "B", "C","D");
return list.iterator();
}
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "test_p", nodeName = "测试打印组件")
public void printData(NodeComponent nodeComponent){
String str = nodeComponent.getCurrLoopObj();
System.out.println(str);
}
有循环编排,就相应的要有跳出循环编排,我们可以使用BREAK编排,配合BREAK组件使用。
<chain name="testForChain">
FOR(test_j).DO(THEN(test_a, test_b)).BREAK(test_break);
</chain>
<chain name="testWhileChain">
WHILE(test_h).DO(THEN(test_a, test_b)).BREAK(test_break);
</chain>
<chain name = "testIteratorChain">
ITERATOR(test_i).DO(test_p).BREAK(test_break);
</chain>
我们以迭代循环跳出为例:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS_BREAK, nodeType = NodeTypeEnum.BREAK, nodeId = "test_break", nodeName = "测Break组件")
public boolean processBreak(NodeComponent nodeComponent){
String str = nodeComponent.getCurrLoopObj();
return Objects.equals("C", str);
}
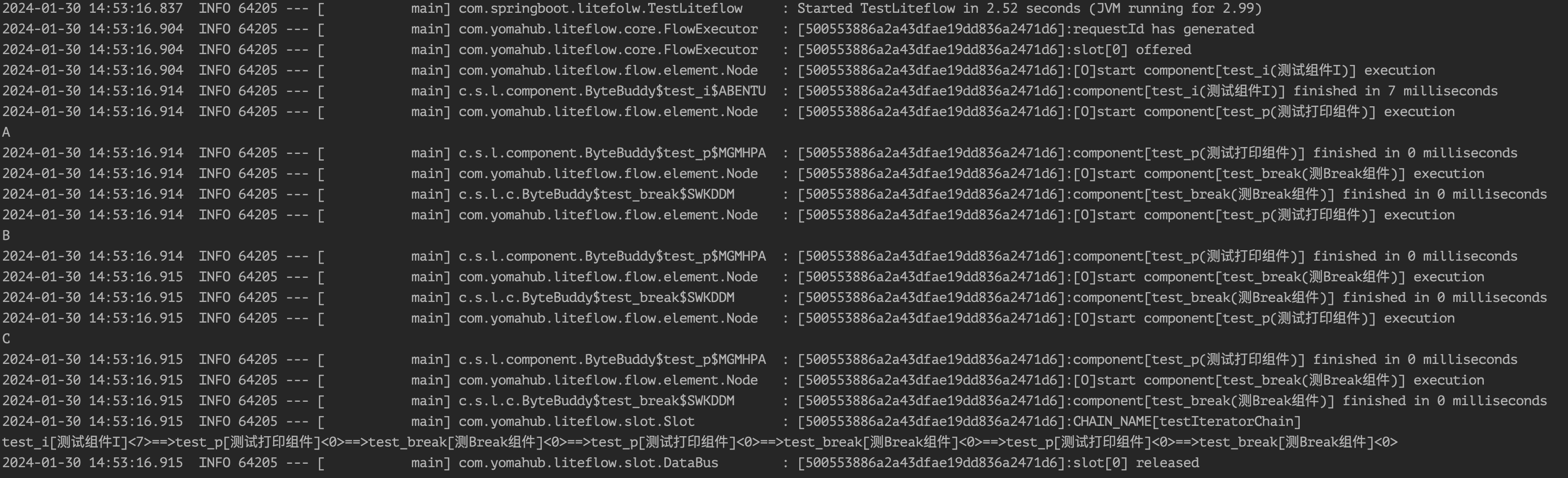
即执行到C元素时返回true,跳出循环。
LiteFlow从v2.9.0开始,提供了循环编排表达式组合。
- 异常捕获
EL表达式中还增加了异常捕获表达式,用于捕获节点中的异常。类似Java中的try...catch。用法为CATCH...DO(DO关键字非必须),如果在CATCH的表达式中捕获到了异常,可以在DO表达式中的节点进行处理,可以使用nodeComponent.getSlot().getException()获取异常信息。但是有一点我们需要注意,假如我们使用了CATCH,如果其中的节点中发生了异常,那么我们在流程执行的结果中也会看到流程执行成功的标识(isSuccess=true),可以理解,发生的异常被你捕获处理了。
<chain name="testCatchChain">
CATCH(
THEN(test_a, test_b)
).DO(test_catch);
</chain>
我们在test_b节点中手动抛出一个RuntimeException,在test_catch中使用nodeComponent.getSlot().getException()打印捕获到的异常,同时我们在流程执行结果中打印isSuccess看流程是否执行成功:
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "test_catch", nodeName = "测试Catch组件")
public void processCatch(NodeComponent nodeComponent){
log.error("执行Catch节点,捕获到了异常\n", nodeComponent.getSlot().getException());
}
@Test
public void testCatch(){
LiteflowResponse response = flowExecutor.execute2Resp("testCatchChain", null);
System.out.println(response.isSuccess() ? "执行成功" : "执行失败");
System.out.println("结果中的异常信息:" + response.getCause());
}


可以看到test_catch打印了异常信息,同时我们可以看到流程执行结果中返回执行成功,没有异常信息。

同时CATCH配合迭代循环还可以达到JavaforEach循环的continue的效果。
<chain name = "testIteratorCatchChain">
