Netty数据载体ByteBuf作用
ByteBuf缓冲区
Netty版本:netty-all-4.1.30.Final
Netty提供了ByteBuf缓冲区组件来替代Java NIO的ByteBuffer缓冲区组件(即Netty的数据读写是以ByteBuf为单位进行交互的),以便更加快捷和高效的操作内存缓冲区;
ByteBuf的优势
ByteBuf与Java NIO的 ByteBuffer相比, ByteBuf的优势如下:
- Pooling池化机制减少了内存的分配和释放,减少了GC,提升了效率
- 零复制机制(如复合缓冲区类型)减少了内存复制
- 不需要调用flip方法去切换读写模式
- 可以自定义缓冲区类型
- 读取和写入的索引是分开的
- 方法可以链式调用
- 可以进行引用计数,方便重复使用
ByteBuf的组成结构

ByteBuf是一个字节容器,容器里面的数据分为四个部分,第一部分是已经丢弃的字节,部分数据是无效的;第二部分是可读字节,这部分数据是ByteBuf的主体数据,从ByteBuf里读取的数据都来自这一部分;第三部分的数据是可写字节,所有写到ByteBuf的数据都会写到这一段;最后一个部分表示该ByteBuf最多还能扩容多少容量;
ByteBuf通过三个整型的属性,可以有效地区分可读数据和可写数据的索引,使得读写之间相互没有冲突;这三个属性定义在AbstractByteBuf抽象类中,分别是:
- readerIndex(读指针):表示读取的起始位置;每读取一个字节,readerIndex自动增加1,当readerIndex与writerIndex相等时,则表示ByteBuf不可读;
- writerIndex(写指针):表示写入的起始位置;每写一个字节,writerIndex自动增加1;当writerIndex增加到capacity时,则表示ByteBuf已经不可写;
- maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量;当向ByteBuf写数据时,如果容量不足可以进行扩容,直到capacity扩容到maxCapacity,超过maxCapacity就会报错;
ByteBuf的API
容量API
- capacity()
表示ByteBuf底层占用了多少字节的内存,它的值是以下三部分之和:废弃的字节数、可读字节数和可写字节数;不同的底层实现机制有不同的计算方式;
- maxCapacity()
表示ByteBuf底层最大能够占用多少字节内存,当向ByteBuf中写数据的时候,如果容量不足,则进行扩容,直到扩容到maxCapacity设定的上限;
- readableBytes()与isReadable()
readableBytes表示ByteBuf当前可读的字节数,它的值等于(writerIndex - readerIndex),如果writerIndex与readerIndex两者相等,则表示不可读,isReadable方法返回false;
- writableBytes(),isWriteable(),maxWriteableBytes()
writableBytes表示ByteBuf当前可写的字节数,它的值等于(capacity - writerIndex),如果capacity与writerIndex两者相等,则表示不可写,isWritable方法返回false,但这时不代表不能往ByteBuf写入数据;如果发现往ByteBuf写数据写不进去,Netty会自动扩容ByteBuf,直到底层的内存大小为maxCapacity,而maxWritableBytes方法就可以表示可写的最大字节数,它的值等于maxCapacitywriterIndex;
读写指针相关的API
- readerIndex()与readerIndex(int)
前者表示返回当前的读指针readerIndex,后者表示设置读指针;
- writeIndex()与writeIndex(int)
前者表示返回当前的写指针writerIndex,后者表示设置写指针;
- markReaderIndex()与resetReaderIndex()
前者表示把当前的读指针保存起来,后者表示把当前的读指针恢复到之前保存的值;
示例一:
int readerIndex = buffer.readerIndex();
buffer.readerIndex(readerIndex);示例二:
buffer.markReaderIndex();
buffer.resetReaderIndex();推荐使用示例二,不需要自己定义变量;无论buffer被当作参数传递到哪里,调用resetReaderIndex方法都可以恢复到之前的状态,常见在解析自定义协议的数据包;
读写API
- writeBytes(byte[] src)与buffer.readBytes(byte[] dst)
writeBytes方法表示把字节数组src里的数据全部写到ByteBuf,而readBytes方法表示把ByteBuf的数据全部读取到dst,其中,dst字节数组的大小通常等于readableBytes(),而src字节数组大小的长度小于等于writableBytes();
- writeByte(byte b)与buffer.readByte()
writeByte()表示往ByteBuf中写一个字节,而buffer.readByte()表示从ByteBuf中读取一字节,类似的API还有writeBoolean(),writeChar(),writeShort(),writeInt(),writeLong(),writeFloat(),writeDouble(),以及readBoolean(),readChar(),readShort(),readInt(),readLong(),readFloat(),readDouble();
- release()与retain()
由于Netty使用了堆外内存,而堆外内存不是被JVM直接管理的,申请到内存无法被垃圾回收器直接回收,需要开发人员手动回收,申请到的内存必须手动释放,否则会造成内存泄漏;
Netty的ByteBuf是通过引用计数的方式管理的,如果有一个ByteBuf没有被引用到,则需要回收底层内存;在默认情况下,当创建完一个ByteBuf时,它的引用计数为1,然后每次调用retain方法,它的引用计数就加一,release方法则是将引用计数减一,减完之后,如果发现引用计数为0,则此时该ByteBuf不能再被操作,直接回收ByteBuf底层的内存;
- slice(),duplicate(),copy()
slice方法从原始ByteBuf中截取一段,这段数据是从readerIndex到writerIndex的,同时返回新的ByteBuf的最大容量maxCapacity为原始ByteBuf的readableBytes();
