
如何判断一个对象占用多少字节?
如何判断一个对象占用多少字节?这是我之前遇到的一个面试题,在这里分享一下。
要判断一个对象占用多少字节,对象内存布局是必须要了解的。
对象内存布局
在HotSpot虚拟机里对象内存布局分为3个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)

对象头
对象头包括两部分信息:
- 第一部分用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。这部分数据的长度在32位和64位的虚拟机(未开启压缩指针) 中分别为32个比特和64个比特, 官方称它为“Mark Word”。
- 另外一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
- 如果对象是一个 java 数组,那么在对象头中还有一块用于记录数组长度的数据。
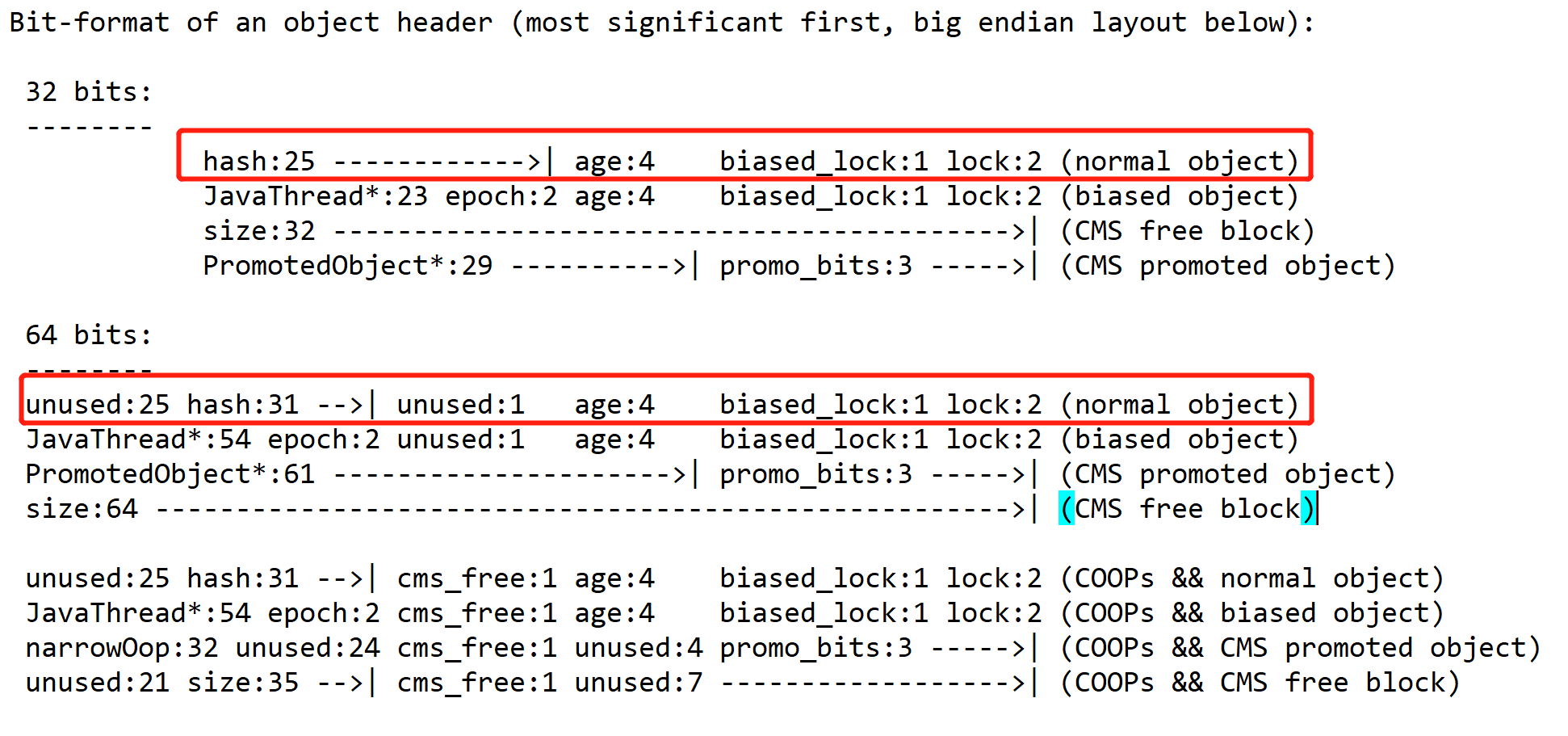
Mark Word的32个比特存储空间中的25个比特用于存储对象哈希码, 4个比特用于存储对象分代年龄,2个比特用于存储锁标志位,1个比特固定为0。
HotSpot源码 markOop.hpp 注释片段,描述了Mark Word的内存布局:
实例数据
实例数据部分是对象真正存储的有效信息,即我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。HotSpot虚拟机默认的分配顺序为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers,OOPs),从以上默认的分配策略中可以看到,相同宽度的字段总是被分配到一起存放,在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。
对齐填充
对齐填充不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。 由于HotSpot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是任何对象的大小都必须是8字节的整数倍。 对象头部分已经被精心设计成正好是8字节的倍数(1倍或者2倍),因此,如果对象实例数据部分没有对齐的话, 就需要通过对齐填充来补全。
实践出真知
下面来通过openjdk jol 来解读对象占用多少字节。
JOL
JOL(Java Object Layout)是用于分析 JVM 中对象布局方案的微型工具箱。这些工具大量使用 Unsafe、JVMTI 和 Serviceability Agent (SA) 来解码实际的 对象布局、占用空间和引用。这使得 JOL 比其他依赖堆转储、规范假设等的工具更准确。
示例
- 创建一个maven项目,引入依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.16</version>
</dependency>
- 新建一个类
@Data
public class BaseEntity {
private long id;
private double amount;
private int updateUserId;
private float f;
private char c;
private byte b;
private boolean bb;
private short ss;
private long[] list;
private String s;
private Long count;
