学生课程分数
点击查看代码
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)
url = "file:///home/hadoop/input/sc.txt"
scm=sc.textFile(url).map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])])
# 持久化
scm.cache()
# 总共有多少学生
scm.map(lambda a:a[0]).distinct().count()
# 开设了多少门课
scm.map(lambda a:a[1]).distinct().count()
# 转化为键值对
name = scm.map(lambda a:(a[0],(a[1],a[2])))
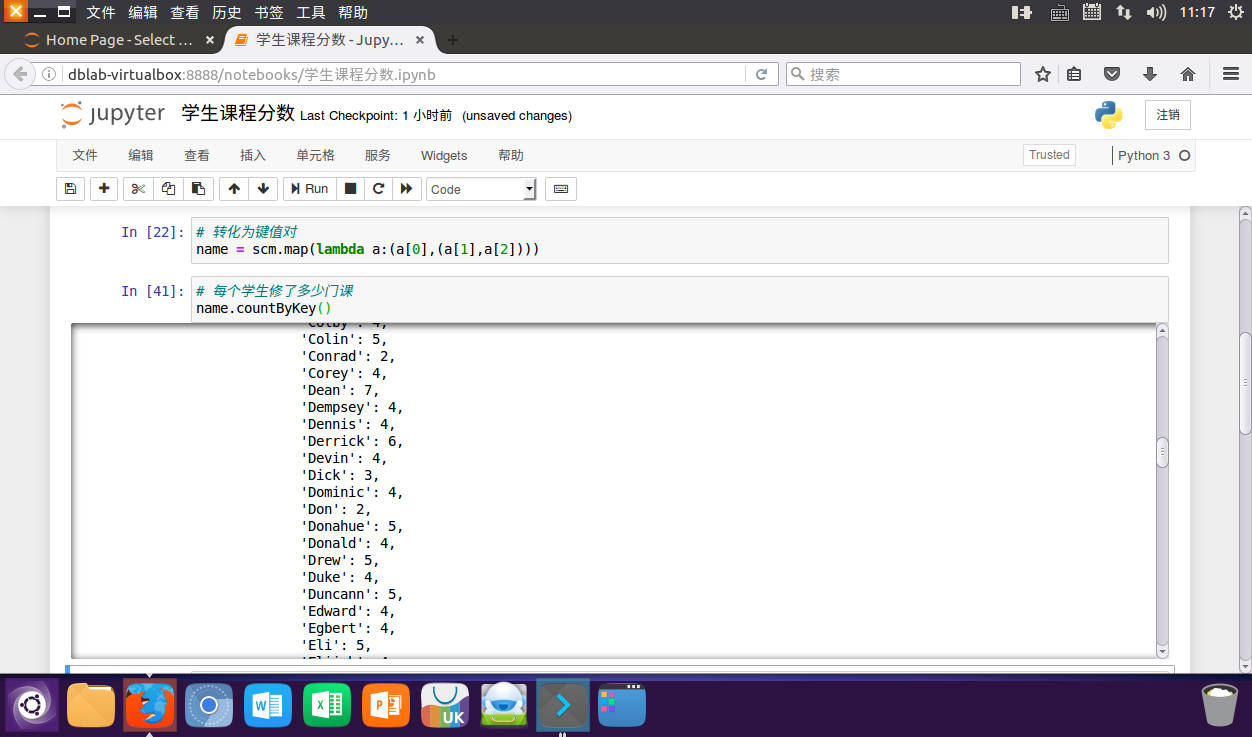
# 每个学生修了多少门课
name.countByKey()
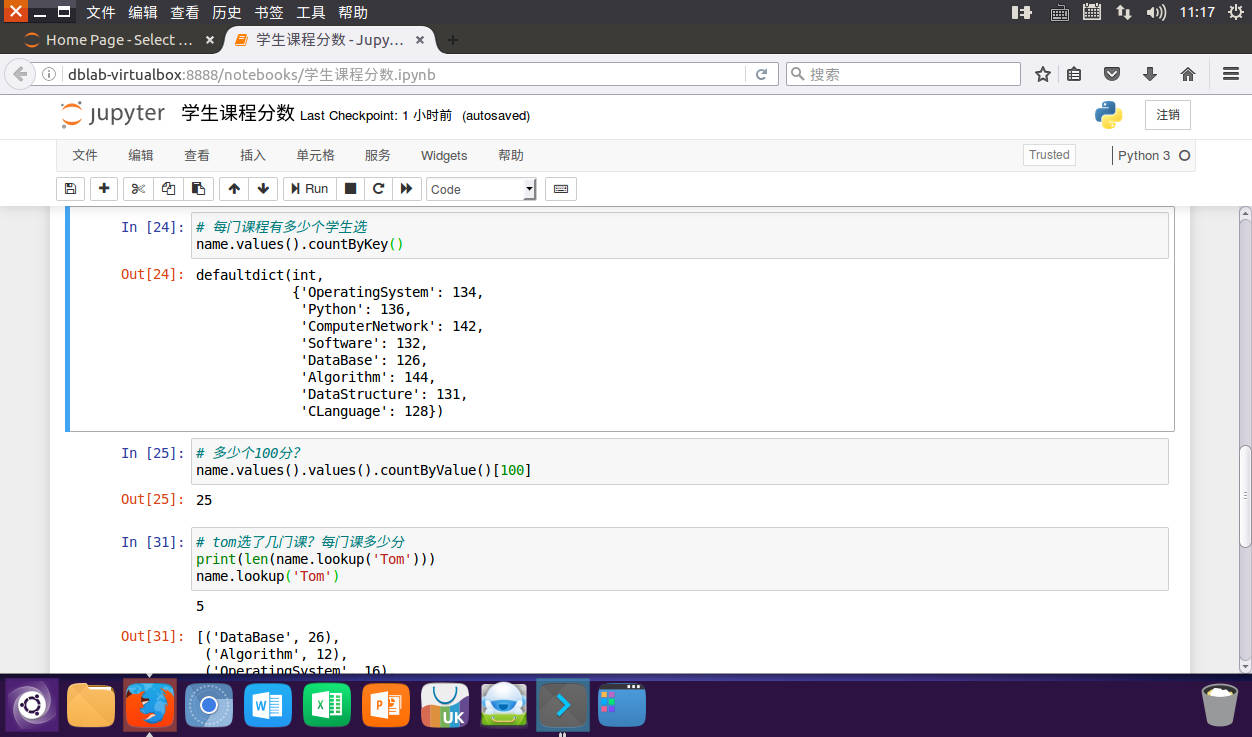