duplicate方法把整个ByteBuf都截取出来,包括所有的数据,指针信息;
slice方法与dupliacte方法的相同点:底层内存及引用计数与原始ByteBuf共享,经过slice方法或duplicate方法返回的ByteBuf调用write系列方法都会影响到原始ByteBuf,但它们都维持与原始ByteBuf相同的内存引用计数和不同的读写指针;
slice方法与dupliacte方法的不同点:slice方法只截取从readerIndex到writerIndex之间的数据,它返回的ByteBuf的最大容量被限制为原始ByteBuf的readableBytes(),而duplicate方法把整个ByteBuf都与原始ByteBuf共享;
slice方法与duplicate方法不会复制数据,它们只是通过改变读写指针来改变读写的行为(slice方法和duplicate方法对应的是ByteBuf的浅拷贝);而copy方法返回的ByteBuf中写数据不会影响原始的ByteBuf(copy方法对应的是ByteBuf的深拷贝);
slice方法和duplicate方法不会改变ByteBuf的引用计数,原始的ByteBuf调用release方法后发现引用计数为零,则开始释放内存,调用这两个方法返回的ByteBuf也会被释放,如果这时候对它们进行读写操作,就会报错,因此,开发人员可以通过调用一次retain方法来增加引用,表示ByteBuf对应的底层内存多了一次引用,在释放内存的时候,ByteBuf需要调用两次release方法,将引用计数降到零,ByteBuf才会释放内存;
这三个方法均维护各自的读写指针,与原始的ByteBuf的读写指针无关,相互之间不受影响;
- retainedSlice()与retainedDuplicate()
retainedSlice方法与retainedDuplicate方法的作用是在截取内存片段的同时,增加内存的引用计数;
// retainedSlice等价于
slice().retain();
// retainedDuplicate 等价于
duplicate().retain();
ByteBuf的基本使用
使用示例:
public class ByteBufTest {
private static final Logger logger = LoggerFactory.getLogger(ByteBufTest.class);
@Test
public void testWriteRead() {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
print("allocate ByteBuf(9, 100)", buffer);
// write方法改变写指针,写完之后写指针未到capacity的时候,buffer仍然可写
buffer.writeBytes(new byte[]{1, 2, 3, 4});
print("writeBytes(1,2,3,4)", buffer);
// write方法改变写指针,写完之后写指针未到capacity的时候,buffer仍然可写,写完int类型之后,写指针增加4
buffer.writeInt(12);
print("writeInt(12)", buffer);
// write方法改变写指针,写完之后写指针等于capacity,buffer不可写
buffer.writeBytes(new byte[]{5});
print("writeBytes(5)", buffer);
// write方法改变写指针,写的时候发现buffer不可写则开始扩容,扩容之后capacity随即改变
buffer.writeBytes(new byte[]{6});
print("writeBytes(6)", buffer);
// get方法不改变读写指针
System.out.println("getByte(3):" + buffer.getByte(3));
System.out.println("getShort(3):" + buffer.getShort(3));
System.out.println("getInt(3):" + buffer.getInt(3));
print("getByte()", buffer);
// set方法不改变读写指针
buffer.setByte(buffer.readerIndex() + 1, 0);
print("setByte()", buffer);
// read方法改变读指针
byte[] dst = new byte[buffer.readableBytes()];
buffer.readBytes(dst);
print("readBytes(" + dst.length + ")", buffer);
}
public static void print(String action, ByteBuf b) {
System.out.println("after ===========" + action + "============");
System.out.println("capacity(): " + b.capacity());
System.out.println("maxCapacity(): " + b.maxCapacity());
System.out.println("readerIndex(): " + b.readerIndex());
System.out.println("readableBytes(): " + b.readableBytes());
System.out.println("isReadable(): " + b.isReadable());
System.out.println("writerIndex(): " + b.writerIndex());
System.out.println("writableBytes(): " + b.writableBytes());
System.out.println("isWritable(): " + b.isWritable());
System.out.println("maxWritableBytes(): " + b.maxWritableBytes());
System.out.println("refCnt(): " + b.refCnt());
}
}执行结果如下:
查看代码
after ===========allocate ByteBuf(9, 100)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 0
isReadable(): false
writerIndex(): 0
writableBytes(): 9
