词频统计
A. 分步骤实现
点击查看代码
# 创建sc
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)
# 获取hdfs上的文本文件pinia.txt
lines = sc.textFile("pinia.txt")
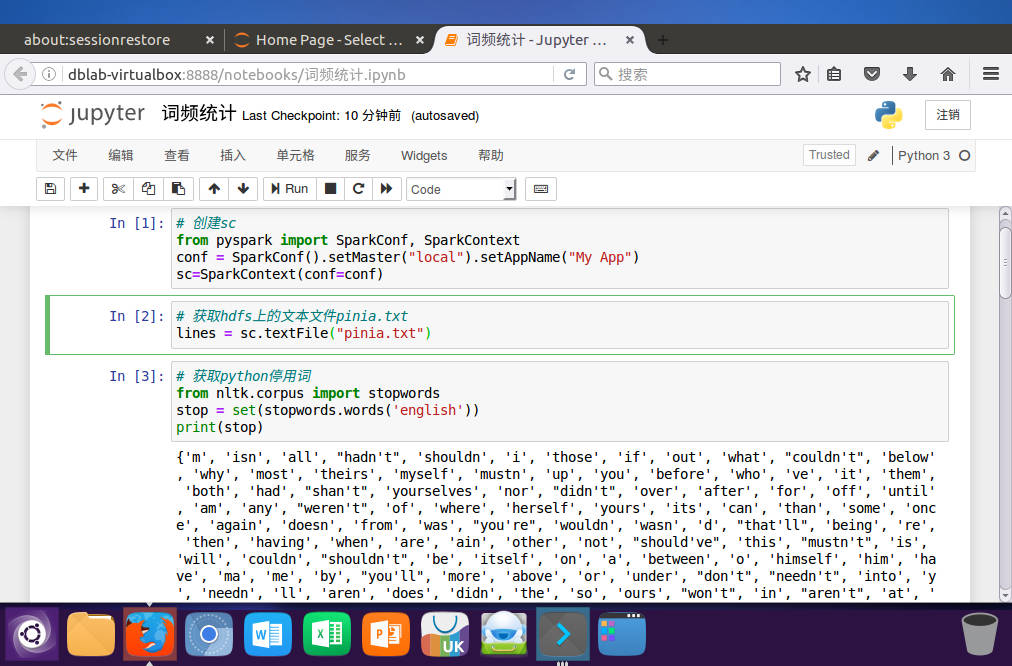
# 获取python停用词
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
print(stop)
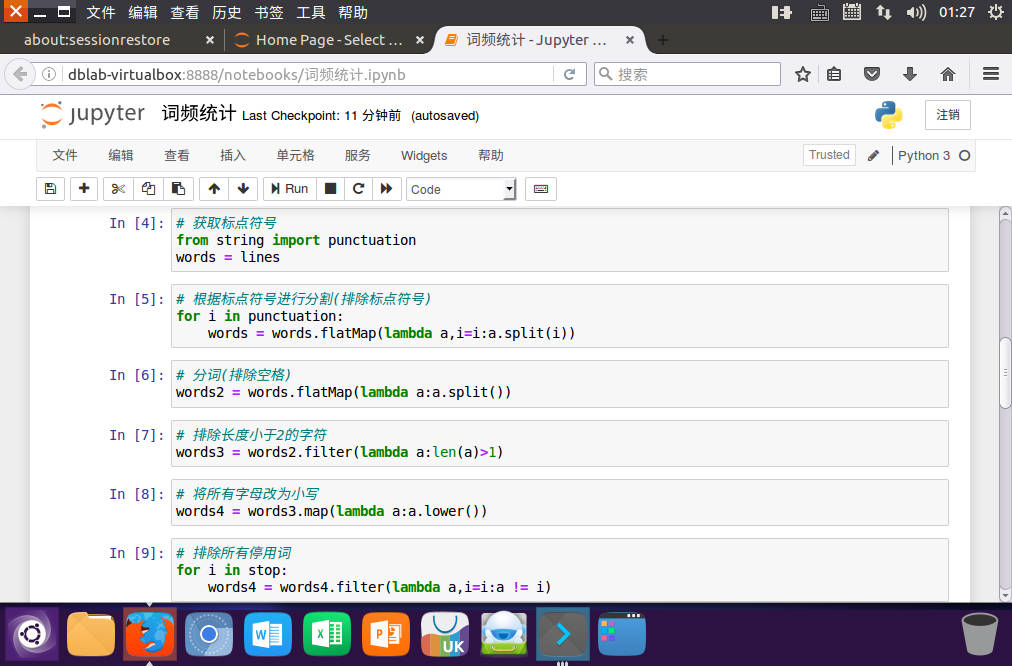
# 获取标点符号
from string import punctuation
