把玩算法 | 链表
基础
在把玩算法 | 数组中已经对数组进行了详细的说明,本文介绍另外一种比较常见的基础数据结构:链表。链表是一种线性表,通常由一连串的节点组成,数据存放在节点中,每一个节点里存放下一个节点的指针。
与数组相比,使用链表可以克服数组需要预先知道数据大小的缺点,链表结构可以充分的利用内存空间。但是数组失去了数组随机读取的特点,同时链表由于增加了指向下一个节点的指针,空间开销会大一些。
链表一般有单向链表、双向链表、循环链表等。
单向链表
在单向链表的每个节点中存放的是数据和下一个节点的链接,这个链接指向下一个节点,最后一个节点则指向一个空值,如下图所示:

遍历整个单向链表时,需要从上一个节点往下一个节点遍历,直到遍历到最后一个节点为止。由于每个节点只存放了下一个节点的链接,所以只能从上一个节点访问下一个节点,而不能从下一个节点访问上一个节点。
双向链表
双向链表是一种更加复杂的链表。每个节点有两个链接:一个链接指向上一个节点,一个链接指向下一个节点。第一个节点的上节点为空值,最后一个节点的下一个节点为空值,如下图所示:

由于双向链表不仅存放了上一个节点的链接,也存放了下一个节点的链接,这样就可以从任何一个节点访问上一个节点,当然也可以访问下一个节点,以至整个链表。
循环链表
