
非刚性人脸跟踪 —— 人脸跟踪
人脸跟踪问题可认为是寻找一种高效和鲁棒性的方法,它能将各种面部特征的单独检测与这些特征的几何依赖性结合起来,已得到连续帧中每幅图像面部特征位置的精确估计。基于此,需仔细考虑几何依赖性的必要性。下图为用几何约束和不用几何约束所检测出来的面部特征。

该结果清楚地说明利用空间上面部特征的相互依赖性非常有好处。两种方法的相对性能会因检测结果噪声过多而受影响,其原因在于对于每一个每一个面部特征的响应矩阵达到最大值时并不总是在正确的位置。但面部特征检测器要解决因图象噪声、光照变化、表情变化等带来的问题,仅有的方法是利用特征之间彼此共享的几何关系。
有一个特别简单,但非常有效的方法可将面部几何依赖加到跟踪过程中,该方法将人脸特征提取的结果投影到形状模型的线性子空间(shape model),也就是最小化原始点集到其在人脸子空间最接近合理形状分布的投影点集的距离。(就是说,把通过模版匹配检测到的原始点集 A 投影到人脸子空间产生新的点集 B,再按照某种约束规则,通过对 A 迭代变化,使得 A’到 B 的距离最小)。
一、人脸跟踪实现
人脸跟踪算法的实现可以在 face_tracker 类中找到(见 face_tracker.cpp 和 face_tracker.hpp 文件)。下面这段代码来自其头文件,这展示了该类的主要功能:
1 class face_tracker{ //face tracking class 2 public: 3 bool tracking; //are we in tracking mode? 4 fps_timer timer; // 用来保存帧速率的变化 5 vector<Point2f> points; //current tracked points 6 face_detector detector; //detector for initialisation 7 shape_model smodel; //shape model 8 patch_models pmodel; //feature detectors 9 10 face_tracker(){tracking = false;} 11 12 int //0 = failure 13 track(const Mat &im, //image containing face 14 const face_tracker_params &p = //fitting parameters 15 face_tracker_params()); //default tracking parameters 16 17 void 18 reset(){ //reset tracker 19 tracking = false; timer.reset(); 20 } 21 .... 22 protected: 23 vector<Point2f> //points for fitted face in image 24 fit(const Mat &image, //image containing face 25 const vector<Point2f> &init, //initial point estimates 26 const Size ssize = Size(21,21), //search region size 27 const bool robust = false, //use robust fitting? 28 const int itol = 10, //maximum number of iterations to try 29 const float ftol = 1e-3); //convergence tolerance 30 };
face_tracker::track 函数,有两种功能。当 traking 标志位为 false 时,程序属于构建模型(detectmode)阶段,为第一帧或下一帧图像初始化的人脸特征,所用技术就是上面上一节所讲的;当 tracking 标志位为 true 时,则根据上一帧人脸特征点的位置估计下一帧的人脸特征,这个操作主要由 fit 函数完成。代码如下:
1 int 2 face_tracker:: 3 track(const Mat &im,const face_tracker_params &p) 4 { 5 //convert image to greyscale 6 Mat gray; if(im.channels()==1)gray = im; else cvtColor(im,gray,CV_RGB2GRAY); 7 8 //initialise,为第一帧或下一帧初始化人脸特征 9 if(!tracking) 10 points = detector.detect(gray,p.scaleFactor,p.minNeighbours,p.minSize); 11 if((int)points.size() != smodel.npts())return 0; 12 13 //fit,通过迭代缩小的搜索范围,估计当前帧中的人脸特征点 14 for(int level = 0; level < int(p.ssize.size()); level++) 15 points = this->fit(gray,points,p.ssize[level],p.robust,p.itol,p.ftol); 16 17 //set tracking flag and increment timer 18 tracking = true; timer.increment(); return 1; 19 }
face_tracker::fit 函数的主要功能:给定一帧图像及上一帧人脸特征点集,在当前图像上搜索该点集附近的人脸特征,并产生新的人脸特征点集。
