JMM之happens-before整理
Java内存模型(Java Memory Model,简称JMM)是围绕着在并发过程中如何处理原子性,可见性和有序性这三个特征来建立的;
其中关于JMM中的有序性这一特性的处理,在《深入理解Java虚拟机》12.3.6先行发生原则有这么一段话,如下:

从JDK 5开始,Java使用新的JSR-133内存模型,JSR-133使用happens-before的概念来指定两个操作之间的执行顺序,由于这两个操作可以在一个线程之内,也可以是在不同线程之间;因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证;
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系;
参考:[https://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf]
[https://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html]
Happens-Before原则
- 如果一个操作Happens-Before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前;即如果A happens-before B,那么JMM可以保证A操作的结果对B可见,且A的执行顺序排在B之前;
伪代码如下:
查看代码
// 以下操作在线程A中完成
i = 1;
// 以下操作在线程B中完成
j = i;假设线程A中的操作“i = 1”先行发生于线程B的操作”j = 1“,那么我们就可以确定在线程B的操作执行后,变量j的值一定等于1;
根据先行发生原则,线程A的”i = 1“的结果可以被线程B观察到,还有就是线程A结束后,没有其他线程会修改变量i的值;
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行;如果重排序之后的执行结果,与按Happens-Before关系来执行的结果一致,那么这种重排序并不非法,JMM允许这种重排序,即JMM对编译器和处理器重排序的约束原则;
摘自《Java并发编程的艺术》的3.2.3 程序顺序规则

伪代码如下:
查看代码
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
这个例子存在3个happens-before关系,如下:
查看代码
A happens-before B
B happens-before C
A happens-before C在这三个happens-before关系中,第2个和第3个的对执行结果顺序依赖是必须的,而第1个不是必要的;
注:这里的提到的两个操作可以是在一个线程内,也可以是在不同的线程内;
重排序
为了提交性能,编译器和CPU常常会对指令进行重排序,重排序主要分为两类:编译器重排序和CPU重排序;
编译器重排序
编译器重排序指的是在代码编译阶段进行指令重排,不改变程序执行结果的情况下,为了提升效率,编译器对指令进行乱序(Out-of-Order)的编译;
例如,在代码中,A操作需要获取其他资源而进入等待的状态,而A操作后面的代码跟A操作没有数据依赖关系,如果编译器一直等待A操作完成再往下执行的话,效率要慢得多,所以可以先编译后面的代码,这样的乱序可以提升编译速度;
编译器重排序的目的:与其等待阻塞指令(如等待缓存刷入)完成,不如先去执行其他指令;与CPU乱序执行相比,编译器重排序能够完成更大范围、效果更好的乱序优化;
CPU重排序
为了CPU的执行效率,流水线都是并行处理的,在不影响语义的情况下,处理次序(机器指令在CPU实际执行时的顺序)和程序次序(程序代码的逻辑执行的顺序)是允许一致的,只要满足as-if-serial规则即可;
CPU重排序包括两类:指令级重排序和内存系统重排序;
-
指令级重排序
在不影响程序执行结果的情况下,CPU内核采用ILP(Instruction-Level Parallelism,指令级并行运算)技术来将多条指令重叠执行,主要是为了提升效率;如果指令之间不存在数据依赖性,CPU就可以改变语句的对应机器指令的执行顺序,叫作指令级重排序;
-
内存系统重排序
对于现代的CPU来说,在CPU内核和主存之间都具备一个高速缓存,高速缓存的作用主要是减少CPU内核和主存的交互(CPU内核的处理速度要快得多);在CPU内核进行读操作时,如果缓存没有的话就从主存取,而对于写操作都是先写在缓存中,最后再一次性写入主存,原因是减少跟主存交互时CPU内核的短暂卡顿,从而提升性能;但是内存系统重排序可能会导致CPU缓存和主存的数据不一致;
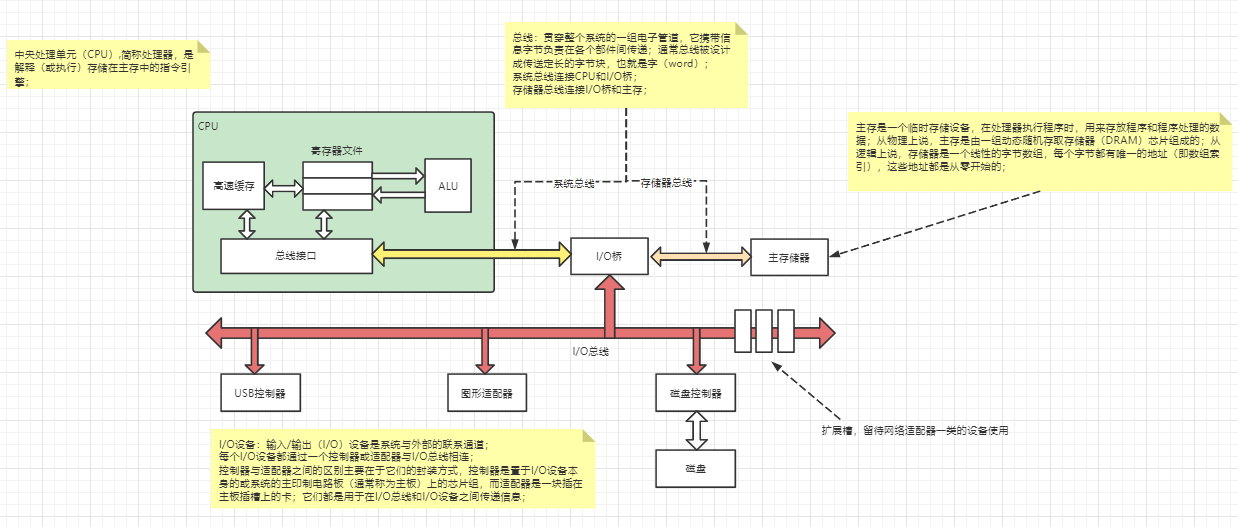
注:
只要两个指令之间不存在数据依赖,就可以对这两个指令乱序;
-
as-if-serial规则
不管怎么重排序(编译器和处理器为了提高并行度),单线程执行的程序结果不能被改变(as-if-serial语义保护单线程程序);编译器和处理器都必须遵守as-if-serial语义;
例子如下:
查看代码
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //CA和C之间存在数据依赖关系,同时B和C之前也存在数据依赖关系,因此在最终执行的指令序列中,C不能被重排序到A和B前面;
虽然编译器和CPU遵守了as-if-serial规则,但只能在单核CPU执行的情况下保证结果正确;在多核CPU并发情况下,由于CPU的一个内核无法清晰分辨其他内核上指令序列中的数据依赖关系,因此可能出现乱序执行,从而导致程序运行结果错误;
as-if-serial规则只能保障单内核指令重排序之后的执行结果正确,不能保障多内核以及跨CPU指令重排序之后的执行结果正确,也就是说as-if-serial无法保证跨线程的执行结果正确;
先行发生规则
- 程序次序规则
- 在一个线程内,按照代码顺序,写在前面的操作先行发生于写在后面的操作,即前一个操作的结果可以被后续的操作获取;如:前面一个操作把变量a赋值为1,那后面一个操作肯定能知道a已经变成了1;
- 管程锁定规则
- 同一个锁,一个unlock操作先行发行于后面(这里的“后面”指时间上的前后)对同一个锁的lock操作;
- volatile变量规则
-
对一个volatile变量的写操作先行发生于后面对这个变量的读操作,前面的写对后面(这里的“后面”是指时间上的先后)的读是可见的;
-
- 线程启动规则
- Thread对象的start方法先行发生于此线程的每一个动作;
- 线程终止规则
- 线程中的所有操作都先行发生于对此线程的终止检测,通过Thread::join()方法是否结束、Thread::isAlive()的返回值等手段检测线程是否已经终止执行;
- 线程中断规则
- 对线程interrupt方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread#interruptred方法检测是否有中断发生;
Thread#interrupted静态方法,判断线程是否被中断,并清除当前中断状态,这个方法做了两件事:
-
- 返回当前线程的中断状态;
- 将当前线程的中断状态设为false;