ITERATOR(test_i).DO(CATCH(THEN(test_pa, test_pb, test_pc)));
</chain>
我们在test_pb在打印C时抛出异常
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "test_pb", nodeName = "测试打印组件B")
public void printPB(NodeComponent nodeComponent){
String str = nodeComponent.getCurrLoopObj();
System.out.println("B组件打印:"+ str);
if (Objects.equals("B", str)){
throw new RuntimeException("B组件发生异常了。。。。");
}
}


此时没有执行C组件打印B,直接跳过了test_pc节点。
LiteFlow从2.10.0开始提供CATCH表达式
- 与或非表达式
与或非表达式即AND,OR,NOT表达式。可以用于返回boolean值的组件的编排。可以将若干个这种组件编排在一起返回应该boolean值进行后续流程的判断。
<chain name = "testAndOrNotChain">
IF(AND(test_f, test_x), test_a, test_c);
</chain>
此时只有test_f和test_x 节点都返回true,就会走test_a,否则走test_c。
<chain name = "testAndOrNotChain">
IF(OR(test_f, test_x), test_a, test_c);
</chain>
如果是OR,test_f和test_x 节点都返回false,就会走test_c,否则走test_c。
<chain name = "testAndOrNotChain">
IF(NOT(test_f), test_a, test_c);
</chain>
NOT即非的意思,如果test_f返回true,则就会走test_c节点,否则走test_a节点。
AND,OR,NOT三种表达式可以相互组合使用。但是只能用于返回boolean值的组件上。
- 子流程
在日常处理复杂业务时,流程编排的规则会嵌套很多层,可以想象一下那样的流程读起来也比较头疼,而且事实上我们在开发中是需要将复杂的流程业务去拆分成一个个独立的子流程去实现。
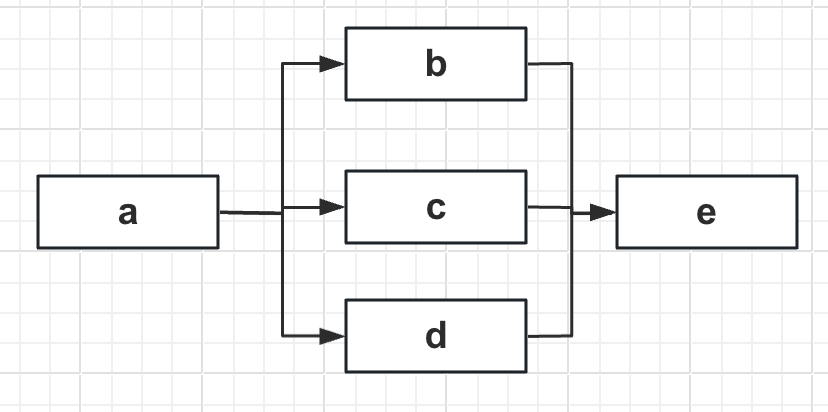
![image.png]()

如上图它的规则如下:
<chain name = "order_handle">
THEN(
SWITCH(order_x).TO(
THEN(
order_a,
order_c,
IF(
order_k,
THEN(
order_d,
order_f
),
order_e)
).id("to_c"),
THEN(
order_b,
order_c,
IF(
order_k,
THEN(
order_d,
order_f
),
order_e)
).id("to_b")
)
);
</chain>
这样写其实也可以,但是读起来理解起来不号。这时我们就可以子流程进行改造。我们按照to_c,to_b流程进行拆分。
<chain name="order_handle">
// 主流程
THEN(SWITCH(order_x).TO(THEN(to_c).id("to_c"), THEN(to_b).id("to_b")), order_h);
</chain>
<chain name="order_if">
IF(order_k, THEN(order_d, order_f), order_e);
</chain>
<chain name = "to_c">
THEN(order_a, order_c, order_if);
</chain>
<chain name = "to_b">
THEN(order_b, order_c, order_if);
</chain>
这样流程上就清晰了很多。
- 子变量
在复杂流程的编排上,我们不仅可以使用子流程,还可以使用子变量的方式。我们可以直接在流程中定义变量。如上述例子使用子变量可以改造为:
<chain name="order_handle">
// 定义一个if节点处理df/e
order_if = IF(order_k, THEN(order_d, order_f), order_e);
// 定义to_c的订单流程 用id标识流程为to_c
to_c = THEN(order_a, order_c, order_if).id("to_c");
// 定义to_b的订单流程 用id标识为流程to_b