# 每门课程有多少个学生选
name.values().countByKey()
# 有多少个100分
name.values().values().countByValue()[100]
# tom选了几门课?每门课多少分
print(len(name.lookup('Tom')))
name.lookup('Tom')
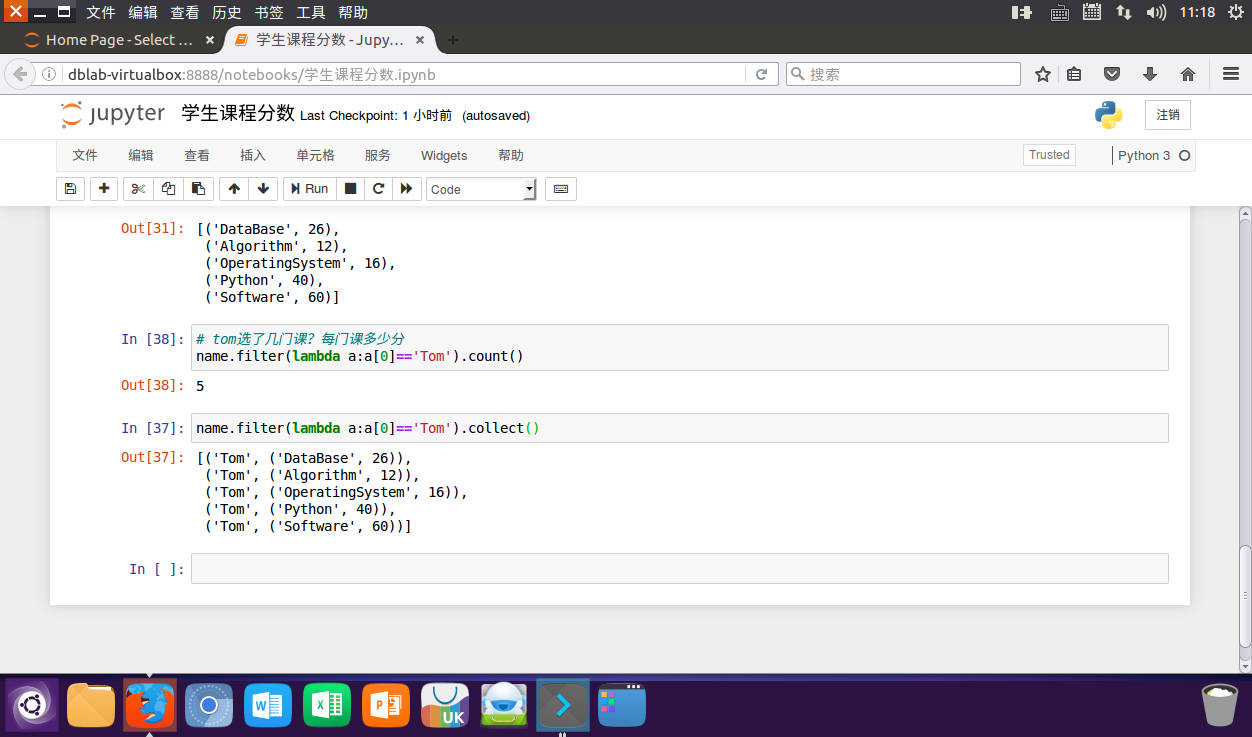
# tom选了几门课?每门课多少分
name.filter(lambda a:a[0]=='Tom').count()
name.filter(lambda a:a[0]=='Tom').collect()
# Tom的成绩按分数大小排序
name.filter(lambda a:a[0]=='Tom').sortBy(lambda a:a[1],False).collect()
# Tom的平均分
np.mean(name.filter(lambda a:a[0]=='Tom').values().values().collect())
