

Redis缓存穿透解决方案—布隆过滤器
概念
Bloom Filter(以下简称 BF)是一个空间高效率的概率型数据结构,用来确定一个元素是否是集合中一员。
空间高效是指数据存储使用了 bit 的方式,相对来说比较紧凑,空间利用率较高。
概率型是指查询时返回两种结果:“一定不在” 和 “可能在”。
原理
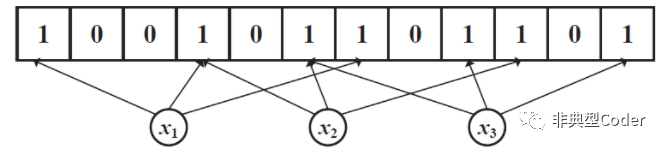
本质就是bit 数组,初始化每个 bit 都是 0,添加一个元素时, 会使用 n 个 hash 函数计算出 n 个 值,每个值都是一个 bit 的位置,最后在 bit 数组中,将对应位的值置为1,这样每个元素都对应 n 个 bit 位。
查询一个元素是否在过滤器中时,首先使用 n 个 hash 函数计算出 n 个位置,然后到数组中去检查 对应 n 个下标的值是否为 1, 有一个是 0 ,直接返回 false 。
初始化:

插入元素:
查询:
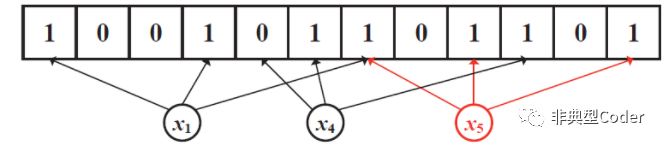
注意, hash 算法可能出现冲突,所以 布隆过滤器并不是一个 100% 准确的,如上图查询:x1 是在过滤器中的,x4不在, 但是 x5 则是不确定的。
注意事项:
1. BF 参数选择
主要参数有:BF 大小 m: bit 数组的长度、Hash 函数个数 k 以及 BF 能存放的元素的个数 n。
通常会使用较大的 m、k 来减少误报率(BF 说可能存在,实际上数据库中并不存在), 但较大的 m 意味着内存消耗, 较大的 k 意味着较大的计算量,通常需要一个折衷,既你能接受多大的误报率,然后进行计算,这里有个在线计算器 :https://hur.st/bloomfilter/
2. Hash 函数选择
理想情况下 hash 函数应当是相互独立的:针对同一个输入,各个 hash 函数返回的值应当对应 bit 数组的不同下标。否则的话就会出现较多的 hash 冲突,从而导致较多的误报(BF说可能存在,数据库实际并不存在)。基本要求:速度要快,通常不考虑 MD5, BF 常用的有:MurmurHash, Fowler–Noll–Vo (FNV) and Jenkins.
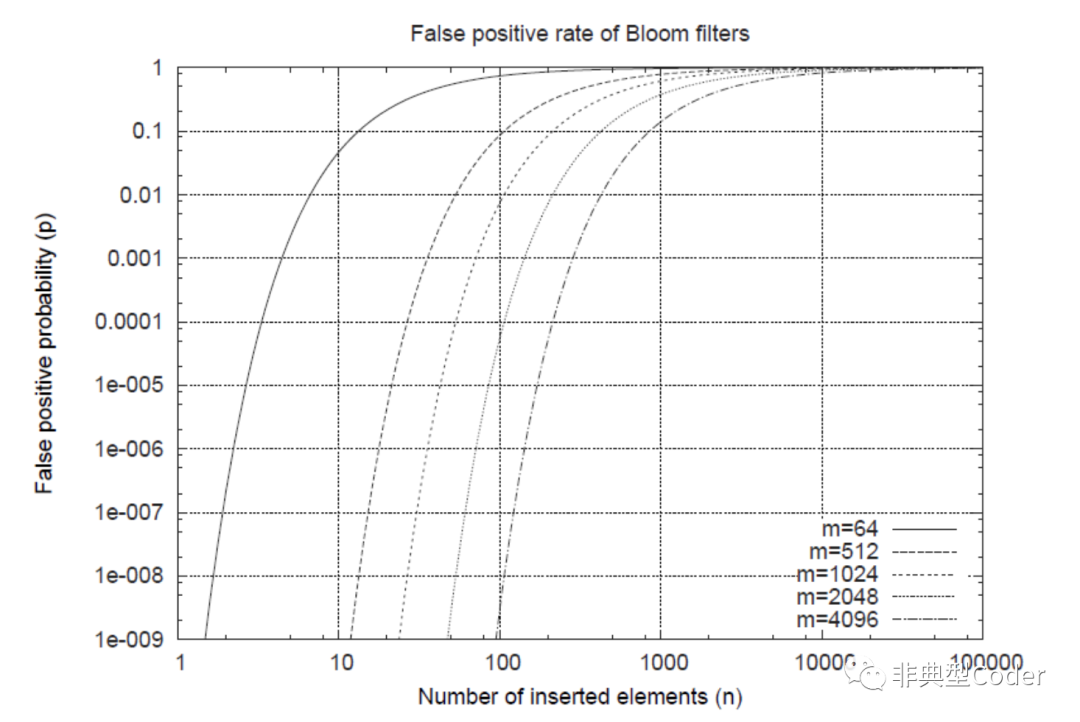
性能
横轴是元素的个数,纵轴是误报率:
应用场景:
当你的数据库表数据量较大时, 每次查询数据库都会操作磁盘,为避免缓慢的磁盘访问,可以前置一个 BF。 当 BF 确定数据不存在时,我们就可以确定也不在数据库中,从而避免了磁盘访问;当 BF 返回 true 时,其实 我们是不确定的,需要查数据库。实际工程中,的确也是需要查询数据库的,因为你不可能把业务数据放到 BF, 更多的是放一个 key。BF 只是一个防御性的组件,防止有人恶意用不存在的数据去刷你的数据库!