在循环链表中,首节点和尾节点被链接在一起。这种方式在单向链表和双向链表中皆可实现。循环链表可以被视为“无头无尾”,遍历链表时,你可以开始于任何一个节点后沿着链表的任意一个方向直到返回开始的节点,如下图所示:

接下来看一下API的定义:
API
pubic class LinkedList<Element> implements Iterable<Element>
LinkedList() 创建一个空的链表
void add(Element e) 添加一个元素
Element get(int index) 获取指定位置的元素
void set(int index, Element e) 设置指定位置的元素
Element remove(int index) 移除指定位置的元素
int size() 获取数组的大小
可以看到,上面这份API和在把玩算法 | 数组中的API差不多,包含了线性表所需要的一些基本的操作。
双向链表的实现
下面是双向链表的骨架:
public class LinkedList<Element> implements Iterable<Element> {
private Node<Element> first; // 首节点
private Node<Element> last; // 尾节点
private int size; // 链表的大小
private static class Node<Element> {
Element element;
Node prev;
Node next;
Node(Node prev, Element element, Node next) {
this.element = element;
this.prev = prev;
this.next = next;
}
}
public int size() { return size; }
// 详细的实现见下面的说明
public void add(Element e)
public Element get(int index)
public void set(int index, Element e)
public boolean remove(Element e)
}
使用实例变量first, last来记录首节点和尾节点,方便从头或者从尾对链表进行遍历,同时用size记录链表的大小。在内部创建了一个静态内部类Node来表示双向链表的一个节点,element是我们要存储的值,prev指向上一个节点,next指向下一个节点。这样我们的节点的数据结构已经有了,接下来看下各个具体操作的详细实现。
详细的实现见github:LinkedList
添加
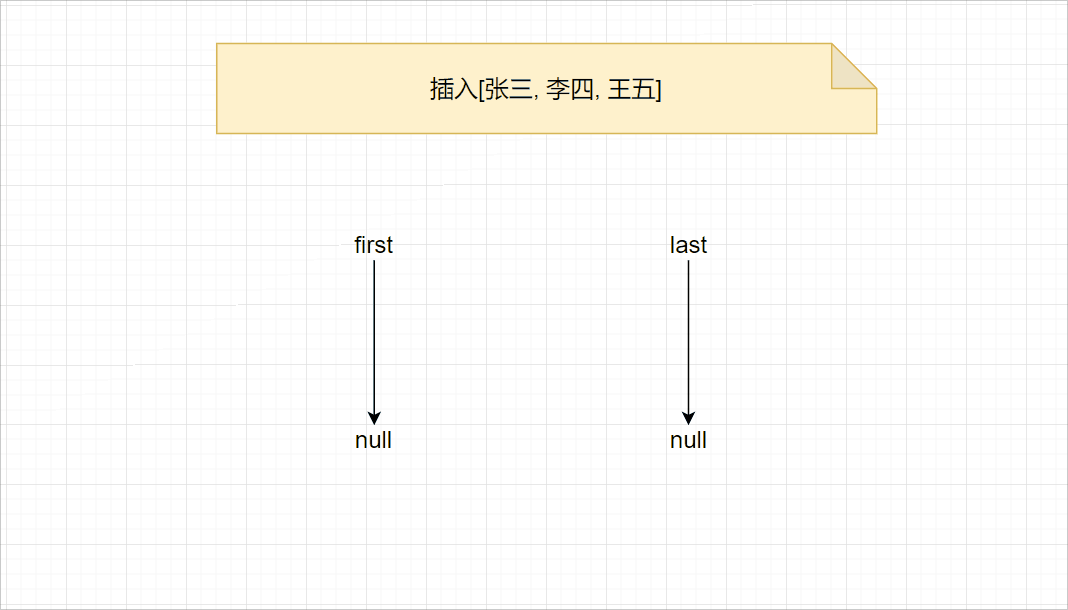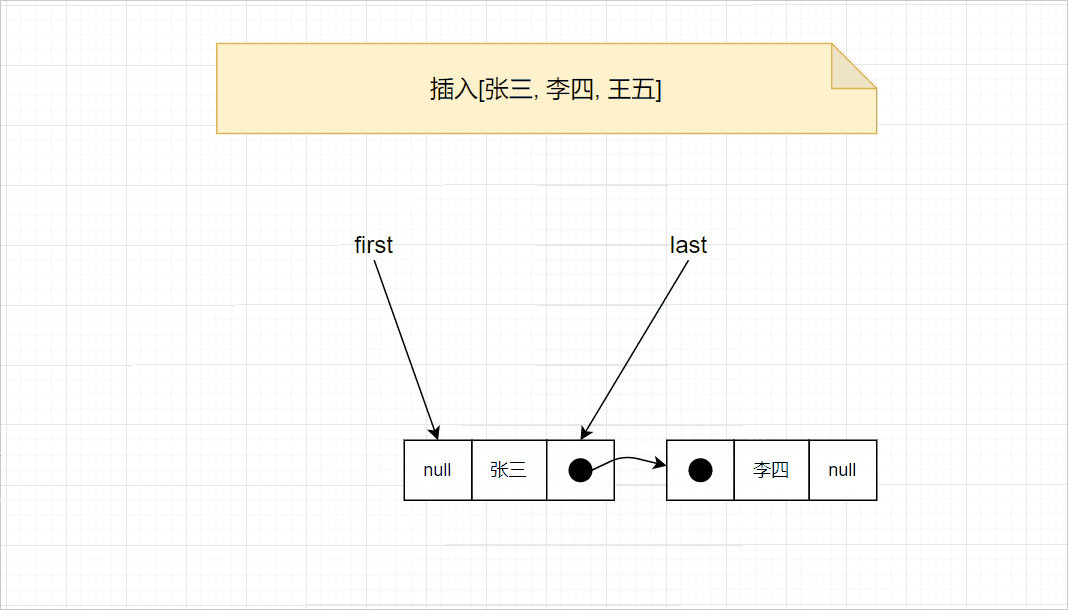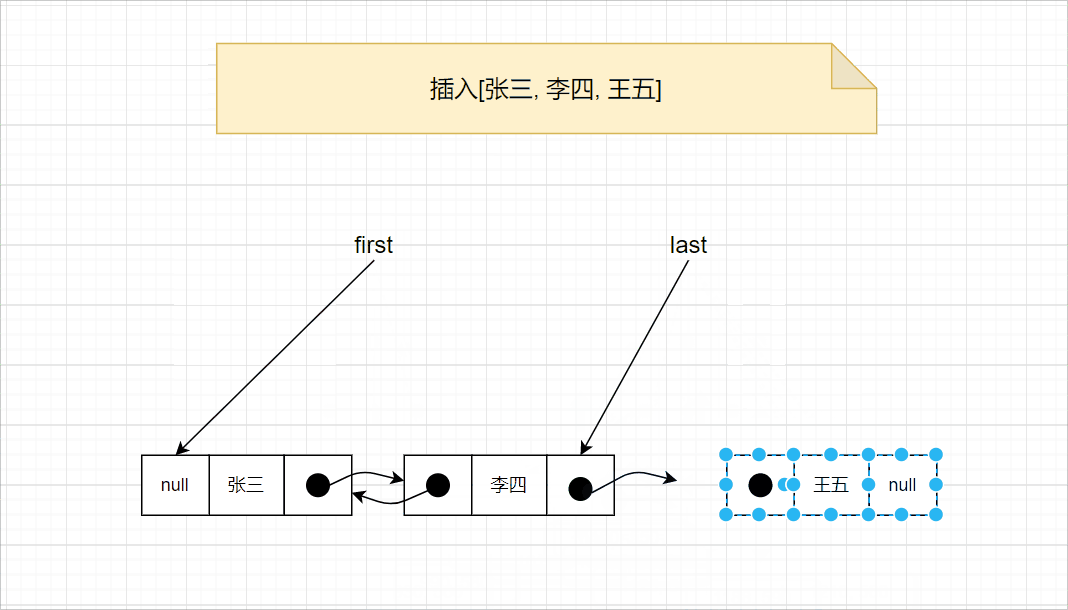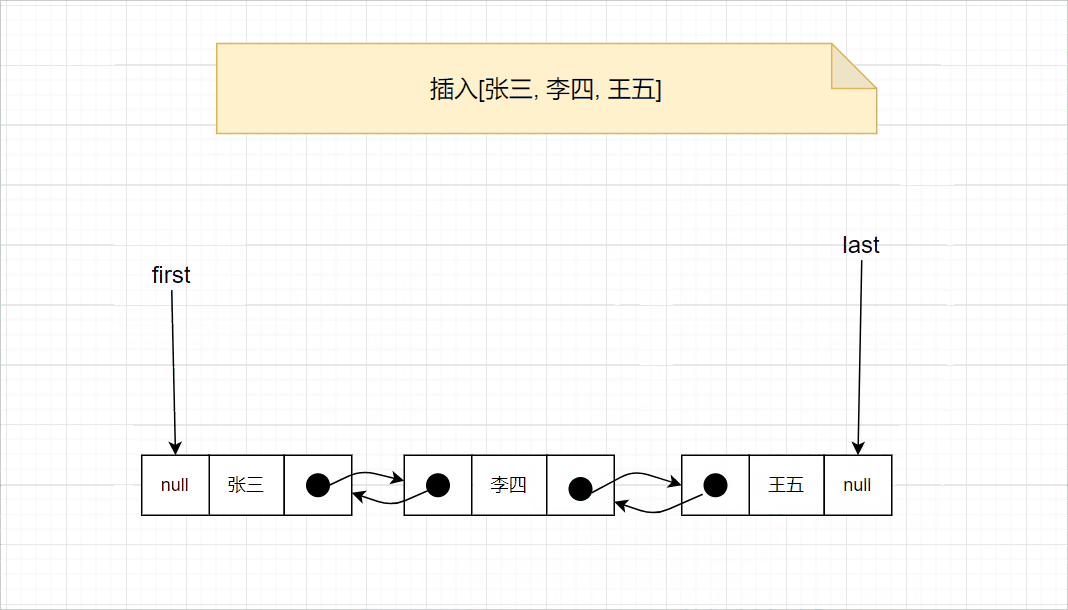
