开发笔记-大数据技术栈-spark基础

Spark是一个快速、通用、可扩展的大数据分析引擎,是集批处理、实时流处理、交互式查询、机器学习与图计算为一体的大数据开源项目。
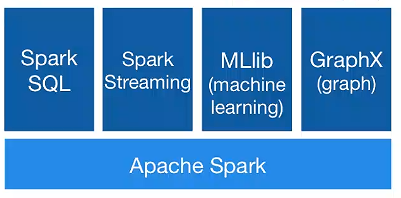
一、对比MapReduce
1.Hadoop中的job处理流程:
》从hdfs读取数据
》 在map阶段,执行mapper function,然后split到磁盘
》在reduce阶段,从各个map执行机器的中间结果,执行reduce function,最后再将结果输出到hdfs;
实际场景中,复杂任务需要拆分成多个的hadoop job,而每个job又可能涉及多次磁盘IO,所以复杂海量数据的场景下hadoop就比较法力。
2.Spark可以在内存中存储输入数据、中间结果、最终数据,在复杂递归场景中,Spark上一个job结果可以马上被下一个job使用,带来了非常大的性能提升。
二、RDD
1.Resilient Distributed Datasets, 弹性分布式式数据集,并行、容错,可以使用Transform操作或读取外部数据集创建;
2.RDD操作
操作分类:Transformation/Actions
Transformation: 懒操作算子,不触发计算
map,flatMap,filter,mappartitions,mappartitionsWithIndex,union,intersection,subtract,distinct,groupByKey,reduceByKey,aggregateByKey,sortNyKey,join,cartesian,coalesce;
Actions: 真正的执行操作,触发计算
reduce,collect,count,first,take,takeOrdered,top,saveAsTextFile,countByKey,foreach;