to_b = THEN(order_b, order_c, order_if).id("to_b");
// 主流程
THEN(SWITCH(order_x).TO(to_c, to_b), order_h);
</chain>
这样也可以清晰。
- 其他
我们在上述一些示例中,每个语句后都加了分号:;,关于规则中的分号,我们链路中只有一条规则的时候(没有自变量)可以不加也可以运行,但是如果存在自变量,一定要在自变量中加上分号,否则汇报错。同时官方也建议不管是否存在子变量,都要加上分号。
另外,EL中我们使用//定义注释。
执行器
在上述的一些示例中,我们使用了flowExecutor去执行规则。FlowExecutor就是流程的执行器,是一个流程执行的触发点。在Spring或者SprigBoot环境下我们可以直接注入FlowExecutor进行使用。
FlowExecutor中提供同步以及异步两种类型的方法,同步方法直接返回LiteflowResponse,而异步返回的是Future<LiteflowResponse>。同步方法如下:
//参数为流程ID,无初始流程入参,上下文类型为默认的DefaultContext
public LiteflowResponse execute2Resp(String chainId)
//第一个参数为流程ID,第二个参数为流程入参。上下文类型为默认的DefaultContext
public LiteflowResponse execute2Resp(String chainId, Object param);
//第一个参数为流程ID,第二个参数为流程入参,后面可以传入多个上下文class
public LiteflowResponse execute2Resp(String chainId, Object param, Class<?>... contextBeanClazzArray)
//第一个参数为流程ID,第二个参数为流程入参,后面可以传入多个上下文的Bean
public LiteflowResponse execute2Resp(String chainId, Object param, Object... contextBeanArray)
// 第一个参数为流程ID,第二个参数为流程入参,第三个参数是用户的RequestId,后面可以传入多个上下文的Bean
public LiteflowResponse execute2RespWithRid(String chainId, Object param, String requestId, Class<?>... contextBeanClazzArray)
这里我们一定要使用自定义上下文传入,不要使用默认上下文。
而异步方法跟同步方法是一样的,只是他是无阻塞。
public Future<LiteflowResponse> execute2Future(String chainId, Object param, Object... contextBeanArray)
同时,执行器可以针对异步执行提供了可配置的线程池参数,
## FlowExecutor的execute2Future的线程数
liteflow.main-executor-works=64
还可以使用自定义线程池,如果使用自定义线程池必须实现ExecutorBuilder接口,实现ExecutorService buildExecutor()接口。
public class LiteFlowThreadPool implements ExecutorBuilder {
@Override
public ExecutorService buildExecutor() {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("mythread-pool-%s").build();
return new ThreadPoolExecutor(
// 核心线程数,即2个常开窗口
2,
// 最大的线程数,银行所有的窗口
5,
// 空闲时间
5,
TimeUnit.SECONDS,
// 工作队列
new LinkedBlockingQueue<>(5),
// 线程工厂
threadFactory,
// 拒绝策略
new ThreadPoolExecutor.AbortPolicy()
);
}
}
关于Java线程池的配置详解,请参考这篇文章:重温Java基础(二)之Java线程池最全详解
我们可以通过LiteFlow的配置信息去设置:
## FlowExecutor的execute2Future的自定义线程池的路径
liteflow.main-executor-class= com.springboot.litefolw.config.LiteFlowThreadPool