isWritable(): true
maxWritableBytes(): 100
refCnt(): 1
after ===========writeBytes(1,2,3,4)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 4
isReadable(): true
writerIndex(): 4
writableBytes(): 5
isWritable(): true
maxWritableBytes(): 96
refCnt(): 1
after ===========writeInt(12)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 8
isReadable(): true
writerIndex(): 8
writableBytes(): 1
isWritable(): true
maxWritableBytes(): 92
refCnt(): 1
after ===========writeBytes(5)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 9
isReadable(): true
writerIndex(): 9
writableBytes(): 0
isWritable(): false
maxWritableBytes(): 91
refCnt(): 1
after ===========writeBytes(6)============
capacity(): 64
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 10
isReadable(): true
writerIndex(): 10
writableBytes(): 54
isWritable(): true
maxWritableBytes(): 90
refCnt(): 1
getByte(3):4
getShort(3):1024
getInt(3):67108864
after ===========getByte()============
capacity(): 64
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 10
isReadable(): true
writerIndex(): 10
writableBytes(): 54
isWritable(): true
maxWritableBytes(): 90
refCnt(): 1
after ===========setByte()============
capacity(): 64
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 10
isReadable(): true
writerIndex(): 10
writableBytes(): 54
isWritable(): true
maxWritableBytes(): 90
refCnt(): 1
after ===========readBytes(10)============
capacity(): 64
maxCapacity(): 100
readerIndex(): 10
readableBytes(): 0
isReadable(): false
writerIndex(): 10
writableBytes(): 54
isWritable(): true
maxWritableBytes(): 90
refCnt(): 1
ByteBuf的引用计数
JVM中使用了可达性分析来标记对象是否不再被引用,在GC的时候将对象回收;
Netty中也使用了这种手段来对ByteBuf的引用进行计数,Netty的ByteBuf的内存回收工作是通过引用计数(引用计数是一种通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术)的方式管理的;Netty采用计数的方式来追踪ByteBuf的生命周期,原因如下:
- 能对Pooled ByteBuf的支持;
- 能够尽快地发现那些可以回收的ByteBuf(非 Pooled),以便提升ByteBuf的分配和销毁的效率;
注:从 Netty4 版本开始,新增了ByteBuf的(Pooled)池化机制;即创建一个缓冲区对象池,将没有被引用的ByteBuf对象放入对象缓存池中,当需要使用时,则重新从对象缓存池中取出,而不需要重新创建;
ByteBuf引用计数的大致规则如下:在默认情况下,当创建完一个ByteBuf时,它的引用为1;每次调用retain方法,它的引用就加1;每次调用release()方法,就是将引用计数减1;如果引用为0,再次访问这个ByteBuf对象,将会抛出异常;如果引用为0,表示这个ByteBuf没有被引用,它占用的内存需要回收;
使用示例:
查看代码
@Test
public void testRef() {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
System.out.println("after create:" + buffer.refCnt());
// 增加一次引用计数
buffer.retain();
System.out.println("after retain:" + buffer.refCnt());
// 减少一次引用计数
buffer.release();
System.out.println("after release:" + buffer.refCnt());
// 减少一次引用计数
buffer.release();
System.out.println("after release:" + buffer.refCnt());
// refCnt为0,ByteBuffer不能再进行retain
// 增加一次引用计数
buffer.retain();
System.out.println("after retain:" + buffer.refCnt());
}执行结果如下:

最后一次retain方法抛出了IllegalReferenceCountException异常,原因是:在此之前,缓冲区buffer的引用计数已经为 0,该buffer不能再被访问,此时使用不能使用retain操作该buffer,即引用计数为0的缓冲区不能再继续使用;
在Netty的业务处理器开发过程中,retain和release方法应该结对使用,对缓冲区调用了一次retain,就应该调用一次release;例如:在Netty流水线上,中间所有的Handler业务处理器处理完ByteBuf之后直接传递给下一个,由最后一个Handler负责调用其release方法来释放缓冲区的内存空间;
