
初识Kafka
1.Kafka是什么
- Apacha Kafka是一款开源的消息引擎系统,也是一个分布式流处理平台
- 消息引擎系统是一组规范,企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
- 消息格式:使用的是纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列。
- 消息传输方式:
- 点对点模型
- 发布/订阅模型
2.相关术语
- 消息:Record。Kafka是消息引擎嘛,这里的消息就是指Kafka处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
- 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
- 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
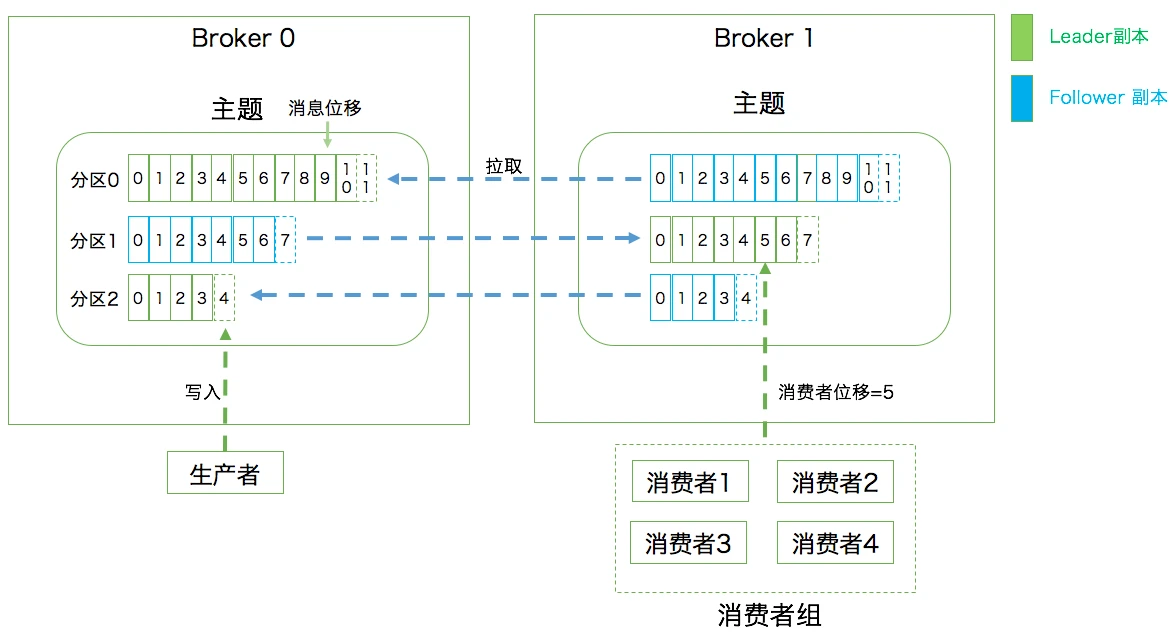
- 副本:Replica。Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance是Kafka消费者端实现高可用的重要手段。
3.三层架构
- 第一层是主题层,每个主题可以配置M个分区,而每个分区又可以配置N个副本。
- 第二层是分区层,每个分区的N个副本中只能有一个充当领导者角色,对外提供服务;其他N-1个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增。
- 最后,客户端程序只能与分区的领导者副本进行交互。
4.持久化
Kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机I/O操作,改为性能较好的顺序I/O写操作,这也是实现Kafka高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此Kafka必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在Kafka底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号