
递归———从leetcode 138 谈起
各位好,对于递归相信大家都觉得熟悉而陌生。估计绝大部分人都能说出递归最本质的特征,那就是所谓的“自己调用自己”,然而即使如此,在实际写代码的过程中,很多人还是被递归的具体实现搞懵了,仿佛递归是一种还没实现就已经存在的逻辑实体,我们需要拿着将来才会实现的东西现在就用,这种反思维的特征我想是困扰很多人的难点。今天我刚好刷到了一道leetcode 题目,里面给出了递归解法,我结合之前看博客和自己思考的经验,就打算写一篇博客来介绍一下递归怎么写。
首先我们先看一下这道题:
A linked list is given such that each node contains an additional random pointer which could point to any node in the list or null.
Return a deep copy of the list.
The Linked List is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representingNode.valrandom_index: the index of the node (range from0ton-1) where random pointer points to, ornullif it does not point to any node.
Example 1:
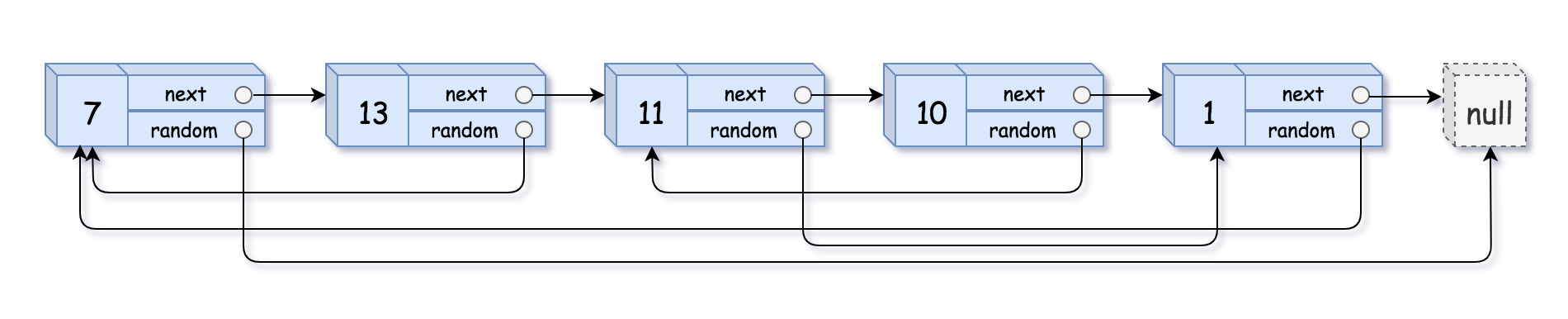
1 Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 2 Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
这个题是说,有一个链表,和传统的单链表不一样的是,每个链表结点中除了指向下一个链表结点的next指针,还有一个random随机指针。这个random指针可以指向这个链表中随便一个链表结点或者null。让我们返回这种形式的链表的深拷贝。注意是深拷贝,不能直接建立一个链表,和输入的链表一一对应,然后拷贝结点的random的值用输入的链表的各结点的random指针值。这样得到的链表各个结点的random指针指向的是原链表中的结点,不符合深拷贝的要求。
本题的方法其实蛮简单,先定义一个Map<Node,Node> ,在建立新链表的过程中,每次建立一个链表结点,就把原来的链表当前遍历的结点cur和新建的cur的拷贝结点t存进map中,这样下一次我们可以通过原来链表的结点找到新建立的链表中对应的拷贝结点。代码如下:
/* // Definition for a Node. class Node { int val; Node next; Node random; public Node(int val) { this.val = val; this.next = null; this.random = null; } } */ class Solution { public Node copyRandomList(Node head) { if(head == null){ return null; } Map<Node,Node> map = new HashMap<>(); Node cur = head; Node chead = new Node(cur.val); map.put(head,chead); Node ccur = chead; cur = cur.next; while(cur != null){ Node t = new Node(cur.val); map.put(cur,t); ccur.next = t; ccur = ccur.next; cur = cur.next; } //给random赋值 ccur = chead; cur = head; while(ccur != null){ ccur.random = map.get(cur.random); //可以通过cur结点的random,找到当前ccur.random应该指向的那个结点 ccur = ccur.next; cur = cur.next; } return chead; } }
作为leetcode 中的一道链表题目,自然很大概率可以用递归来写。递归,正如上面所说,就是自己调用自己,每次调用相对于上一次调用,问题规模都有所减小,从而最后达到求解的目的。常见的求斐波那契数列的递归写法我相信大家都可以回忆得起来。作为经验而谈,递归的求解最重要的应该是三要素的确定:
1. 递归函数的功能是什么
2. 结束条件是什么
3. 前后状态之间的联系怎么写出来
我觉得,在写递归的时候按顺序考虑上面三点是比较符合逻辑的。另外当你需要除了递归之外的一些辅助对象的时候,可以考虑将它嵌入到上面的过程中来,本题的递归写法中也同样需要借助一个map,一会儿会讲到。
那么,我们要是递归求解的话,首先应该考虑一下递归函数的功能是什么,那有人说,这不简单,题目要啥我给啥呗,没错,本题给的题目要求很明确,我们不妨直接给出我们的递归函数:
1 //这个recurse函数,返回以head为头结点的链表的深拷贝,其中形参中 2 //map和前面的功能一样,是存待拷贝结点和拷贝结点的映射的。 3 private Node recurse(Node head,Map<Node,Node> map){ 4 //具体实现代码写这里 5 }
上面代码块中已经给出了递归函数的功能了:返回以head为头结点的链表的深拷贝,返回的结点就是这个深拷贝的头结点。 这样我们第一步就完成了。