1 vector<Point2f> 2 face_tracker:: 3 fit(const Mat &image, // 当前帧灰度图像 4 const vector<Point2f> &init, // 上一帧人脸特征点集(几何位置) 5 const Size ssize, // 搜索区域大小 6 const bool robust, // 标志位,决定是否采用 robustmodel fitting 流程,应对人脸特征的孤立点 7 const int itol, // robustmodel fitting 迭代上限 8 const float ftol) // 迭代收敛判断阈值 9 { 10 int n = smodel.npts(); // number of points int the shape model 11 assert((int(init.size())==n) && (pmodel.n_patches()==n)); 12 smodel.calc_params(init); vector<Point2f> pts = smodel.calc_shape(); 13 14 //find facial features in image around current estimates 15 vector<Point2f> peaks = pmodel.calc_peaks(image,pts,ssize); 16 17 //optimise 18 if(!robust){ 19 smodel.calc_params(peaks); //compute shape model parameters 20 pts = smodel.calc_shape(); //update shape 21 }else{ 22 Mat weight(n,1,CV_32F),weight_sort(n,1,CV_32F); 23 vector<Point2f> pts_old = pts; 24 for(int iter = 0; iter < itol; iter++){ 25 //compute robust weight 26 for(int i = 0; i < n; i++)weight.fl(i) = norm(pts[i] - peaks[i]); 27 cv::sort(weight,weight_sort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING); 28 double var = 1.4826*weight_sort.fl(n/2); if(var < 0.1)var = 0.1; 29 pow(weight,2,weight); weight *= -0.5/(var*var); cv::exp(weight,weight); 30 31 //compute shape model parameters 32 smodel.calc_params(peaks,weight); 33 34 //update shape 35 pts = smodel.calc_shape(); 36 37 //check for convergence 38 float v = 0; for(int i = 0; i < n; i++)v += norm(pts[i]-pts_old[i]); 39 if(v < ftol)break; else pts_old = pts; 40 } 41 }return pts; 42 }
上面代码中,有两个函数:
-
- shape_model::calc_param,为了得到合理的人脸总空间投影,我们需要求参数向量 p,该函数通过人脸子空间投影坐标集合 pts 与人脸特征空间标准基 V,计算得到参数向量
1 void 2 shape_model:: 3 calc_params(const vector<Point2f> &pts,const Mat weight,const float c_factor) 4 { 5 int n = pts.size(); assert(V.rows == 2*n); 6 Mat s = Mat(pts).reshape(1,2*n); //point set to vector format 7 if(weight.empty())p = V.t()*s; //simple projection 8 else{ //scaled projection 9 if(weight.rows != n){cout << "Invalid weighting matrix" << endl; abort();} 10 int K = V.cols; Mat H = Mat::zeros(K,K,CV_32F),g = Mat::zeros(K,1,CV_32F); 11 for(int i = 0; i < n; i++){ 12 Mat v = V(Rect(0,2*i,K,2)); float w = weight.fl(i); 13 H += w*v.t()*v; g += w*v.t()*Mat(pts[i]); 14 } 15 solve(H,g,p,DECOMP_SVD); 16 }this->clamp(c_factor); //clamp resulting parameters 17 }
- shape_model::calc_peaks,根据人脸子空间点集在当前图像内搜索人脸特征,并产生新的人脸特征位置估计