当ByteBuf的引用计数已经为0时,Netty会进行ByteBuf的回收,分为两种场景:
Pooled池化的ByteBuf内存,回收方法是:放入可以重新分配的ByteBuf池子,等待下一次分配;
Unpooled未池化的ByteBuf缓冲区,需要细分为两种情况:如果ByteBuf是堆(Heap)结构缓冲,ByteBuf会被JVM的垃圾回收机制回收;如果ByteBuf是Direct直接内存的类型,则会调用本地方法释放外部内存(unsafe.freeMemory);
除了通过ByteBuf成员方法retain和release管理引用计数之外,Netty还提供了一组件用于增加和减少引用计数的通用静态方法:
- ReferenceCountUtil.retain(Object)
增加一次缓冲区引用计数的静态方法,从而防止该缓冲区被释放;
- ReferenceCountUtil.release(Object)
减少一次缓冲区引用计数的静态方法,如果引用计数为0,缓冲区将被释放;
注:管理引用计数的一系列方法定义在ReferenceCounted接口中,每个ByteBuf都实现了ReferenceCounted接口;
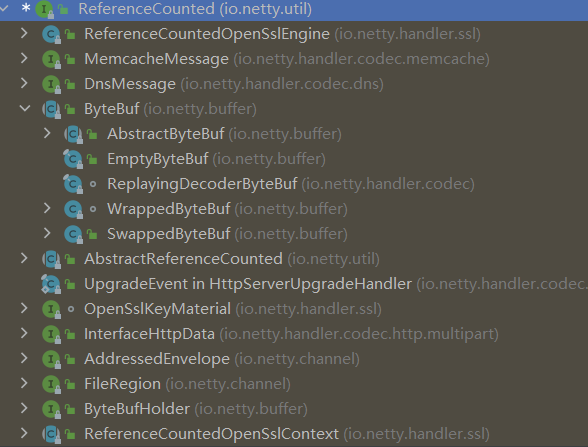
ByteBuf的Allocator分配器
Netty通过ByteBufAllocator分配器来创建缓冲区和分配内存空间,Netty提供了两种分配器实现:PooledByteBufAllocator和UnpooledByteBufAllocator;
PooledByteBufAllocator是池化的ByteBuf分配器,池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片;池化分配器采用了类jemalloc的高效内存分配的策略,此实现使用了一种称为jemalloc的已被大量现代操作系统所采用的高效方法来分配内存;
jemalloc参考:https://jemalloc.net/
http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
UnpooledByteBufAllocator是普通的未池化ByteBuf分配器,它没有把ByteBuf放入池中,每次被调用都会返回一个新的ByteBuf实例;使用完之后,通过Java的垃圾回收机制回收或者直接释放;
在Netty中,默认的分配器为ByteBufAllocator.DEFAULT,该默认的分配器可以通过JVM参数进行配置,如下:
-Dio.netty.allocator.type={unpooled|pooled}
在Netty4.0.x默认使用的是UnpooledByteBufAllocator,而在Netty4.1.x默认使用PooledByteBufAllocator;
初始化逻辑在io.netty.buffer.ByteBufUtil的静态代码块中,如下:
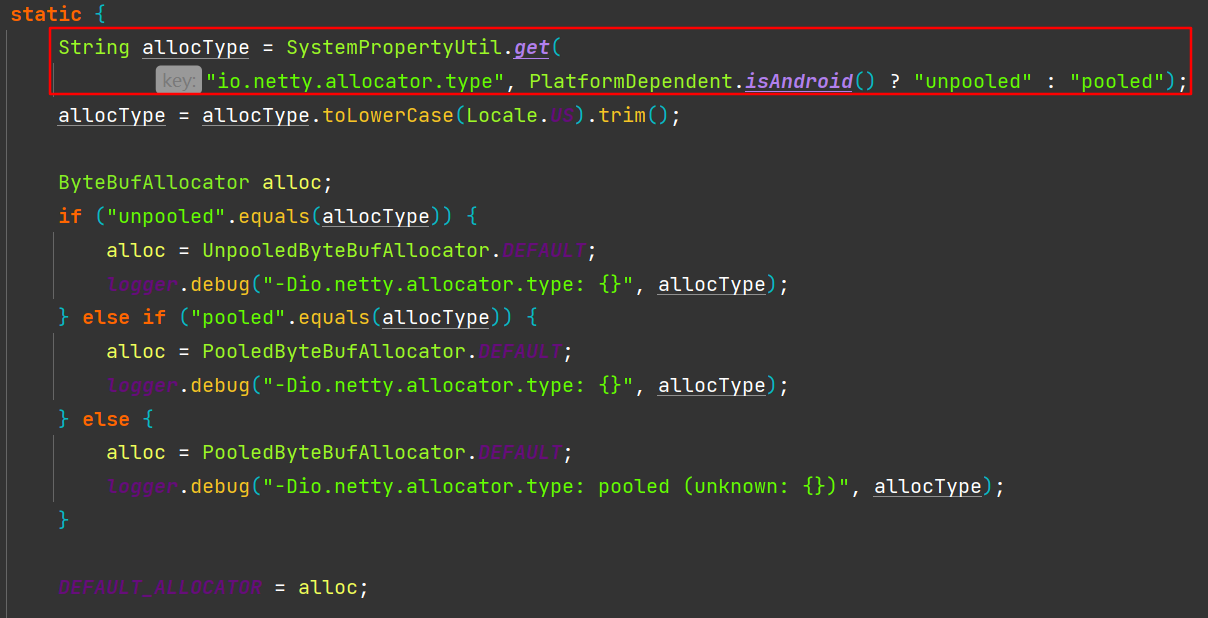
Android系统默认为unpooled,其他系统默认为pooled池化分配器,除非通过系统属性io.netty.allocator.type做专门配置;
使用ByteBufAllocator创建ByteBuf的方式如下:
- 通过默认分配器分配
// 通过默认分配器分配
// 初始容量为256,最大容量为Integer.MAX_VALUE的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer();- 通过默认分配器分配,自定义初始化容量,最大容量
// 通过默认分配器分配
// 初始容量为9,最大容量为100的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);- 非池化分配器,分配Java的堆(Heap)结构内存缓冲区
// 非池化分配器,分配Java的堆结构内存缓冲区
buffer = UnpooledByteBufAllocator.DEFAULT.heapBuffer();- 池化分配器,分配由操作系统管理的直接内存缓冲区
// 池化分配器,分配由操作系统管理的直接内存缓冲区
buffer = PooledByteBufAllocator.DEFAULT.directBuffer();
ByteBuf缓冲区的类型
根据内存的管理方不同,分为堆缓存区和直接缓存区,即Heap ByteBuf和Direct ByteBuf,另外,为了方便缓冲区进行组合,提供了一种组合缓冲区;
| 类型 | 说明 | 优点 | 不足 |
| Heap ByteBuf | 内部数据为一个 Java数组,存储在 JVM的堆空间中,可以通过hasArray方法来判断是不是堆缓冲区; | 未使用池化的情况下,能提供快速的分配和释放; | 写入底层传输通道之前,都会复制到直接缓冲区; |
| Direct ByteBuf | 内部数据存储在操作系统的物理内存中; | 能获取超过JVM堆限制大小的内存空间;写入传输通道比堆缓冲区更快; | 释放和分配空间昂贵(使用了操作系统的方法);在 Java中读取数据时,需要复制一次到堆上; |
| CompositeByteBuf | 多个缓冲区的组合表示; | 方便一次操作多个缓冲区实例; |
Direct Memory整理
- Direct Memory不属于 Java堆内存,所分配的内存其实是调用操作系统malloc()函数来获得的;由 Netty的本地内存堆 Native堆进行管理;
- Direct Memory容量可通过-XX:MaxDirectMemorySize来指定,如果不指定,则默认与Java堆的最大值(-Xmx指定)一样;
- Direct Memory的使用避免了Java堆和Native堆之间来回复制数据;
- 由于创建和销毁Direct Buffer的代价比较高昂,在需要频繁创建缓冲区的场合不宜使用Direct Buffer,Direct Buffer应尽量在池化分配器中分配和回收;
- Direct Buffer的读写比Heap Buffer快,但是它的创建和销毁比普通Heap Buffer慢;
- 在Java的垃圾回收机制回收Java堆时,Netty框架也会释放不再使用的Direct Buffer缓冲区,因为它的内存为堆外内存,所以清理的工作不会为JVM带来压力;
Heap ByteBuf与Direct ByteBuf的对比
- Heap ByteBuf通过调用分配器的buffer方法来创建;而 Direct ByteBuf的创建,是通过调用分配器的directBuffer方法;
- Heap ByteBuf缓冲区可以直接通过array方法读取内部数组;而Direct ByteBuf缓冲区不能读取内部数组;