}
- 测试
public class ObjectHeaderTest {
public static void main(String[] args) {
BaseEntity baseEntity = new BaseEntity();
String toPrintable = ClassLayout.parseInstance(baseEntity).toPrintable();
System.out.println(toPrintable);
}
}
打印结果:
site.sunlong.obj.BaseEntity object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0xf800c143
12 4 int BaseEntity.updateUserId 0
16 8 long BaseEntity.id 0
24 8 double BaseEntity.amount 0.0
32 4 float BaseEntity.f 0.0
36 2 char BaseEntity.c
38 2 short BaseEntity.ss 0
40 1 byte BaseEntity.b 0
41 1 boolean BaseEntity.bb false
42 2 (alignment/padding gap)
44 4 long[] BaseEntity.list null
48 4 java.lang.String BaseEntity.s null
52 4 java.lang.Long BaseEntity.count null
Instance size: 56 bytes
Space losses: 2 bytes internal + 0 bytes external = 2 bytes total
- 测试结果解读
从测试结果可以看到:
- 数据第1行(object header: mark):这个是Mark Word占用的字节数,64位机器上占用8个字节,32位机器上占用4个字节。
- 数据第2行(object header: class) :类型指针,在开启指针压缩的情况下占4个字节,未开启的情况下占8个字节,jdk1.6之后默认开启指针压缩。
- 数据第3-14行(除(alignment/padding gap)):BaseEntity对象属性类型占用字节数,一共占用39个字节。
- 其他数据行:对齐填充2个字节,由于Mark Word(8个字节)+类型指针(4个字节)+对象字节数(42个字节)=54个字节,54不是8的倍数,所以要填充2个字节凑够8的倍数。如果字节数之和刚好是8的倍数,则不需要对齐填充。
从结果也可以得到基本类型及普通对象指针字节数表格:
| 类型 | 字节数 |
|---|---|
| long/double | 8 |
| int/float | 4 |
| char/short | 2 |
| byte/boolean | 1 |
| oops(Ordinary Object Pointers) | 4 |
总结
通过我们上述测试得到的表格,在不依赖openjdk jol的情况下计算出一个对象属性类型占多少个字节之后,开启指针压缩时,在对象属性类型字节数基础上加12,未开启指针压缩时加16,这样就能轻松的计算出一个对象占多少个字节了,从此面试不再怕。
参考资料:
《深入理解Java虚拟机》
能力一般,水平有限,如有错误,请多指出。如果对你有用点个关注给个赞呗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号