# 每个分数+20平时分,并查看不及格人数的变化
name.filter(lambda a:a[1][1]<60).count()
notpass=name.map(lambda a:(a[0],(a[1][0],a[1][1]*0.8+20)))
notpass.filter(lambda a:a[1][1]<60).count()
notpass2=scm.map(lambda a:((a[0],a[1]),a[2])).mapValues(lambda v:v*0.8+20)
notpass2.filter(lambda a:a[1]<60).count()
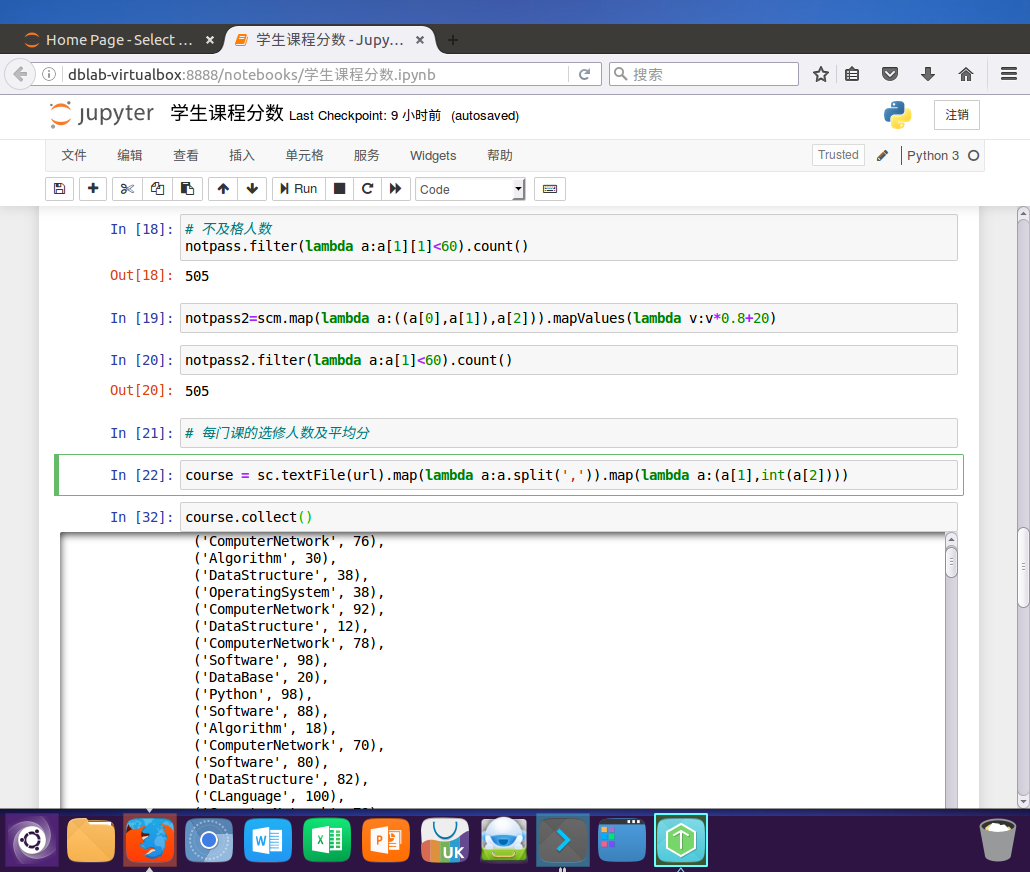
# 求每门课的选修人数及平均分
course = sc.textFile(url).map(lambda a:a.split(',')).map(lambda a:(a[1],int(a[2])))
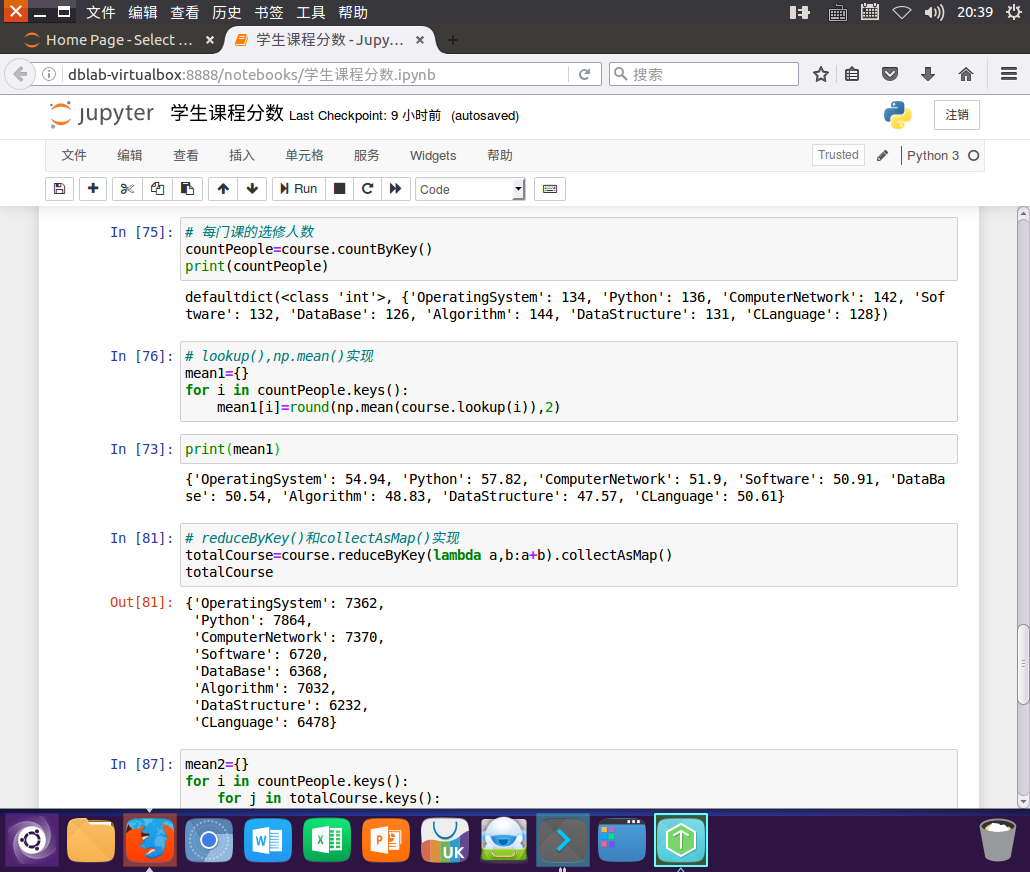
# 每门课的选修人数
countPeople=course.countByKey()
