机器学习之交叉熵和相对熵的概念理解
通过三个例子来讲解熵的概念
爸爸需要让小明猜球的颜色,如果猜中了,就停止继续猜,如果没有猜对则一直继续猜。
题目1:爸爸拿来一个箱子,跟小明说:里面有橙、紫、蓝及青四种颜色的小球任意个,各颜色小球的占比不清楚,现在我从中拿出一个小球,你猜我手中的小球是什么颜色?

从上面的图中可以发现,小明首先的假设会是四个球的出现几率都是一样的为1/4,但是只要猜两次都会终止猜的游戏,可以得出最终的结论。
如何计算小明预期的猜球次数呢,其实就是要求出相应的期望:
H = 1/4 * 2 + 1/4 * 2 + 1/4 * 2 + 1/4 * 2 = 2
题目2:爸爸还是拿来一个箱子,跟小明说:箱子里面有小球任意个,但其中1/2是橙色球,1/4是紫色球,1/8是蓝色球及1/8是青色球。我从中拿出一个球,你猜我手中的球是什么颜色的?
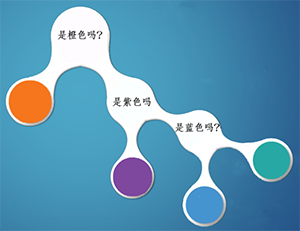
比如橙色占比二分之一,如果我猜橙色,很有可能第一次就猜中了。所以,根据策略2,1/2的概率是橙色球,小明需要猜一次,1/4的概率是紫色球,小明需要猜两次,1/8的概率是蓝色球,小明需要猜三次,1/8的概率是青色球,小明需要猜三次,所以小明猜题次数的期望为:
H = 1/2 * 1 + 1/4 * 2 + 1/8 * 3 + 1/8 * 3= 1.75
题目3:爸爸跟小明说:里面的球都是橙色,现在我从中拿出一个,你猜我手中的球是什么颜色?
小明值得肯定是橙色,只需要猜0次
上面三个题目表现出这样一种现象:针对特定概率为p的小球,需要猜球的次数是=
例如题目2中,1/4是紫色球,=2次。
那么,针对整个系统,有多种可能发生的事件,预期的猜题次数为: ,这就是信息熵。
信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。
上面题目1的熵 > 题目2的熵 > 题目3的熵。在题目1中,小明对整个系统一无所知,只能假设所有的情况出现的概率都是均等的,此时的熵是最大的。
题目2中,小明知道了橙色小球出现的概率是1/2及其他小球各自出现的概率,说明小明对这个系统有一定的了解,所以系统的不确定性自然会降低,所以熵小于2。题目3中,小明已经知道箱子中肯定是橙色球,爸爸手中的球肯定是橙色的,因而整个系统的不确定性为0,也就是熵为0。所以,在什么都不知道的情况下,熵会最大。
所以,每一个系统都会有一个真实的概率分布,也叫真实分布,题目1的真实分布为(1/4,1/4,1/4,1/4),题目2的真实分布为(1/2,1/4,1/8,1/8),而根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,而这个代价大小就是信息熵,记住,信息熵衡量了系统的不确定性,而我们要消除这个不确定性,所要付出的最小努力(猜题次数、编码长度等)的大小就是信息熵。
现在回到题目2,假设小明用了策略1,也就是图1里面的把四种可能性都定为1/4的策略,爸爸已经告诉小明这些小球的真实分布是(1/2,1/4, 1/8,1/8),但小明所选择的策略却认为所有的小球出现的概率相同,相当于忽略了爸爸告诉小明关于箱子中各小球的真实分布,而仍旧认为所有小球出现的概率是一样的,认为小球的分布为(1/4,1/4,1/4,1/4),这个分布就是非真实分布。
此时,小明猜中任何一种颜色的小球都需要猜两次,即
H=1/2 * 2 + 1/4 * 2 + 1/8 * 2 + 1/8 * 2 = 2。
很明显,针对题目2,使用策略1是一个坏的选择,因为需要猜题的次数增加了,从1.75变成了2。因此,当我们知道根据系统的真实分布制定最优策略去消除系统的不确定性时,我们所付出的努力是最小的,但是很难一开始就用真实分布去消除系统的不确定性,往往我们会用非真实分布去衡量。
那么,当我们使用非最优策略消除系统的不确定性,所需要付出的努力的大小我们该如何去衡量呢?
这就需要引入交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
交叉熵
交叉熵的公式为,其中pk表示真实分布,qk表示非真实分布。
例如上面所讲的将策略1用于题目2,真实分布,非真实分布
,交叉熵就为
,比最优策略的1.75要大了。
因此,交叉熵越低,这个策略就越好,最低的交叉熵也就是使用了真实分布所计算出来的信息熵,因为此时,交叉熵 = 信息熵。
这也是为什么在机器学习中的分类算法中,我们总是最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
最后,我们如何去衡量不同策略之间的差异呢?这就需要用到相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异,即:
现在,假设我们想知道某个策略和最优策略之间的差异,我们就可以用相对熵来衡量这两者之间的差异。即,相对熵 = 某个策略的交叉熵 - 信息熵(根据系统真实分布计算而得的信息熵,为最优策略),公式如下:。
所以将策略1用于题目2,所产生的相对熵为2 - 1.75 = 0.25。
所以个人的理解是,将自己的策略用于某一个模型的时候,需要保证交叉熵尽可能小,同时还要保证相对熵也是尽可能小的,也就是要求在相对熵最小的情况下,让交叉熵最优化,才是最接近真实分布的策略。
本文章的内容参考引用了https://www.zhihu.com/question/41252833。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号