- 可以调用ByteBuf#hasArray方法来判断是否为Heap ByteBuf类型的缓冲区;如果hasArray方法返回值为 true,则表示是Heap堆缓冲,否则为直接内存缓冲区或复合缓冲区;
- 如果要从Direct ByteBuf读取缓冲数据进行Java程序处理时,会相对比较麻烦,需要通过getBytes/readBytes等方法先将数据复制到 Java的堆内存,然后进行其他的计算;
Heap ByteBuf使用示例
查看代码
// 堆缓冲区
@Test
public void testHeapBuffer() {
// 取得堆内存 netty4默认直接buffer,而非堆buffer
ByteBuf heapBuf = ByteBufAllocator.DEFAULT.heapBuffer();
heapBuf.writeBytes("heap buffer".getBytes(StandardCharsets.UTF_8));
if (heapBuf.hasArray()) {
// 取得内部数组
byte[] array = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
int length = heapBuf.readableBytes();
System.out.println(new String(array,offset,length, StandardCharsets.UTF_8));
}
heapBuf.release();
}执行结果如下:
Direct ByteBuf使用示例
查看代码
// 直接缓冲区
@Test
public void testDirectBuffer() {
ByteBuf directBuf = ByteBufAllocator.DEFAULT.directBuffer();
directBuf.writeBytes("direct buffer".getBytes(StandardCharsets.UTF_8));
if (!directBuf.hasArray()) {
int length = directBuf.readableBytes();
byte[] array = new byte[length];
// 读取数据到堆内存
directBuf.getBytes(directBuf.readerIndex(), array);
System.out.println(new String(array, StandardCharsets.UTF_8));
}
directBuf.release();
}执行结果如下:

注:如果缓冲区hasArray方法返回false不一定代表缓冲区一定就是Direct ByteBuf直接缓冲区,也有可能是CompositeByteBuf缓冲区;
为了快速创建ByteBuf,Netty提供了一个获取缓冲区的Unpooled工具类,用于创建和使用非池化的缓冲区;
// 创建堆缓冲区
ByteBuf heapBuf = Unpooled.buffer(8);
// 创建直接缓冲区
ByteBuf directBuf = Unpooled.directBuffer(16);
// 创建复合缓冲区
CompositeByteBuf compBuf = Unpooled.compositeBuffer();除了在Netty开发使用外,Unpooled类的应用场景还包括不需要其他 Netty组件(除了缓冲区之外),甚至无网络操作的场景,从而使得Java程序可以使用 Netty的高性能的、可扩展的缓冲区技术;
在开发Netty的处理器过程中,推荐使用Context.alloc( )方法获取通道的缓冲区分配器,去进行ByteBuf的创建;
ByteBuf的自动创建与释放
ByteBuf的自动创建
在入站处理时,Netty是何时自动创建入站的ByteBuf缓冲区?
Netty的Reactor反应器线程会通过底层的Java NIO通道读数据,其中执行NIO读取的方法为AbstractNioByteChannel.NioByteUnsafe#read方法;
逻辑如下:
io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read
public final void read() {
// channel的config信息
final ChannelConfig config = config();
if (shouldBreakReadReady(config)) {
clearReadPending();
return;
}
// channel的pipeline流水线
final ChannelPipeline pipeline = pipeline();
// 获取通道的缓冲区分配器
final ByteBufAllocator allocator = config.getAllocator();
// 缓冲区分配时的大小推测与计算组件
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
allocHandle.reset(config);
// 输入缓冲变量
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
// 使用缓冲区分配器,大小计算组件一起
// 由分配器按照计算好的大小分配的一个缓冲区
byteBuf = allocHandle.allocate(allocator);
// doReadBytes方法用于读取数据到缓冲区
allocHandle.lastBytesRead(doReadBytes(byteBuf));
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
readPending = false;
}
break;
}
allocHandle.incMessagesRead(1);
readPending = false;
// 发送数据到流水线,进行入站处理
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading());
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
if (close) {
closeOnRead(pipeline);
}
} catch (Throwable t) {
handleReadException(pipeline, byteBuf, t, close, allocHandle);
} finally {
// Check if there is a readPending which was not processed yet.
