

Hadoop 伪集群搭建与使用
1. 下载
下载地址, Index of /hadoop/common/stable
2. 解压
tar -zxvf hadoop-3.3.1.tar.gz3. 配置
修改核心配置:
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>配置 hadoop 环境变量
vi etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 也可以在系统环境变量里配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_261配置 ssh 免密登陆:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh localhost4. 启动
$ bin/hdfs namenode -format
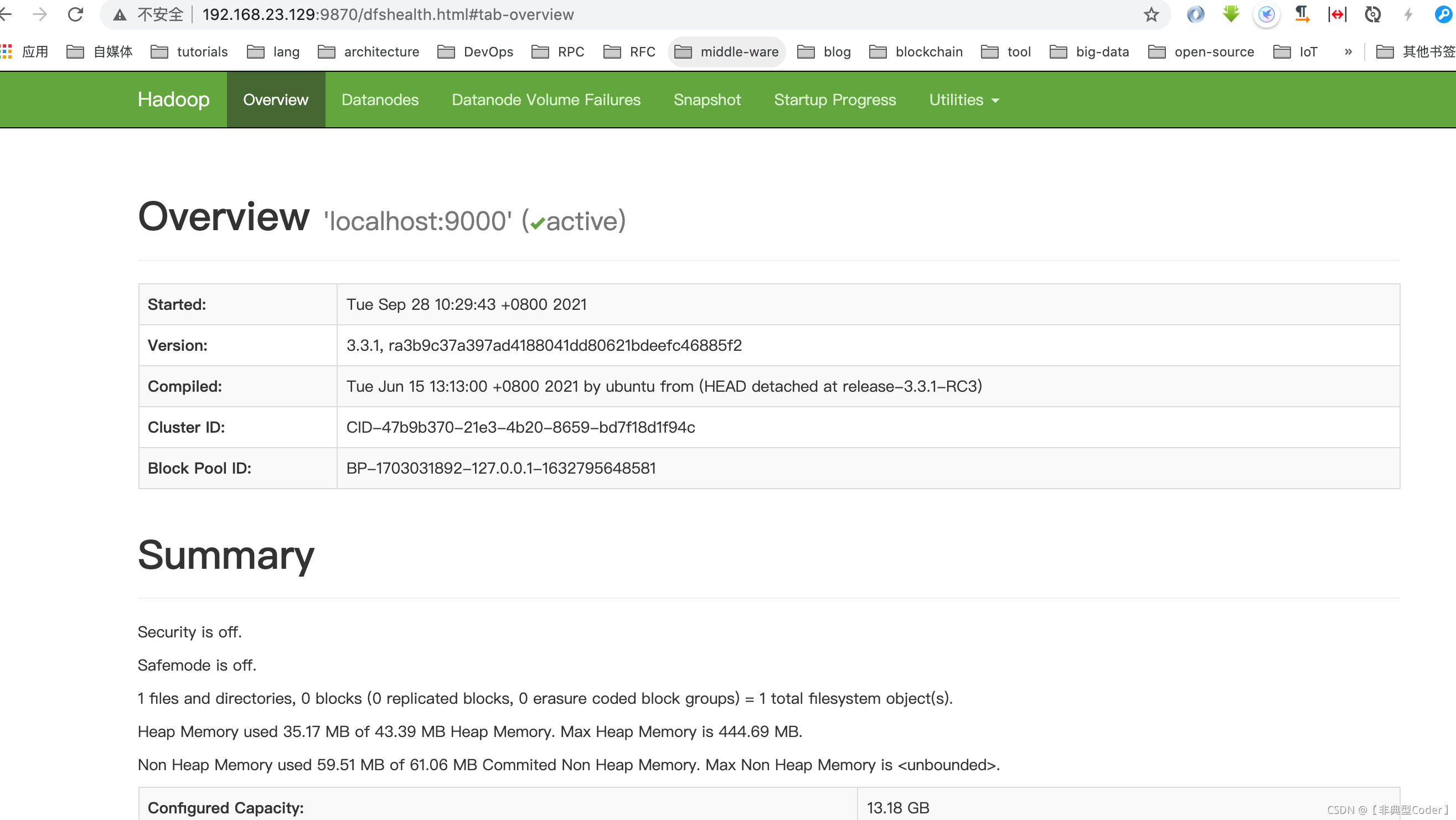
$ sbin/start-dfs.sh启动过后,访问 http://ip: 9870
5. 使用
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root
# 相对路径 /user/root/input
bin/hdfs dfs -mkdir input
# 拷贝文件
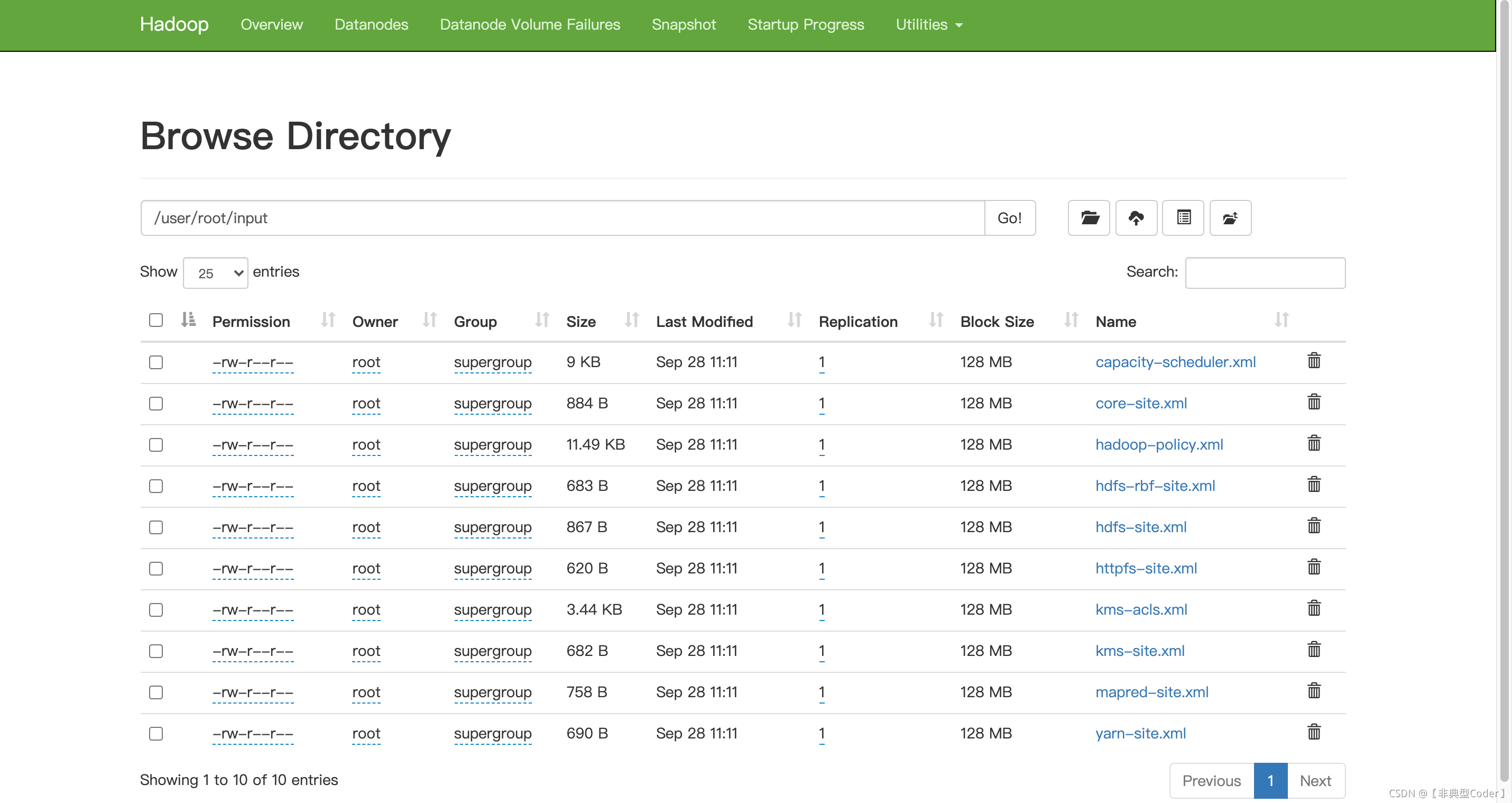