通过上述配置文件配置的信息,对全局的FlowExecutor都会生效,假如我们相对某一个执行器定义线程池内容,可以使用LiteFlowConfig类去的定义(通过配置文件中配置信息也会进入到这个类里)。
LiteflowConfig liteflowConfig = flowExecutor.getLiteflowConfig();
// FlowExecutor的execute2Future的自定义线程池的路径
liteflowConfig.setMainExecutorClass("com.springboot.litefolw.config.LiteFlowThreadPool");
// FlowExecutor的execute2Future的自定义线程池的路径
liteflowConfig.setMainExecutorWorks(64);
这里不建议new一个LiteflowConfig去设置配置信息,这样可能会导致配置文件中的一些默认配置信息丢失。
在一个流程执行时,我们需要传入一些参数例如订单号,账户信息等,这些信息会做初始参数传入到流程中。在执行器中我们可以使用上述FlowExecutor的方法中的第二个参数(Object param)传入流程入参参数。流程入参可以是任何对象,实际开发中,我们会将自己封装初始化好的Bean传入,然后可以在流程中使用this.getRequestData()或者nodeCompoent.getRequestData()。
DataRequest dataRequest = DataRequest.builder().iteratorRequestList(Lists.newArrayList()).build();
LiteflowResponse response =
// 流程传入参数
flowExecutor.execute2Resp("testIteratorCatchChain", dataRequest);
在流程中获取入参参数:
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
DataRequest dataRequest = this.getRequestData();
}
}
@Slf4j
@LiteflowComponent
public class TestComponent {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "test_a", nodeName = "测试组件A")
public void processA(NodeComponent nodeComponent){
log.info("执行A节点");
DataRequest dataRequest = nodeComponent.getRequestData();
}
}
理论上来说,流程入参可以是任何对象,但是我们不应该把数据上下文的实例当做参数传入。流程参数跟数据上下文是两个实例对象,流程入参只能通过
this.getRequestData()去拿。
最后我们来说一下流程执行的结果LiteflowResponse。异步执行的流程可以通过future.get()获取。我们简单介绍一下其中常用的一些方法:
public class LiteflowResponse {
// 判断流程是否执行成功
public boolean isSuccess();
// 如果流程执行不成功,可以获取流程的异常信息,这个跟isSuccess()使用,很有用
public Exception getCause();
// 获取流程的执行步骤
public Map<String, List<CmpStep>> getExecuteSteps();
// 获取流程的执行的队列信息
public Queue<CmpStep> getRollbackStepQueue();
// 获取流程的执行步骤的字符串信息。这个值在流程执行结束后,liteflow日志也会自动打印
public String getExecuteStepStr();
// 获取数据上下文信息
public <T> T getContextBean(Class<T> contextBeanClazz);
}
数据上下文
数据上下文对与整个LiteFlow来说是非常重要的,从LiteFlow的简介中我们知道LiteFlow的主要功能是业务解耦,那么解耦中很重要的一步就是数据解耦。要做编排,就要消除各个组件中的差异性,组件不接收业务参数,也不会返回业务数据,每个组件只需要从数据上下文中获取自己关心的数据,不用关心此数据是由谁提供的,同样的,每个组件也只需要把自己执行所产生的结果数据放到数据上下文中,也不用关心此数据到底是提供给谁用的。这样就在一定程度上做到了数据解耦。数据上下文进入流程中后,整个链路中的任一节点都可以取到。不同的流程,数据上下文实例是完全隔离开的。