1 vector<Point2f> 2 patch_models:: 3 calc_peaks(const Mat &im, // 当前包含人脸的灰度图像 4 const vector<Point2f> &points, // 前一帧估计的人脸特征点集在人脸子空间投影坐标集合 5 const Size ssize) // 搜索区域大小 6 { 7 int n = points.size(); assert(n == int(patches.size())); 8 Mat pt = Mat(points).reshape(1,2*n); 9 Mat S = this->calc_simil(pt); // 计算当前点集到人脸参考模型的变化矩阵 10 Mat Si = this->inv_simil(S); // 对矩阵 S 求逆 11 // 人脸子空间坐标经过仿射变换转成图像空间中的坐标 12 vector<Point2f> pts = this->apply_simil(Si,points); 13 for(int i = 0; i < n; i++){ 14 Size wsize = ssize + patches[i].patch_size(); Mat A(2,3,CV_32F); 15 A.fl(0,0) = S.fl(0,0); A.fl(0,1) = S.fl(0,1); 16 A.fl(1,0) = S.fl(1,0); A.fl(1,1) = S.fl(1,1); 17 A.fl(0,2) = pt.fl(2*i ) - 18 (A.fl(0,0) * (wsize.width-1)/2 + A.fl(0,1)*(wsize.height-1)/2); 19 A.fl(1,2) = pt.fl(2*i+1) - 20 (A.fl(1,0) * (wsize.width-1)/2 + A.fl(1,1)*(wsize.height-1)/2); 21 Mat I; warpAffine(im,I,A,wsize,INTER_LINEAR+WARP_INVERSE_MAP); 22 // 搜索人脸特征的匹配位置 23 Mat R = patches[i].calc_response(I,false); 24 Point maxLoc; minMaxLoc(R,0,0,0,&maxLoc); 25 // 修正人脸特征估计点位置 26 pts[i] = Point2f(pts[i].x + maxLoc.x - 0.5*ssize.width, 27 pts[i].y + maxLoc.y - 0.5*ssize.height); 28 } 29 // 再次将图像中的坐标投影到人脸特征子空间中,作为下一帧特征估计点位置 30 return this->apply_simil(S,pts); 31 }
- shape_model::calc_param,为了得到合理的人脸总空间投影,我们需要求参数向量 p,该函数通过人脸子空间投影坐标集合 pts 与人脸特征空间标准基 V,计算得到参数向量
在对每帧图像进行人脸跟踪时,track 函数都会通过 fit 函数迭代产生多个人脸子空间坐标集合,并且每次迭代的时候,搜索区域都在减小。在迭代过程中,可能会产生很多孤立的特征点(错误估计点)。为了得到更精确的人脸跟踪效果,如果存在孤立点时,仍采用简单投影,会严重影响跟踪效果。因此,在计算投影参数 calc_param 时引入了权重,搞了一套 robust model fitting 流程,特意去除孤立点。
二、训练与可视化
训练一个 face_tracker 对象不会涉及任何的学习过程。在 train_face_tracker.cpp 中简单实现了该功能,代码如下:
1 //create face tracker model 2 face_tracker tracker; 3 tracker.smodel = load_ft<shape_model>(argv[1]); // 加载 shape_model 对象 4 tracker.pmodel = load_ft<patch_models>(argv[2]); // 加载 patch_model 对象 5 tracker.detector = load_ft<face_detector>(argv[3]); // 加载 face_detector 对象 6 7 //save face tracker 8 save_ft<face_tracker>(argv[4],tracker); // 保存 face_tracker 对象
将 face_tracker 对象保存到 tracker_model.yaml 中,如下:
在 visualize_face_tracker.cpp 文件中,可视化程序将 cv::VideoCapture 类从摄像机或视频文件的图像流作为输入,该程序有一个简单的循环,该循环在读到图像流最后或用户按 Q 键就会终止,否则就会跟踪出现的每一帧。用户随时可按 D 键来重置跟踪选项。主要代码如下:
1 while(cam.get(CV_CAP_PROP_POS_AVI_RATIO) < 0.999999){ 2 Mat im; cam >> im; 3 if(tracker.track(im,p))tracker.draw(im); 4 draw_string(im,"d - redetection"); 5 tracker.timer.display_fps(im,Point(1,im.rows-1)); 6 imshow("face tracker",im); 7 int c = waitKey(10); 8 if(c == 'q')break; 9 else if(c == 'd')tracker.reset(); 10 }
运行效果如下:
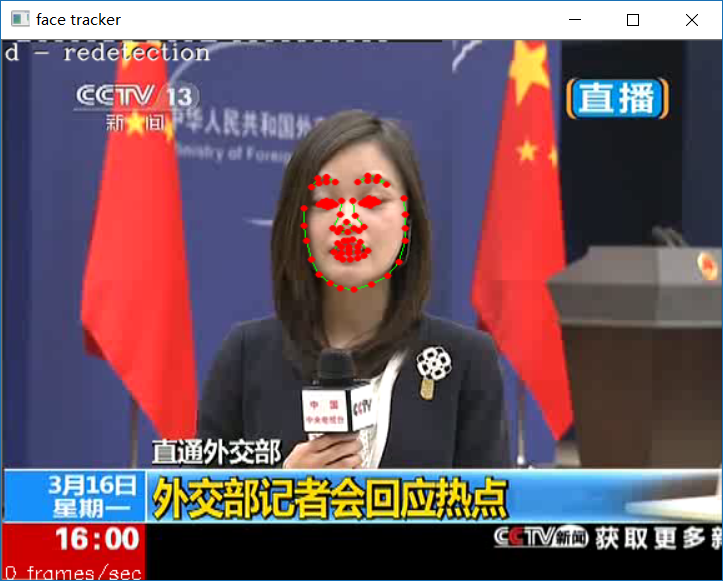
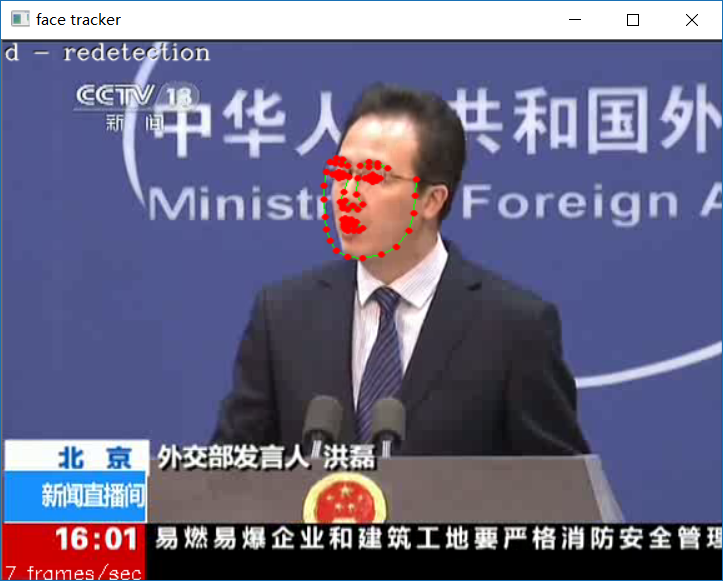
Ending !!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号