bin/hdfs dfs -put etc/hadoop/*.xml input
# 使用自带的 mapreduce 处理文件
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep input output 'dfs[a-z.]+'
# 查看处理结果
bin/hdfs dfs -cat output/* 可视化网页也能看到以上命令执行的结果:
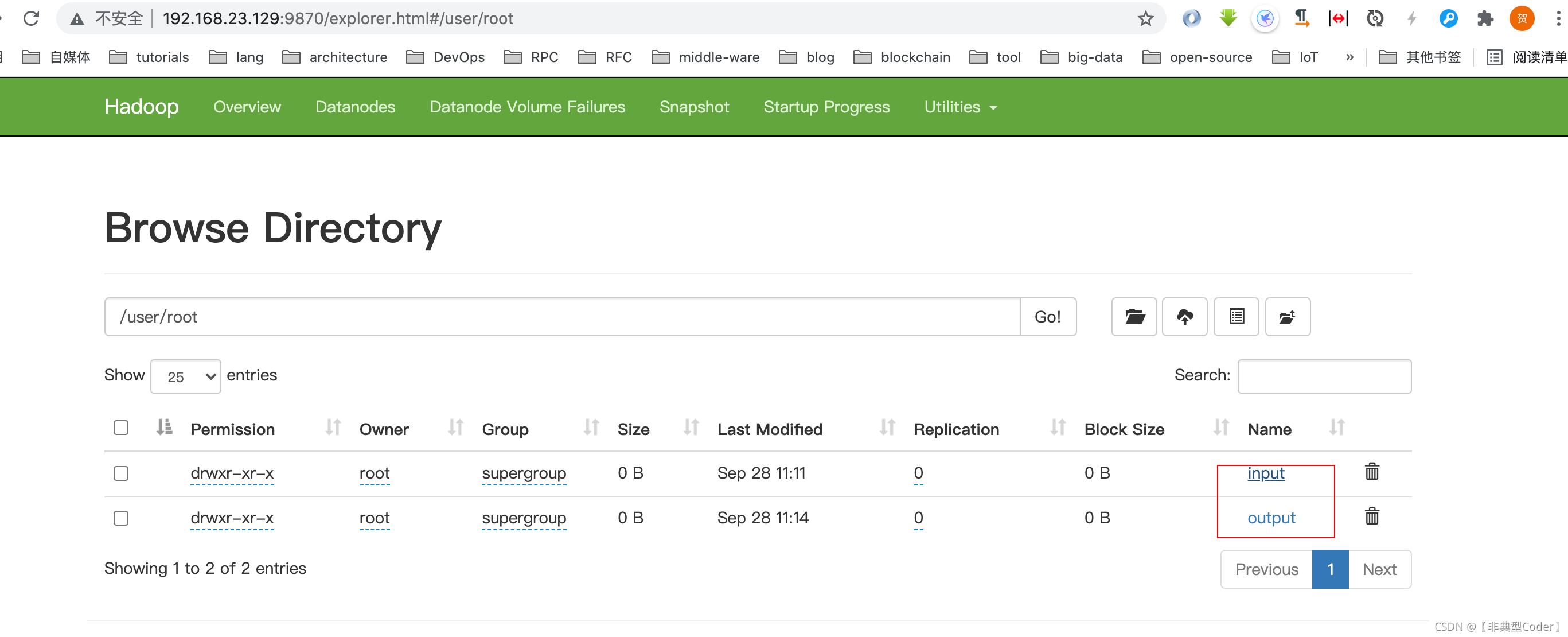
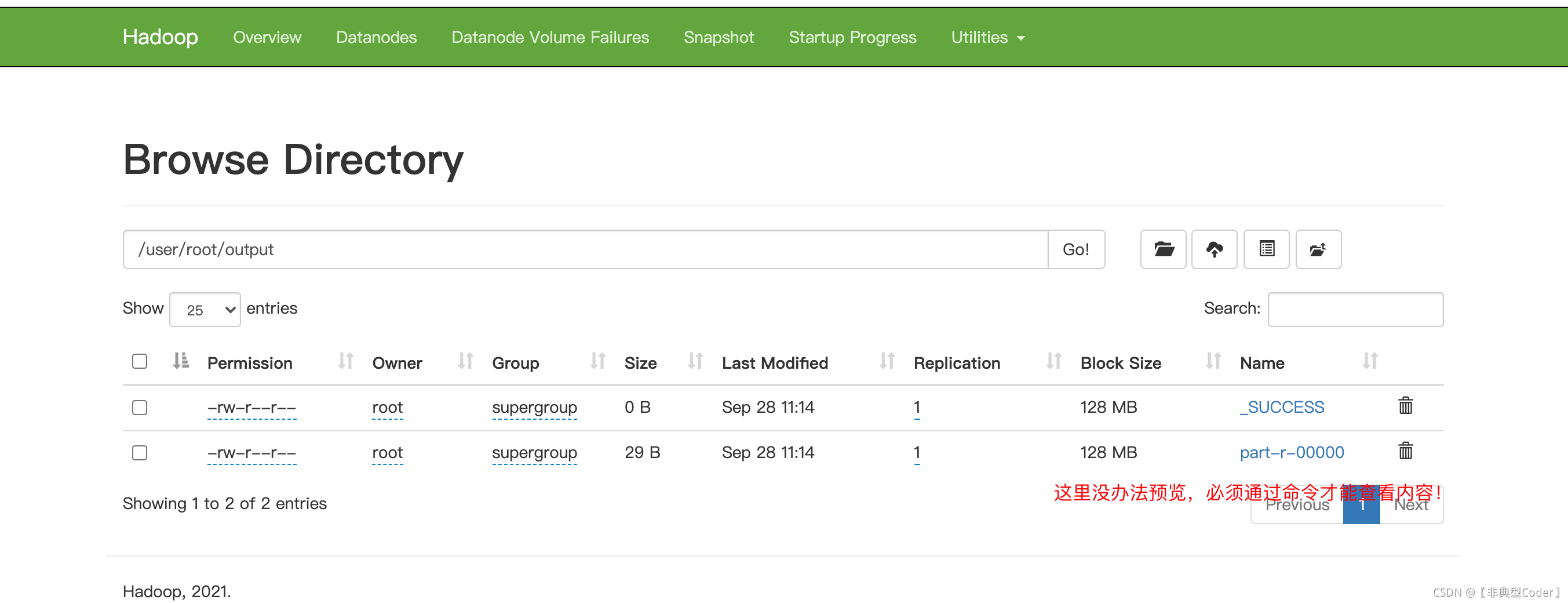
查看分布式文件夹 output 下的处理结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号