三、DAG
1.依赖关系
RDD的转换和动作会生成RDD之间的依赖关系,这样的计算链依赖关系就形成了逻辑上的DAG;
RDD和它依赖的RDD的关系有两种不同的类型,窄依赖和宽依赖;
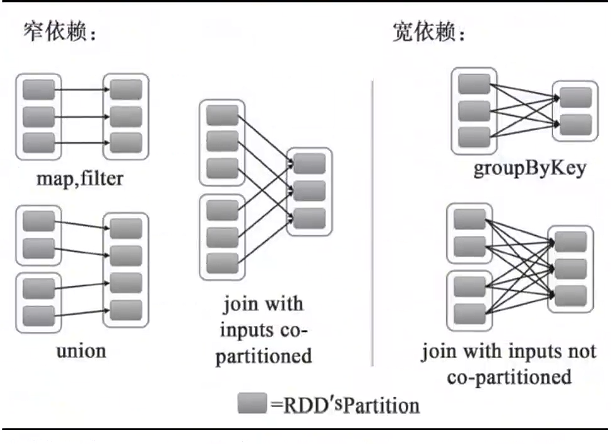
窄依赖:将partition数据根据规则进行转化,只是将数据从一个形式转换到另一个形式。窄依赖不会引入昂贵的shuffle,可以执行流水线优化将多个窄依赖整合后连续执行;
宽依赖:子partition是父RDD所有partition Shuffle的结果;
Shuffle:将数据汇总后重新分发的过程,汇总过程数据量可能会很大,则引起数据落磁盘操作,会降低性能;
2.Stage的划分
DAG可以认为是RDD之间形成的血缘关系(Lineage),借助Lineage,可以保证RDD在被计算前,父级RDD已经完成了计算,同时也实现了容错性,可以在计算结果丢失时,重新计算;
Spark执行是以Job为基本单位,会根据job的依赖关系,将DAG划分为不同的Stage。Stage划分会以Action为基准,向前回溯,遇到宽依赖,就形成一个Stage;
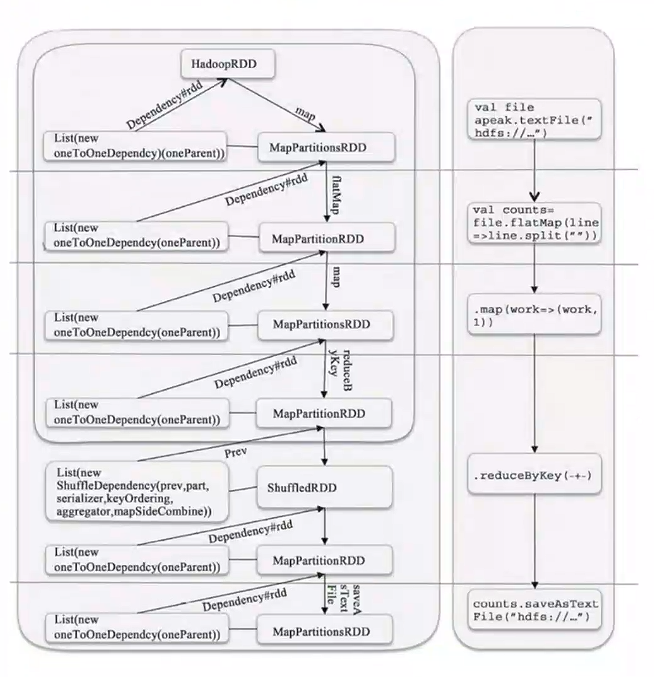
四、Spark图示
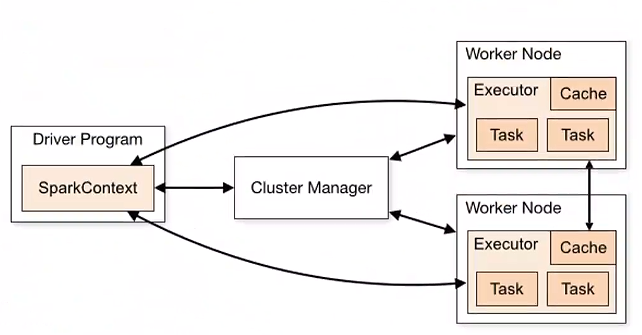
1.架构图示
2.DAG图示
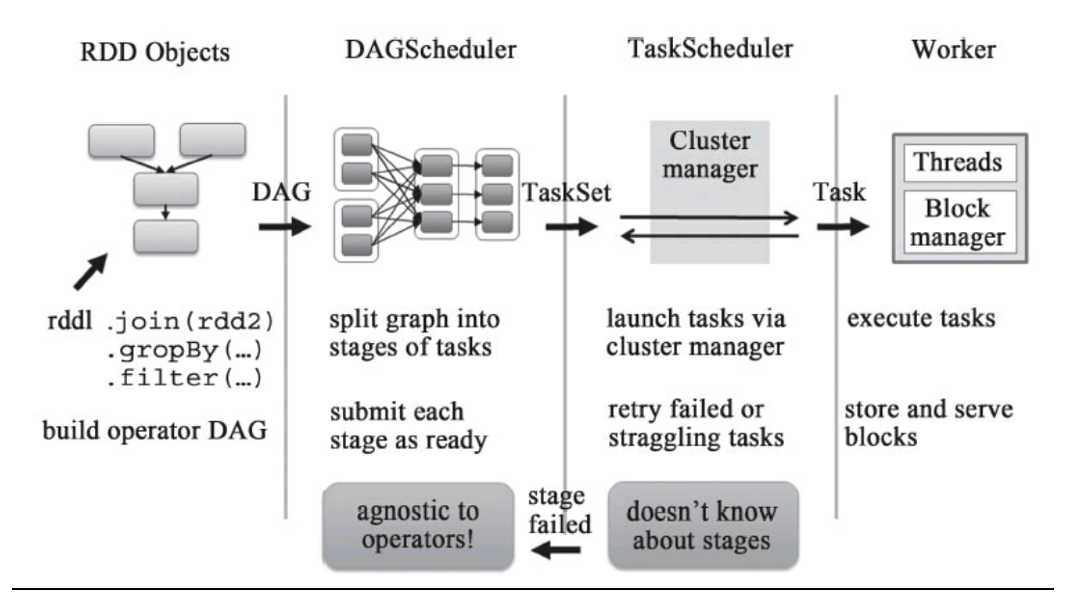
3.scheduler图示

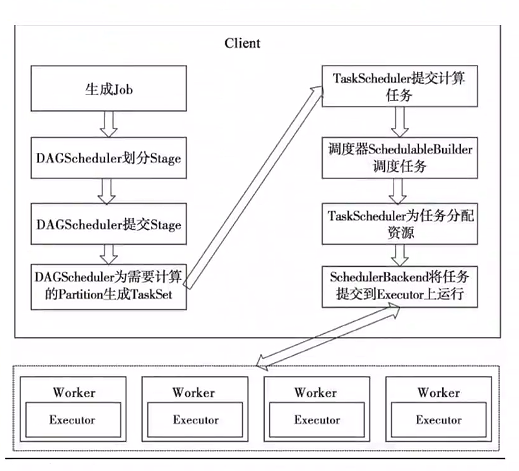
4.任务调度图示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号