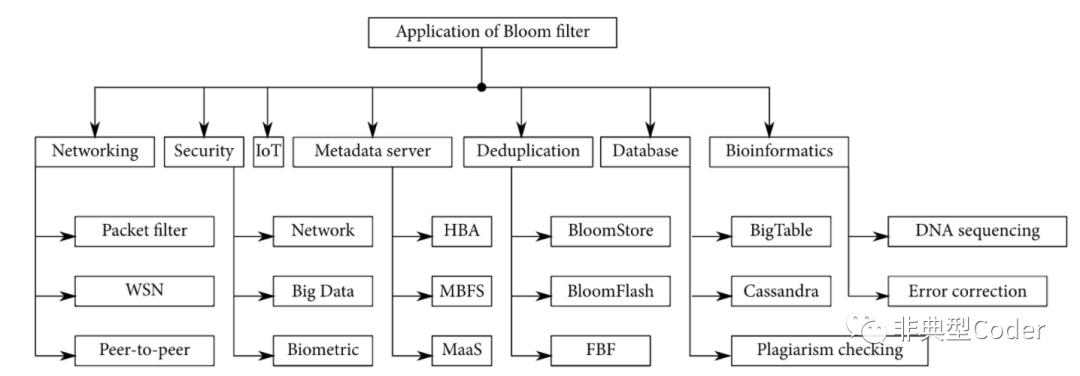
实际的一些具体应用:
变种
为了降低误报率,提升性能或者提供一些额外特性,产生了很多变种。
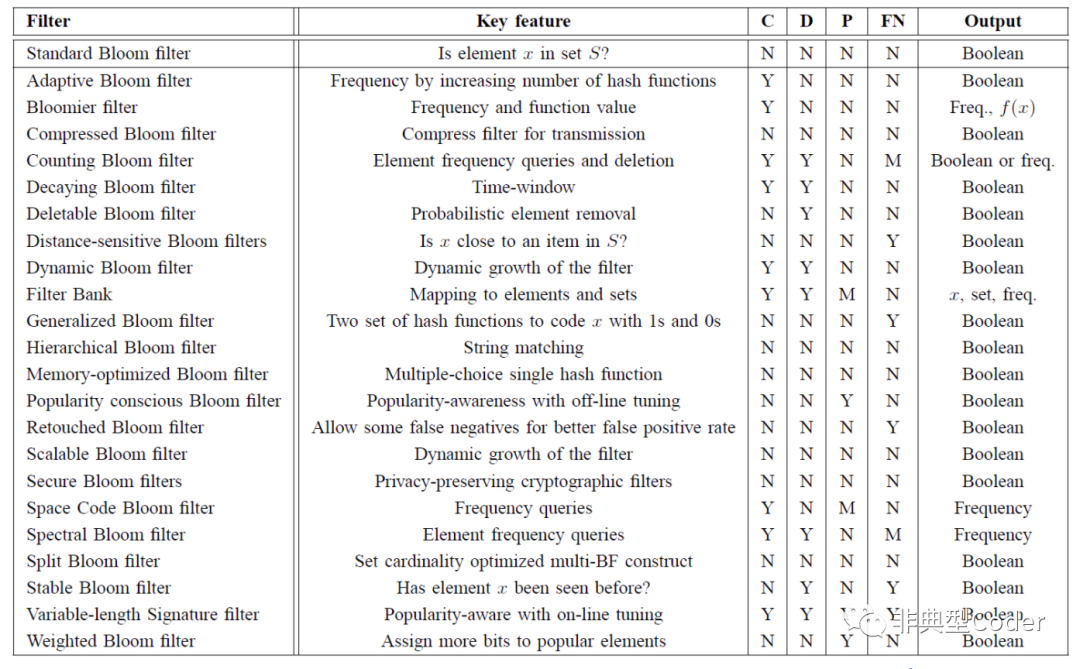
具体的实现,大家可以自己去 github 去找。
如果觉得还不错的话,关注、分享、在看(关注不失联~), 原创不易,且看且珍惜~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号