开发笔记 -- 大数据技术栈 (2) - 实时&架构
一、kafka
支持大数据量高并发的可靠性分布式消息系统
* kafka 官网
https://kafka.apache.org/
* kafka认证机制
http://www.javashuo.com/article/p-mpqjhthv-cw.html
二、spark
大数据计算引擎(微批)
* 完善的开发文档
http://spark.apachecn.org/#/
* spark部署模式
spark支持local,on-yarn(yarn-client, yarn-cluster)等部署模式
* spark on yarn 模式
https://www.cnblogs.com/ITtangtang/p/7967386.html
* spark任务job-stage-task关系
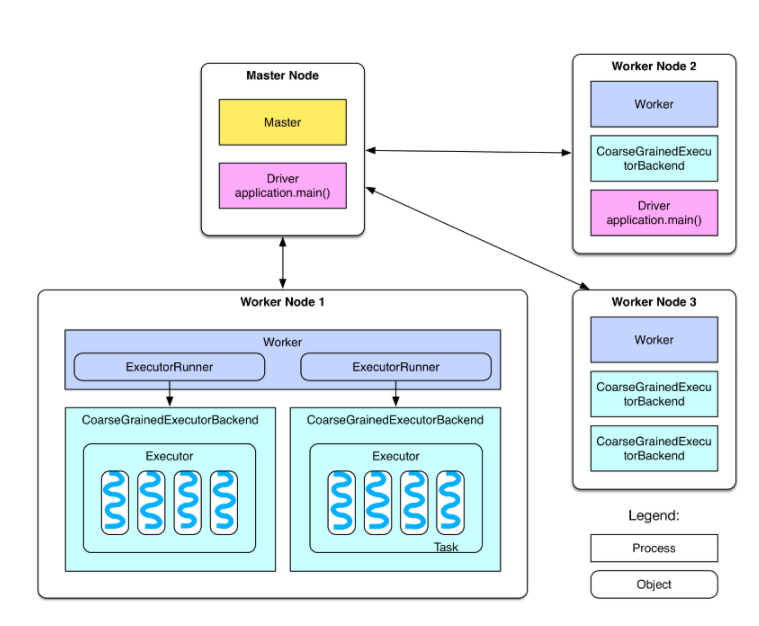
三、flink
大数据计算引擎(实时消息维度)
* 完善的开发文档
https://nightlies.apache.org/flink/flink-docs-stable/zh/
* 深度解析博文
https://baijiahao.baidu.com/s?id=1716001230069329740&wfr=spider&for=pc
* 实时消息处理需要注意消息乱序到达问题:
官方方案: window+writermark
四、架构演进
离线架构
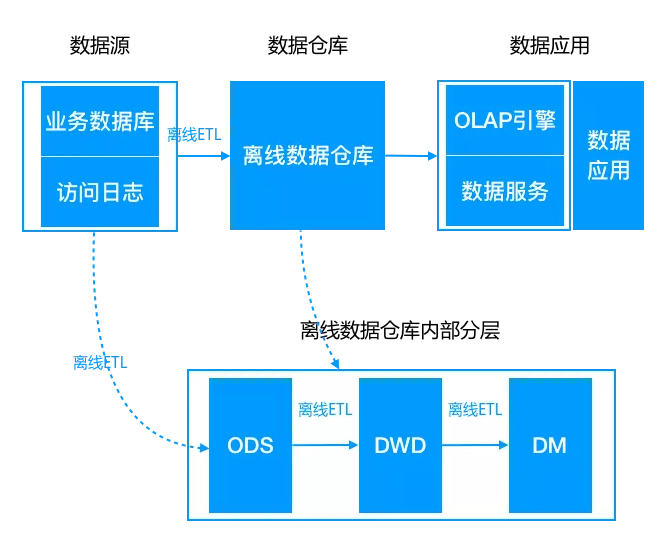
lambda架构

kappa架构
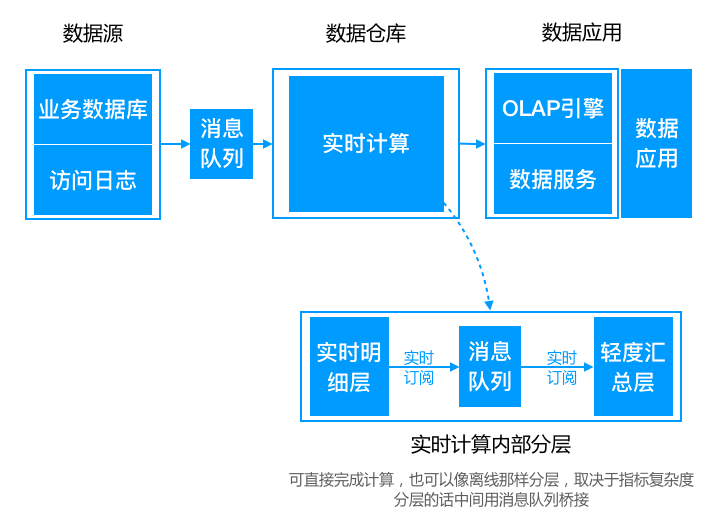
* Alibaba大数据实践: https://blog.csdn.net/BeiisBei/article/details/106167009

 浙公网安备 33010602011771号
浙公网安备 33010602011771号