Thread#interrupt方法仅仅是设置线程的中断状态为true,不会停止线程;
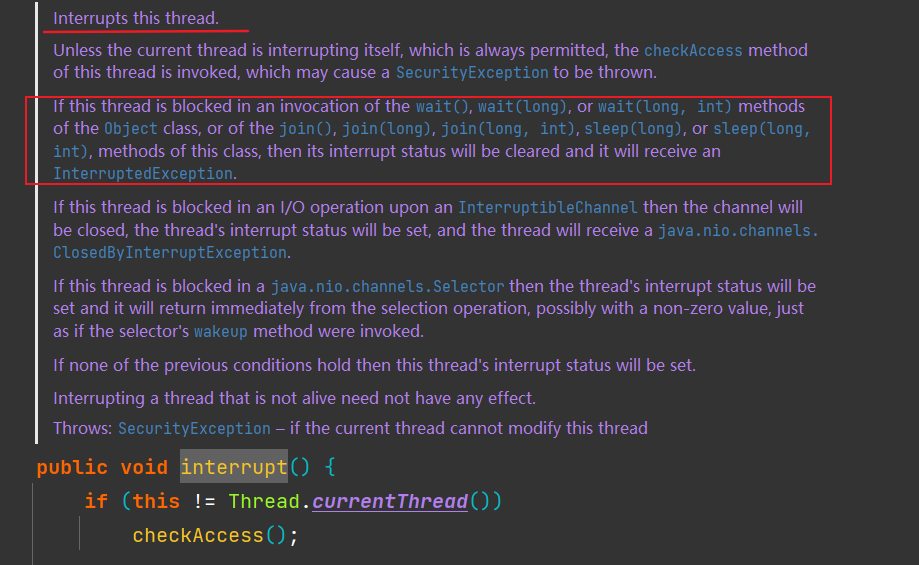
其中,当对一个线程调用Thread#interrupt方法时,如果线程处于正常活动状态,那么会将该线程的中断标志设置为 true,被设置中断标志的线程将继续正常运行,不受影响,Thread#interrupt并不能真正的中断线程,需要被调用的线程自己进行配合才行;如果线程处于被阻塞状态(例如调用sleep,wait,join等方法),在别的线程中调用当前线程对象的interrupt方法,那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常;
- 对象终止规则
- 一个对象的初始化完成(构造方法执行结束)先行发生于它的finalize方法的开始;即对象没有完成初始化之前是不能调用finalized方法的;
- 传递性
- 如果操作A先发生于操作B,操作B先发生于操作C,那么就可以得出操作A先行发生于操作C的结论;
如果代码中两个操作之间的关系不在此列,并无法从以上规则推导出来,则它们就没有顺序性保障,虚拟机可以对它们随意地进行重排序;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号