添加元素时,首先记录尾节点l,然后创建一个新节点,新节点的prev为l,next为null,将last设置为新的节点,最后将l节点的last设置为新节点。此外,添加第一个元素时,由于first和last都为null,只需要将first和last都设置为新的节点即可。相关代码如下:
public void add(Element e) {
Node<Element> l = last;
Node<Element> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null) {
first = newNode;
} else {
l.next = newNode;
}
size++;
}
详细的过程,请查看下图:
获取
根据索引获取元素时,不像数组那样可以直接根据索引直接获取元素,链表是不能直接根据索引来获取对应的元素的,链表需要从头或者尾遍历链表,直到找到对应索引的元素返回即可。在单向链表中,只能从左往右遍历链表,如果索引是链表的最后一个元素时,那么只能遍历完整个链表才能获取到对应索引的元素。我们实现的双向链表是能从左也能从右遍历链表的,当索引小于链表的一般时从左边遍历链表,当索引大于链表的一半时从右边遍历链表,这样获取最后一个元素时只需要遍历一个节点就能拿到对应的元素。
getNode方法中实现了这样的根据索引获取节点的逻辑:
public Element get(int index) {
return getNode(index).element;
}
private Node<Element> getNode(int index) {
if (index < size / 2) {
Node<Element> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
} else {
Node<Element> x = last;
for (int i = size - 1; i > index; i++) {
x = x.prev;
}
return x;
}
}
设置
有了上面的getNode方法,设置指定索引的元素值得操作就很简单了,直接获取到节点,然后设置值即可,如下:
public void set(int index, Element e) {
getNode(index).element = e;
}
移除
既然要移除指定的元素,那么首先需要找到元素对应的节点,然后再进行移除节点的操作。当元素为null和元素不为null时,我们分别用了两个for循环来遍历整个链表,直到找到直到的元素时,然后调用unlink()方法来移除对应的节点。