// This could be for two reasons:
// * The user called Channel.read() or ChannelHandlerContext.read() in channelRead(...) method
// * The user called Channel.read() or ChannelHandlerContext.read() in channelReadComplete(...) method
//
// See https://github.com/netty/netty/issues/2254
if (!readPending && !config.isAutoRead()) {
removeReadOp();
}
}
}申请的缓冲区不能太大,太大了浪费,也不能太小,太小了又不够,可能要涉及扩容,性能不好,所以申请的缓冲区大小需要推测,Netty设计了一个RecvByteBufAllocator大小推测接口和一系列的大小推测实现类,帮助进行缓冲区大小的计算和推测。默认的缓冲区大小推测实现类为AdaptiveRecvByteBufAllocator,其特点是能够根据上一次接收数据的大小,来自动调整下一次缓冲区建立 时分配的空间大小,从而帮助避免内存的浪费;
在入站处理完成后,入站的ByteBuf如何自动释放释放?
TailContext的自动释放
Netty默认会在ChannelPipline通道流水线的最后添加一个 TailContext尾部上下文,它实现了默认的入站处理方法,在这些方法中会帮助完成 ByteBuf内存释放的工作;
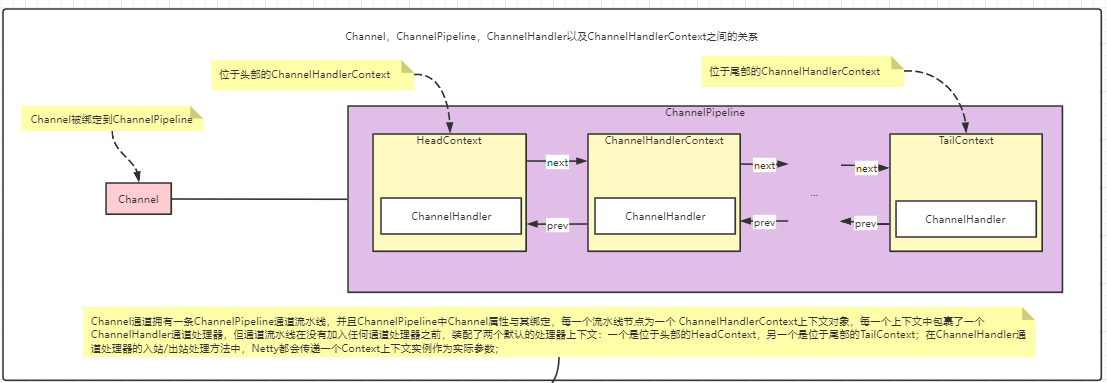
Channel,ChannelPipeline,ChannelHandler以及ChannelHandlerContext之间的关系如下图:
io.netty.channel.DefaultChannelPipeline.TailContext#channelRead

从HeadCotnext开始,ByteBuf数据包会往后传递(即入站事件向后传递),直到流水线的末端,TailContext是入站处理器的末尾,当它执行channelRead方法时会回调onUnhandledInboundMessage方法;
入站事件往后传递,可调用父类的入站方法,将ByteBuf传递到下一个Handler,直到流水线的末端,示例如下:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
// 省略ByteBuf的业务处理
// 调用父类的入站方法,默认的动作是将msg向下一站传递,一直到末端
super.channelRead(ctx,msg);
// 方法二:手动调用release方法释放
// byteBuf.release();
}
注:父类中的ChannelRead方法中会调用fireChannelRead方法,fireXXX是传播该XXX操作的结果到下一个Handler调用,当Handler不调用父类的ChannelRead方法,则channelRead事件不会传播到下一个Handler;
io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage

onUnhandledInboundMessage方法执行完后会释放缓冲区;
注:如果没有调用父类的入站处理方法将ByteBuf缓存区向后传递,则需要手动进行释放;
如果Handler业务处理器需要截断流水线的处理流程,不将ByteBuf数据包送入流水线末端的TailContext入站处理器,而且也不愿意手动释放 ByteBuf缓冲区实例,这时候应该如何处理?