下面我们考虑第二步,因为递归是自己调用自己,所以不能一直调用,否则很快内存就会爆掉,然后程序结束,所以一定要给一个终止条件。其实也就是当问题求解规模非常小的情况,比如head如果就是null,那么我们可以放心地直接返回null就行,因为null的深拷贝肯定也就是null。所以我们得到第一个终止条件:
1 if(head == null){ 2 return null; 3 }
一般而言,递归的结束条件都比较简单,可能就是问题规模等于空啊或者等于1啊的时候该返回什么,很好考虑。而且,其实多一个少一个结束条件在很多时候其实没有太多影响,多一个结束条件可能会让递归函数更快地结束掉。这里我们想一想,还有没有一些其他的情况咱们也可以直接返回。注意啊,我们可是用了map保存了待拷贝结点和拷贝结点的映射哎,这个映射是在新链表建立的过程中不断put出来的。所以如果head已经在map中的话,那说明深拷贝链表已经建立起来了,所以我们直接返回这个深拷贝链表的头结点就好,头结点是谁呢?哈哈,因为head是原链表的头结点,map又是保存head和它的拷贝结点(也就是深拷贝链表的头结点)的映射的,所以map.get(head)就是深拷贝链表的头结点。这个结束条件如下:
1 if(map.containsKey(head)){ 2 return map.get(head); 3 }
这样,我们暂时想不到其他的结束条件了,那我们就考虑第三步吧。所谓的前后状态之间的联系,就是你已经拿到子问题的解了(其实实际执行中还没有求出来,但是我们可以这么想)。比如本题中,你自然很想得到以head.next为头结点的链表的深拷贝。有了head之后的链表的深拷贝,我们就可以想办法把它和当前head的拷贝结点(也就是深拷贝链表的头结点)给合在一起,这样连起来的结果不就是我们想要的以head为头结点的链表的深拷贝么。
好,你说你想要以head.next为头结点的链表的深拷贝是吧,哎,正好啊,我这个函数功能不就是干这个的么,那自然,我们很容易可以得到:
1 Node a = recurse(head.next,map)
你看,这个a结点是不是就是指向以head.next为头结点的链表的深拷贝链表的第一个结点了。好了,那么怎么把head的拷贝结点t和这个a连起来呢?其实只要处理好t的next和random就可以了,t.next 很明显应该指向a,这样就连在一起了,那random应该指向谁呢?别忘了map的功能,再说一次,map是在拷贝链表建立结点的过程中,存放原链表待拷贝结点和新链表的拷贝结点的映射的。既然我们已经得到a了,那我们完全可以理解成,以head.next为头结点的链表中各个结点和对应的拷贝结点都已经存在了map中了,那么t.random 就显然应该等于 map.get(head.random) 。最后我们返回t 就是需要的以head为头结点的链表的深拷贝啦。这一部分完整的代码如下:
1 Node t = new Node(head.val); //t指向head结点的拷贝结点 2 map.put(head,t); //把head和t的映射关系存入map中 3 t.next = recurse(head.next,map); //把t和以head.next 为头结点的链表的深拷贝连接起来,注意这个深拷贝是通过递归函数得来的 4 t.random = map.get(head.random); // 处理t的random指针 5 return t; //返回t 就是我们所求的以head为头结点的链表的深拷贝
最后附上完整代码:
1 /* 2 // Definition for a Node. 3 class Node { 4 int val; 5 Node next; 6 Node random; 7 8 public Node(int val) { 9 this.val = val; 10 this.next = null; 11 this.random = null; 12 } 13 } 14 */ 15 16 class Solution { 17 public Node copyRandomList(Node head) { 18 //2020.9.19 第三次复习第二次提交,递归 19 if(head == null){ 20 return null; 21 } 22 Map<Node,Node> map = new HashMap<>(); 23 return recurse(head,map); 24 } 25 26 private Node recurse(Node head,Map<Node,Node> map){ 27 if(head == null){ 28 return null; 29 } 30 if(map.containsKey(head)){ 31 return map.get(head); 32 } 33 34 Node t = new Node(head.val); 35 map.put(head,t); 36 t.next = recurse(head.next,map); 37 t.random = map.get(head.random); 38 39 return t; 40 } 41 }
在后来做题过程中,特别是做leetcode链表那部分的题目时,递归几乎可以用到每个题目中,思考步骤一般都是上面所提的三步。大家多多练习多多思考,应该很快就可以熟练了。
-----------------------------------分割线----------------------------------------------------------------------
刚才又试了一下,把第二个结束条件删了也可以。正如前面说的,多一个少一个结束条件,只要不影响函数出口,最多就是多递归少递归几次的事,一般不会引起功能问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号