public boolean remove(Element e) {
if (e == null) {
for (Node<Element> x = first; x != null; x = x.next) {
if (x.element == null) {
unlink(x);
return true;
}
}
} else {
for (Node<Element> x = first; x != null; x = x.next) {
if (e.equals(x.element)) {
unlink(x);
return true;
}
}
}
return false;
}
unlink()的实现要稍微复杂一些,只需要根据待移除元素的上节点是否为null,下节点是否为null来处理即可。
上节点有两种情况:
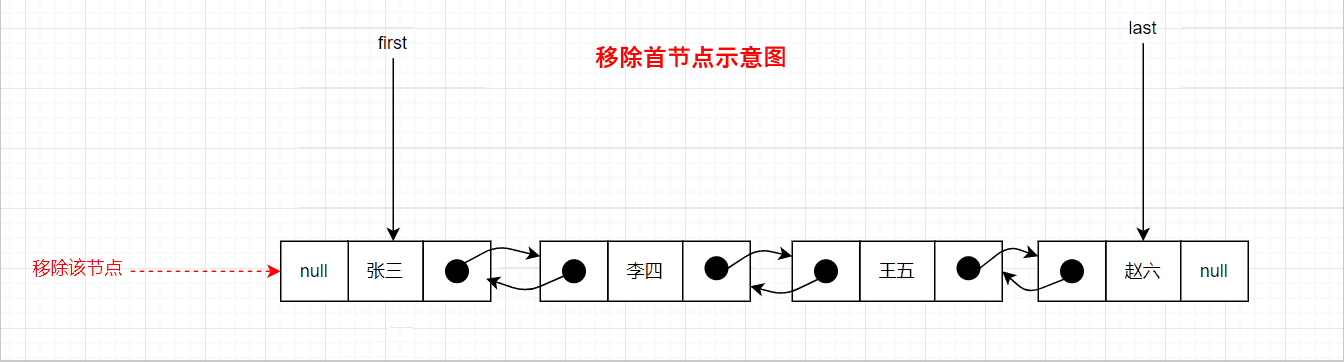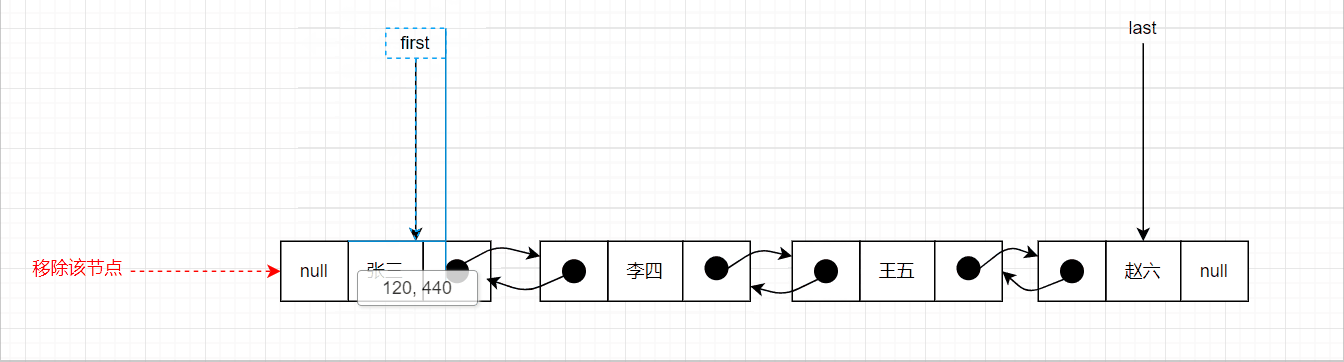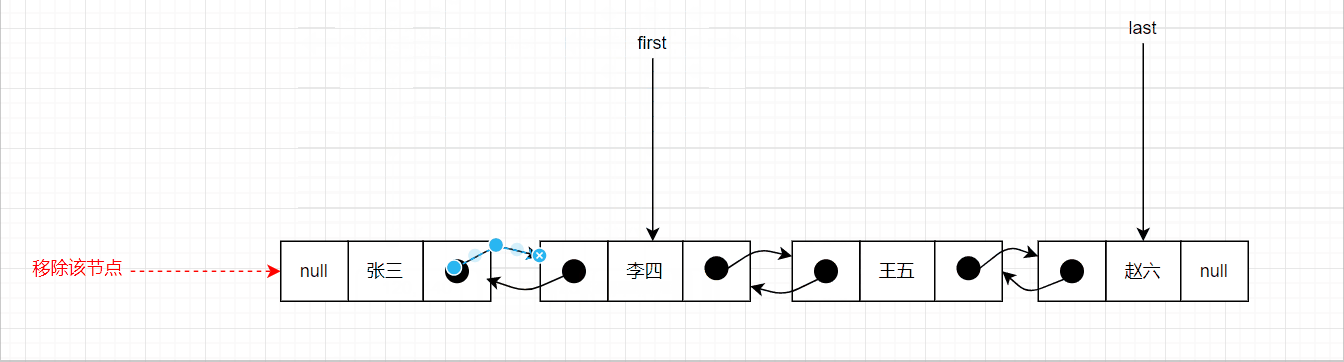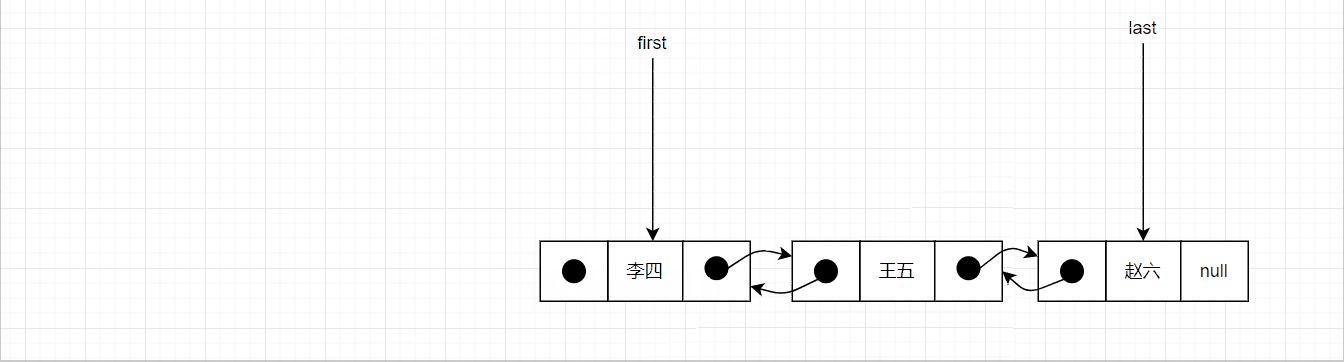
- 为null:这说明待移除节点是首节点,对于这种情况,要移除该节点,只需要将首节点设置为待移除节点的下节点即可。
- 不为null:这说明待移除节点不是首节点,要移除该节点,需要将上节点的next置为待移除节点的下节点,将