LiteFlow虽然也提供了默认的数据上下文DefaultContext,但是实际开发中不建议使用。我们要传入自己自定义的数据上下文对象,同流程入参,我们可以使用任意的Bean作为数据上下文传入到流程中。我们可以定义好若干个数据上下文对象的class传入到流程中,LiteFlow会在调用时进行初始化,给这个上下文分配唯一的实例。
// 传入一个
LiteflowResponse response = flowExecutor.execute2Resp("chain1", new DataRequest(), DataContext.class);
// 传入多个
LiteflowResponse response = flowExecutor.execute2Resp("chain1", new DataRequest(), DataContext.class, OrderContext.class);
我们还可以将已经初始化好的Bean作为数据上下文传入到流程当中:
DataContext dataContext = new DataContext();
// 传入一个
LiteflowResponse response = flowExecutor.execute2Resp("chain1", new DataRequest(), dataContext);
// 传入多个
OrderContext orderContext = new OrderContext();
LiteflowResponse response = flowExecutor.execute2Resp("chain1", new DataRequest(), dataContext, orderContext);
但是有一点要非常注意:框架并不支持上下文bean和class混传,你要么都传bean,要么都传class。
然后我们就可以在链路的任意节点中通过以下方式获取数据上下文:
@Slf4j
@LiteflowComponent
public class TestComponent {
@LiteflowMethod(value = LiteFlowMethodEnum.PROCESS, nodeType = NodeTypeEnum.COMMON, nodeId = "test_a", nodeName = "测试组件A")
public void processA(NodeComponent nodeComponent){
log.info("执行A节点");
DataContext dataContext = nodeComponent.getContextBean(DataContext.class);
OrderContext orderContext = nodeComponent.getContextBean(OrderContext.class);
}
}
@LiteflowComponent("a")
public class AComponent extends NodeComponent {
@Override
public void process() throws Exception {
DataContext dataContext = this.getContextBean(DataContext.class);
OrderContext orderContext = this.getContextBean(OrderContext.class);
}
}
到此,SpringBoot环境下LiteFlow的一些基本概念就介绍完了,大家可以按照这些概念实现一个demo去体验LiteFlow那解耦,以及流程编排那种特爽的柑橘。当然大家也可以参考这篇文章去实现demo:SpringBoot+LiteFlow优雅解耦复杂核心业务
后面我们在介绍LiteFlow的一些高级特性,例如:组件降级,组件继承,组建回滚,热刷新,以及使用代码构建规则,使用脚本构建组件,还有使用Nacos,Redis作为规则文件源等。
本文已收录于我的个人博客:码农Academy的博客,专注分享Java技术干货,包括Java基础、Spring Boot、Spring Cloud、Mysql、Redis、Elasticsearch、中间件、架构设计、面试题、程序员攻略等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号