这时可继承SimpleChannelInboundHandler,利用它的自动释放功能;
SimpleChannelInboundHandler自动释放
以入站读数据为例,Handler业务处理器可以继承SimpleChannelInboundHandler基类,此时必须将业务处理代码移动到重写的channelRead0方法中;
SimpleChannelInboundHandle类的入站处理方法会在调用完实际的channelRead0方法后,释放ByteBuf实例;
SimpleChannelInboundHandle的入站方法如下:
io.netty.channel.SimpleChannelInboundHandler#channelRead
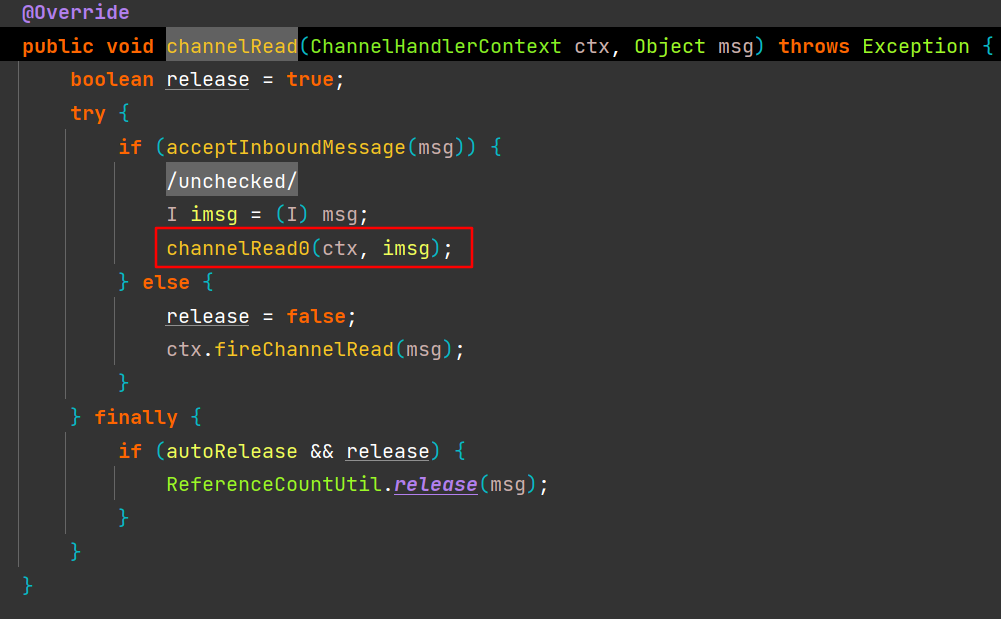
其中,channelRead0方法为抽象方法,它由SimpleChannelInboundHandler的子类实现;
![]()
在Netty的SimpleChannelInboundHandler类的源代码中,执行完由子类的channelRead0业务处理后,在finally语句代码段中, ByteBuf被释放了一次,如果ByteBuf计数器为零,将被彻底释放掉;
出站时的自动释放
出站缓冲区的自动释放方式:HeadContext自动释放;
在出站处理的流水处理过程中,在最终进行写入刷新的时候,HeadContext最终要通过通道实现类自身实现的doWrite方法,将ByteBuf缓冲区的字节数据发送出去,发送成功后,doWrite方法就会减少ByteBuf缓冲区的引用计数;
io.netty.channel.nio.AbstractNioByteChannel#doWrite
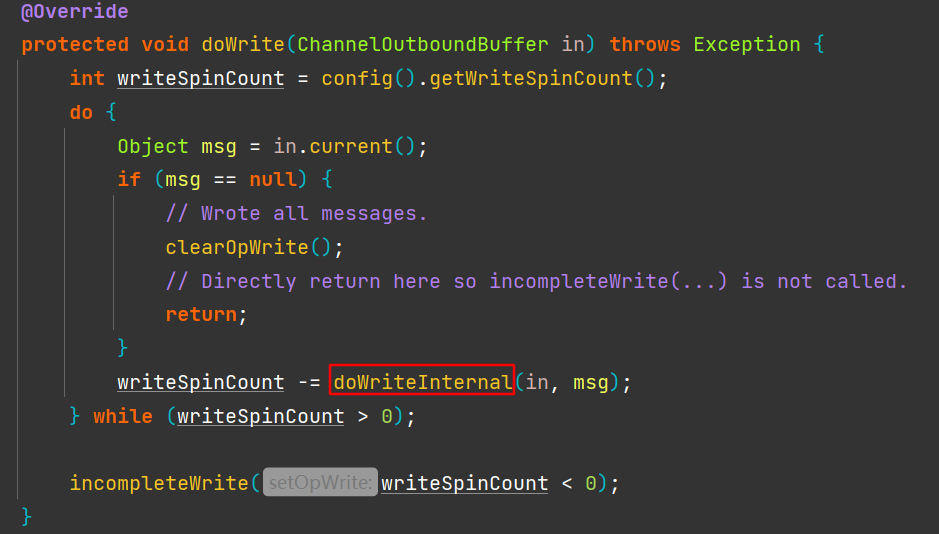
执行二进制字节内容的写入,写入到Java NIO通道,在循环里发送缓冲区的数据,直到缓冲区发送完毕,在调用的doWriteInternal方法中,当buf不可读,则会调用remove方法释放msg的引用计数;
io.netty.channel.socket.nio.NioSocketChannel#doWriteBytes
// 发送缓冲区的字节数据,将其复制到Java NIO通道即可
@Override
protected int doWriteBytes(ByteBuf buf) throws Exception {
final int expectedWrittenBytes = buf.readableBytes();
// 复制数据到Java NIO通道,相当于发送到Java NIO通道
return buf.readBytes(javaChannel(), expectedWrittenBytes);
}
ByteBuf的释放原则
入站处理时,ByteBuf释放的原则,大致如下:
- 由HeadContext传递过来的原始ByteBuf,如果一路传播到TailContext,这时无须手动释放,由TailContext自动释放;如:调用 ctx.fireChannelRead(msg)向后传递 ,一路将原始ByteBuf传播到尾;
- 在流水线处理的过程中,如果ByteBuf终止传播,不能向后传播到TailContext,那么必须调用release手动释放,或者通过继承 SimpleChannelInboundHandler实现自动释放
- 在流水线处理的过程中,如果某个处理器将原始ByteBuf转换为其它类型的Java对象,这时ByteBuf就没用了,必须调用release手动释放;
- 在流水线处理的过程中,如果原始的 ByteBuf中途被替换成别的ByteBuf,那么原始ByteBuf需要手动释放;
- 在流水线处理的过程中,如果发生异常,导致ByteBuf没有成功传递到下一个ChannelHandler,从而最终没有到达TailContext必须调用release手动释放;