x.prev置位null以解除对上节点的链接。 - 不为null:这说明待移除节点不是首节点,要移除该节点,需要将上节点的
next置为待移除节点的下节点,将x.prev置位null以解除对上节点的链接。
下节点也有两种情况:
- 为null:这说明待移除节点是尾节点,对于这种情况,要移除该节点,只需要将尾节点设置为待移除节点的上节点即可。
- 不为null:这说明待移除节点不是尾节点,要移除该节点,需要将下节点的prev置为待移除节点的上节点,将
x.next置位null以解除对下节点的链接。
private void unlink(Node<Element> x) {
Node<Element> prev = x.prev;
Node<Element> next = x.next;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
size--;
}
移除首节点的图示如下:
移除尾节点的图示如下:
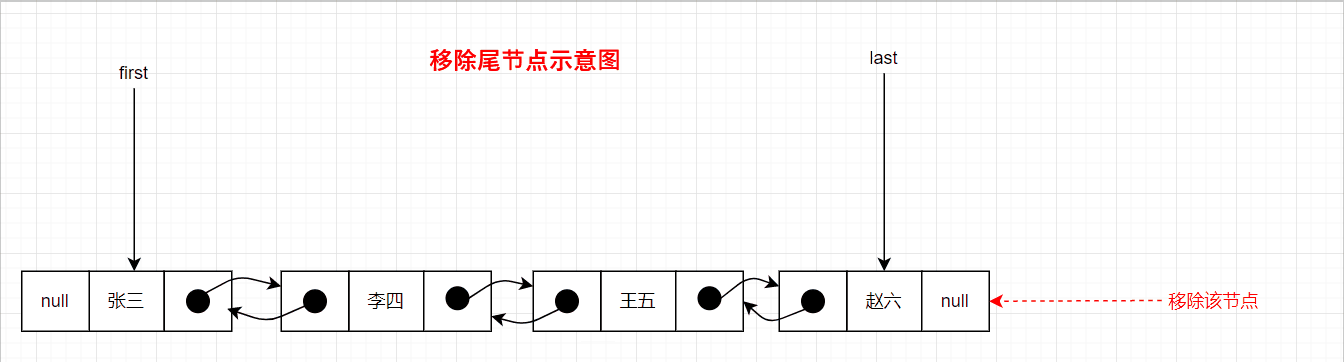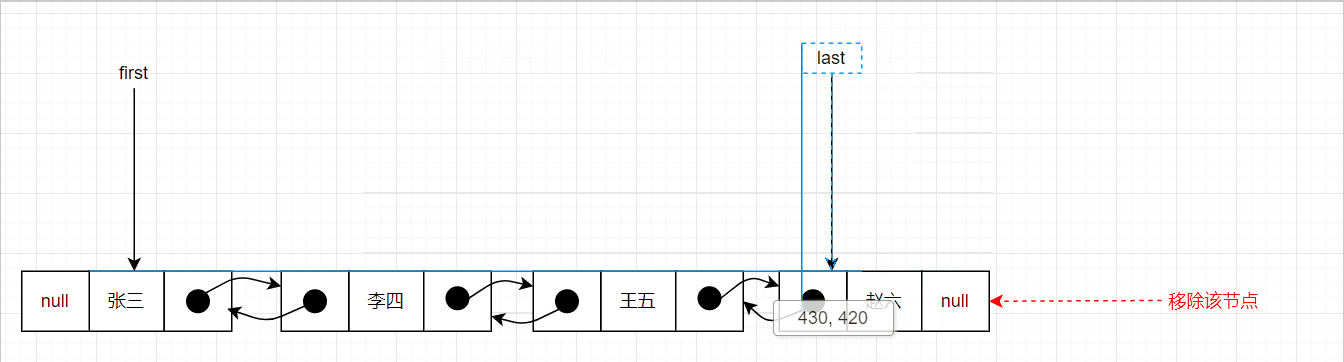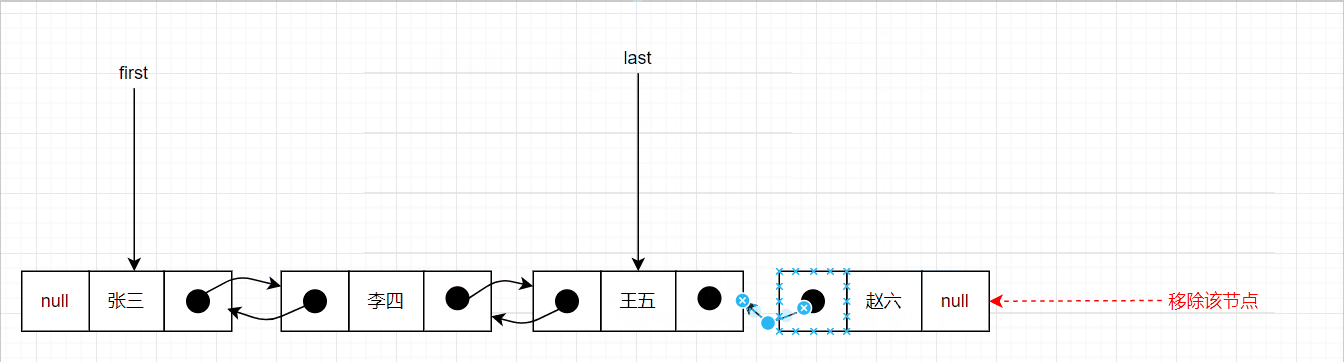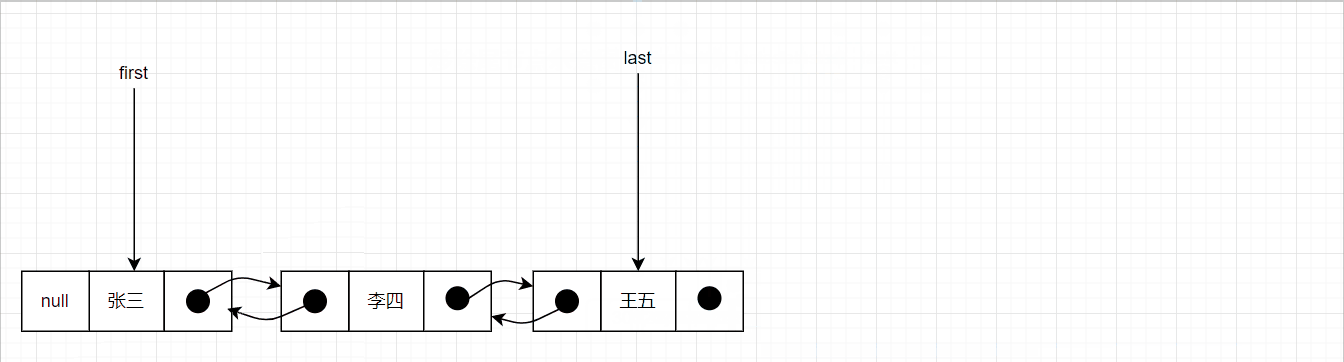
