Netty入门(四)ByteBuf 字节级别的操作
Netty 中使用 ByteBuf 代替 Java NIO 提供的 ByteBuffer 作为字节的容器。
一、索引
ByteBuf 提供两个指针变量支持读和写操作,读操作使用 readerIndex,写操作使用 writerIndex。如下图:

- 可丢弃字节,因为它们已经被读
- 可读字节,已写入但还没有被读取
- 可写字节
二、索引管理
- 调用 markReaderIndex(), markWriterIndex(), resetReaderIndex() 和 resetWriterIndex() 来设置和重新定位 readerIndex 和 writerIndex,
- 调用 readerIndex(int) 或 writerIndex(int) 将指针移动到指定的位置
- 调用 clear() 同时设置 readerIndex 和 writerIndex 为 0
三、查询操作
可以使用以 ByteBufProcessor 为参数的方法,下面例子实现了寻找一个回车符( \r ):
1 ByteBuf in = (ByteBuf)msg; 2 int index = in.forEachByte(ByteProcessor.FIND_CR);
四、衍生的缓冲区
slice 方法和 copy 方法都能实现拷贝功能,但是它们有不同之处,下面两个例子说明了它们的不同之处。
先看看 slice 的例子:
1 Charset utf8 = Charset.forName("UTF-8"); 2 ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); 3 4 ByteBuf sliced = buf.slice(0, 14); // 创建从0开始到14的新slice 5 System.out.println(sliced.toString(utf8)); //打印 Netty in Action 6 7 buf.setByte(0, (byte) 'J'); //更新索引为0的字节 8 // 断言成功,说明slice之后两段数据共享 9 assert buf.getByte(0) == sliced.getByte(0);
这个说明 slice 返回的是原缓冲区的一个副本,共享同一片数据。因此若需要操作某段数据,使用 slice 方法。
下面来看看 copy 方法是如何不同的:
1 Charset utf8 = Charset.forName("UTF-8"); 2 ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); 3 4 ByteBuf copy = buf.copy(0, 14); // 注意这里使用了copy 5 System.out.println(copy.toString(utf8)); 6 7 buf.setByte(0, (byte) 'J'); 8 // 断言成功,说明原数据修改对copy不影响 9 assert buf.getByte(0) != copy.getByte(0);
可以看到,代码几乎是相同的,但所衍生的 ByteBuf 效果是不同的。
五、读 / 写操作
读 / 写操作主要有两类:
- get() / set() 操作:从给定的索引开始,写索引和读索引保持不变
- read() / write() 操作:从给定的索引开始,根据字节访问的数量,递增当前的写索引或读索引。
需要特别注意上述两类操作对于读索引和写索引的影响。
常见的 get() 操作如下:
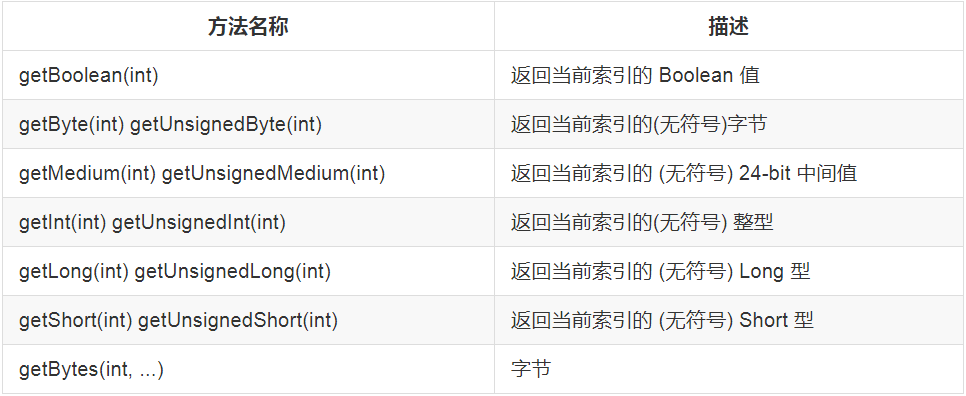
常见的 set() 操作如下:
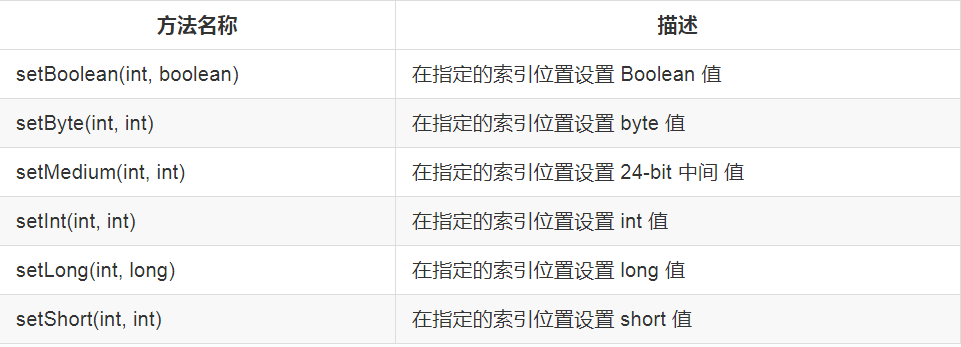
常见的 read() 操作如下:

每个 read() 方法都对应一个 write() 方法,如下:
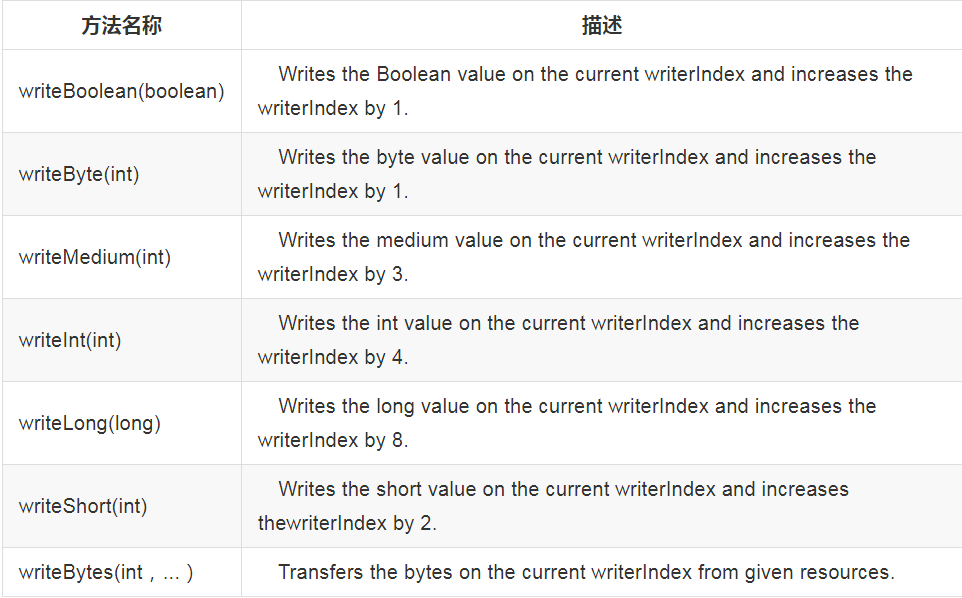
六、更多操作
还有一些比较常用的方法如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号