print(countPeople)
# lookup(),np.mean()实现
mean1={}
for i in countPeople.keys():
mean1[i]=round(np.mean(course.lookup(i)),2)
# lookup(),np.mean()实现
mean1={}
for i in countPeople.keys():
mean1[i]=round(np.mean(course.lookup(i)),2)
# lookup(),np.mean()实现
mean1={}
for i in countPeople.keys():
mean1[i]=round(np.mean(course.lookup(i)),2)
print(mean1)
# reduceByKey()和collectAsMap()实现
totalCourse=course.reduceByKey(lambda a,b:a+b).collectAsMap()
totalCourse
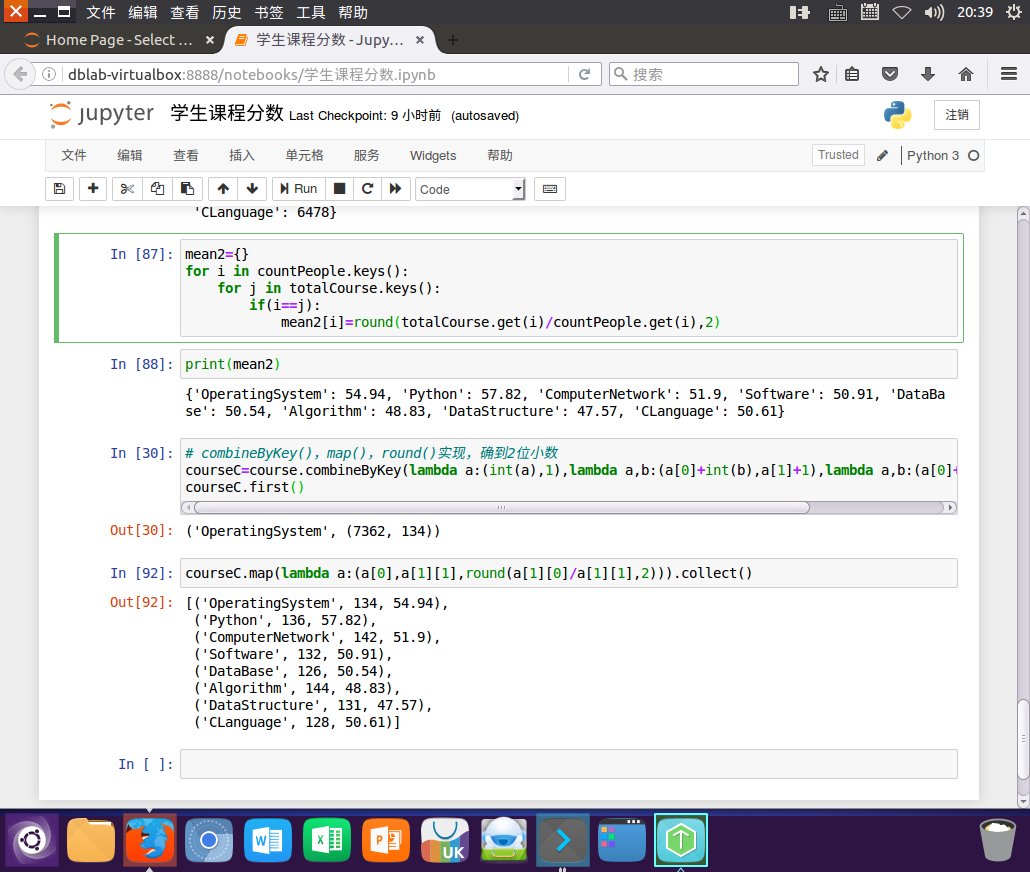
mean2={}
for i in countPeople.keys():
for j in totalCourse.keys():
if(i==j):
mean2[i]=round(totalCourse.get(i)/countPeople.get(i),2)
print(mean2)
# combineByKey(),map(),round()实现,确到2位小数
courseC=course.combineByKey(lambda a:(int(a),1),lambda a,b:(a[0]+int(b),a[1]+1),lambda a,b:(a[0]+b[0],a[1]+b[1]))
courseC.first()
courseC.map(lambda a:(a[0],a[1][1],round(a[1][0]/a[1][1],2))).collect()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()




 浙公网安备 33010602011771号
浙公网安备 33010602011771号