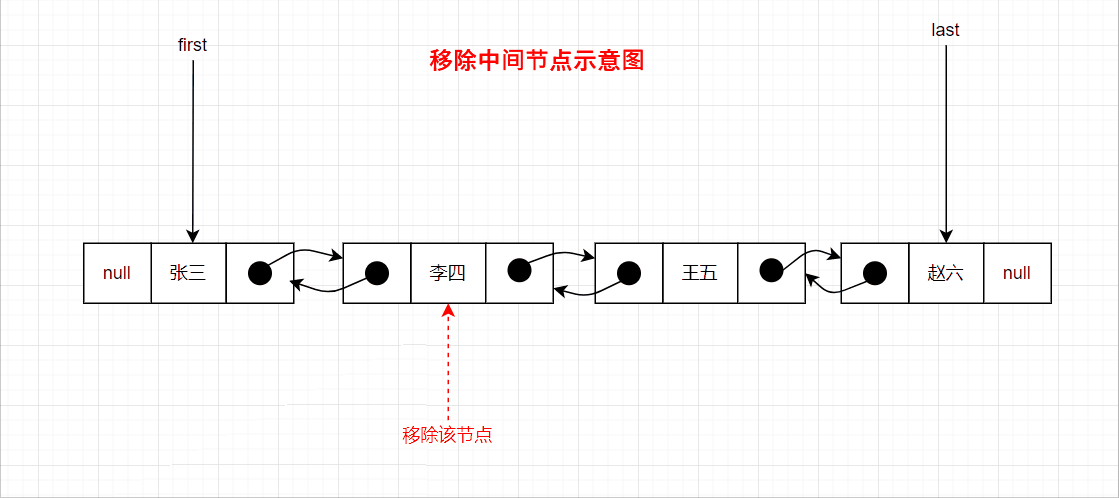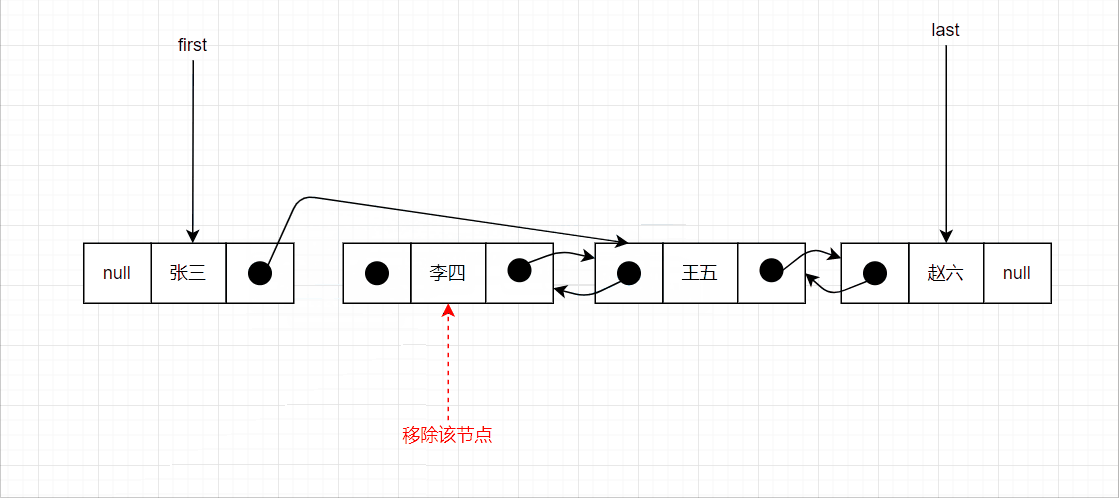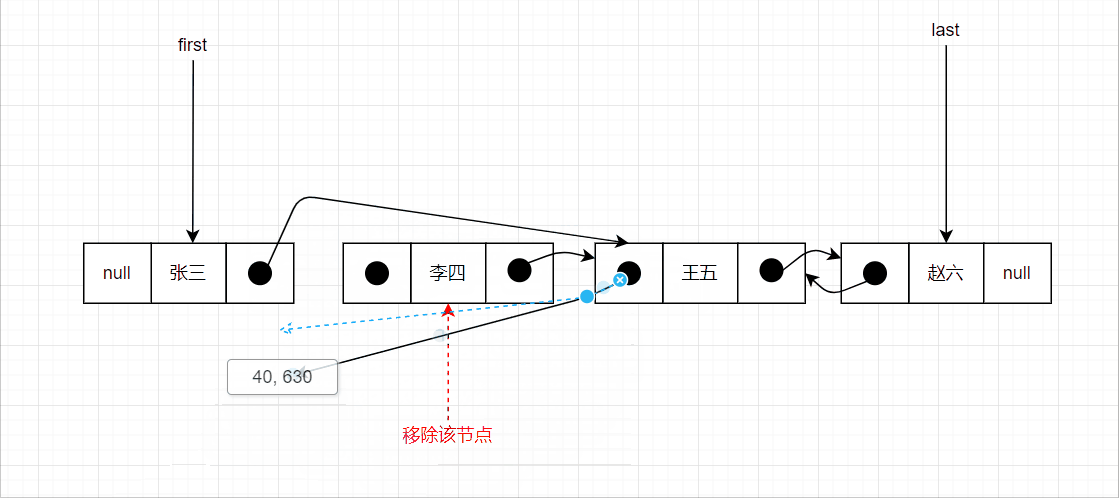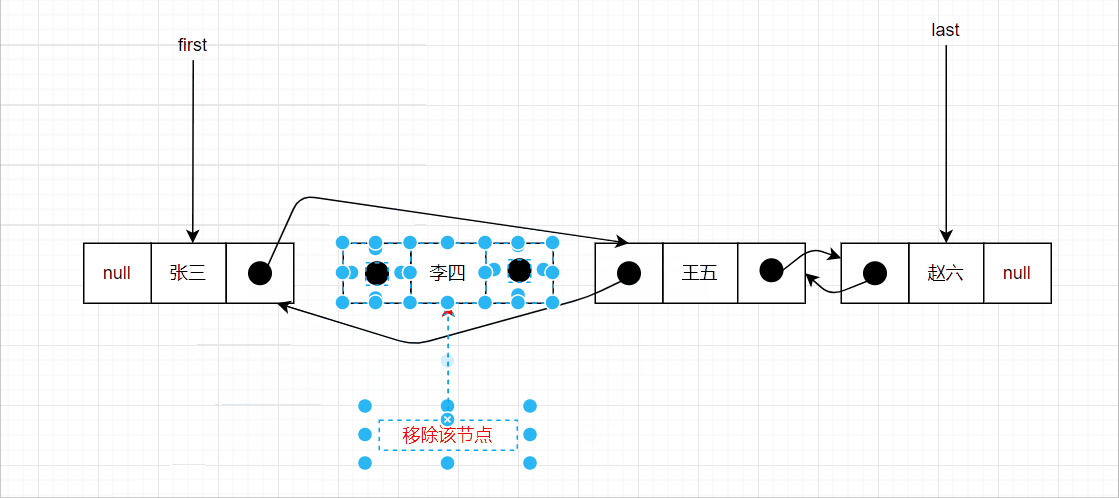
删除中间节点的示意图如下:
数组VS链表
接下来看下看下数组和链表的优缺点以及什么情况下用链表,什么时候用数组。
- 数组
- 优点
- 能够随机查询,查询速度快,时间复杂度为O(1)。
- 缺点:
- 插入和删除的效率低,时间复杂度为O(n)。插入和删除都涉及到移动相关的元素。
- 数据大小固定,可能会造成空间浪费。
- 优点
- 链表
- 优点
- 插入和删除效率高,时间复杂度为O(1)。
- 缺点
- 不能随机查找,查找效率低,时间复杂度为O(n)。查询时需要遍历链表的节点。
- 优点
那什么情况下用链表,什么时候用数组呢?插入和删除操作多的话就用链表,需要经常获取元素时就用数组。
本文来自博客园,作者:coder-qi,转载请注明原文链接:https://www.cnblogs.com/coder-qi/p/algs-linkedlist.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号