出站处理时,ByteBuf释放的原则,大致如下:
- 默认情况下,出站的消息是普通Java对象, 最终都会转为ByteBuf输出,一直向前传,由HeadContext完成自动释放;
- 在流水线的出站传播过程中,如果某个ByteBuf被终止传播,从而最终没有传播到流水线头部HeadContext,此时必须调用release手动释放;
ByteBuf的浅层复制
浅层复制(即浅拷贝的意思)是可以很大程度地避免内存复制,ByteBuf的浅层复制分为两种,有切片(slice)浅层复制和整体(duplicate)浅层复制;
对象拷贝参考:https://en.wikipedia.org/wiki/Object_copying#Methods_of_copying
slice切片浅层复制
ByteBuf的slice方法可以获取到一个ByteBuf的一个切片,一个ByteBuf可以进行多次的切片浅层复制;多次切片后的ByteBuf对象可以共享一个存储区域;
io.netty.buffer.ByteBuf#slice()
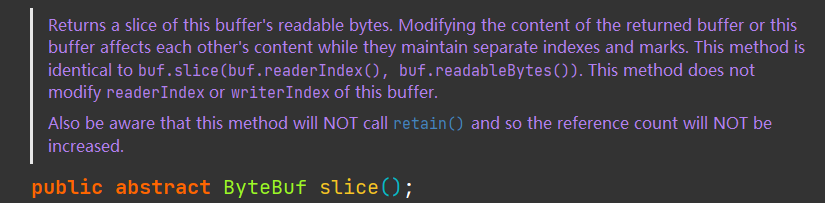
io.netty.buffer.ByteBuf#slice(int, int)
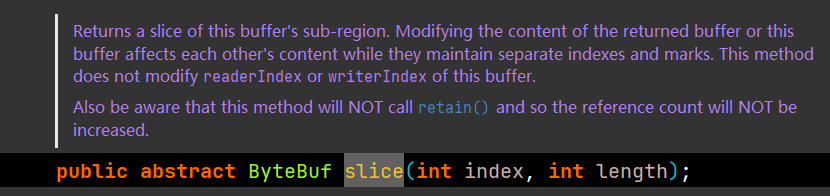
调用slice方法后,返回的切片是一个新的ByteBuf对象,该对象的几个重要属性值,大致如下:
- readerIndex(读指针)值为0;
- writerIndex(写指针)值为源ByteBuf的readableBytes方法返回可读字节数;
- maxCapacity(最大容量)值为源 ByteBuf的 readableBytes方法返回可读字节数;
切片后的新ByteBuf有两个特点:
- 切片不可以写入,原因是:maxCapacity与writerIndex值相同;
- 切片和源ByteBuf的可读字节数相同,原因是:切片后的可读字节数为ByteBuf自己的属性writerIndex – readerIndex,即源ByteBuf的readableBytes() - 0;
切片后的新ByteBuf和源 ByteBuf的关联性:
- 切片不会复制源ByteBuf的底层数据,底层数组和源 ByteBuf的底层数组是同一个;
- 切片不会改变源ByteBuf的引用计数;
duplicate整体浅层复制
io.netty.buffer.ByteBuf#duplicate
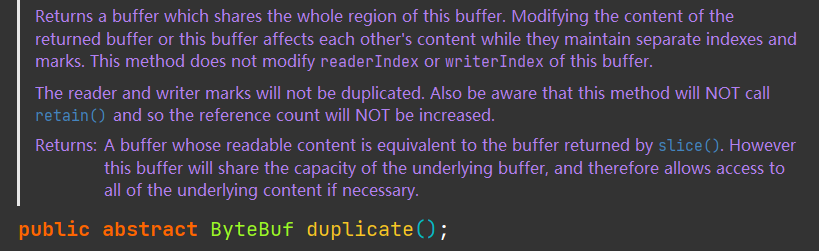
和slice切片不同,duplicate方法返回的是源ByteBuf的整个对象的一个浅层复制,包括如下内容:
- duplicate的读写指针、最大容量值,与源 ByteBuf的读写指针相同;
- duplicate不会改变源ByteBuf的引用计数;
- duplicate不会复制源ByteBuf的底层数据;
duplicate和slice方法都是浅层复制,不同的是,slice方法是截取一段的浅层复制,而duplicate是整体的浅层复制;
浅层复制的问题
浅层复制方法不会实际去复制数据,也不会改变ByteBuf的引用计数,这就会导致一个问题:在源ByteBuf调用release方法之后 ,一旦引用计数为零,就变得不能访问了;在这种场景下,源ByteBuf的所有浅层复制实例也不能进行读写了;如果强行对浅层复制实例进行读写,则会报错;
因此,在调用浅层复制实例时,可以通过调用一次retain方法来增加一次引用,表示它们对应的底层内存多了一次引用,此后引用计数为2;在浅层复制实例用完后,需要调用一次release方法方法,将引用计数减1,这样就不影响Netty内部的 ByteBuf的内存释放;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号