words = lines
# 根据标点符号进行分割(排除标点符号)
for i in punctuation:
words = words.flatMap(lambda a,i=i:a.split(i))
# 分词(排除空格)
words2 = words.flatMap(lambda a:a.split())
# 排除长度小于2的字符
words3 = words2.filter(lambda a:len(a)>1)
# 将所有字母改为小写
words4 = words3.map(lambda a:a.lower())
# 排除所有停用词
for i in stop:
words4 = words4.filter(lambda a,i=i:a != i)
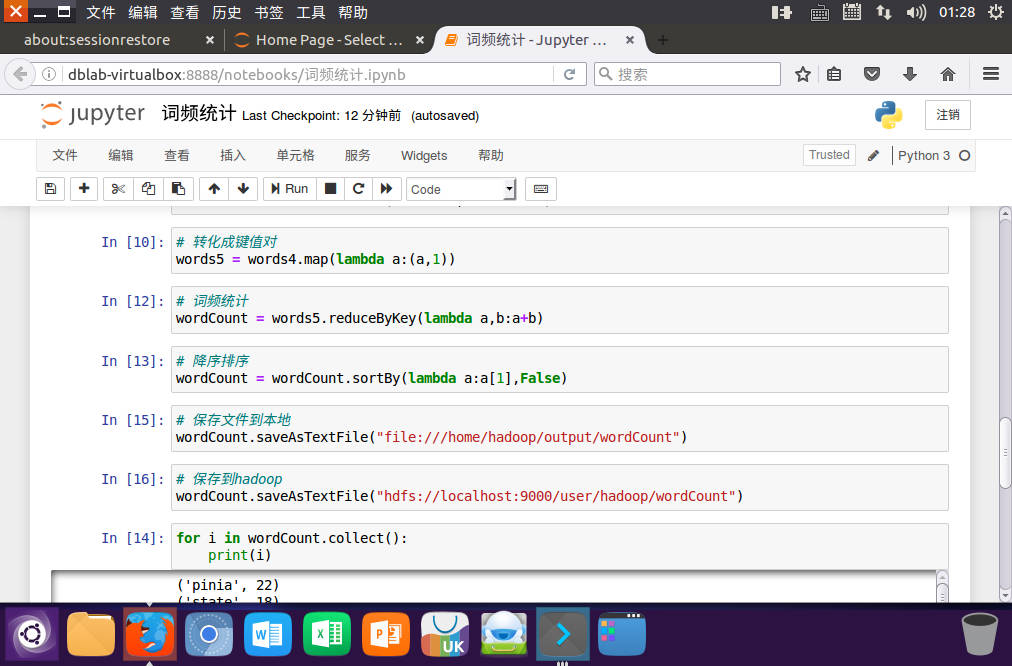
# 转化成键值对
words5 = words4.map(lambda a:(a,1))
# 词频统计
wordCount = words5.reduceByKey(lambda a,b:a+b)
# 降序排序
wordCount = wordCount.sortBy(lambda a:a[1],False)
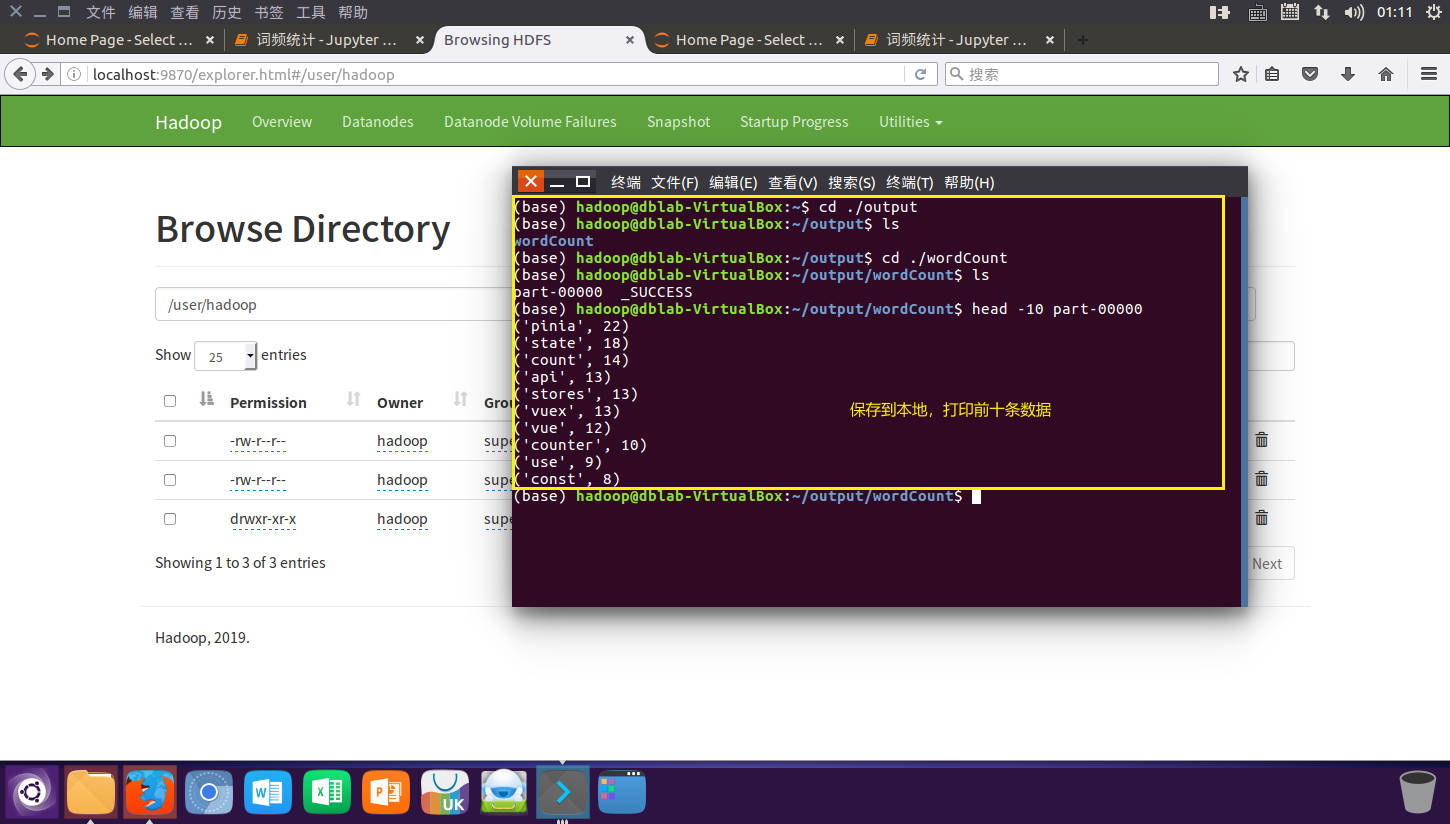
# 保存文件到本地
wordCount.saveAsTextFile("file:///home/hadoop/output/wordCount")
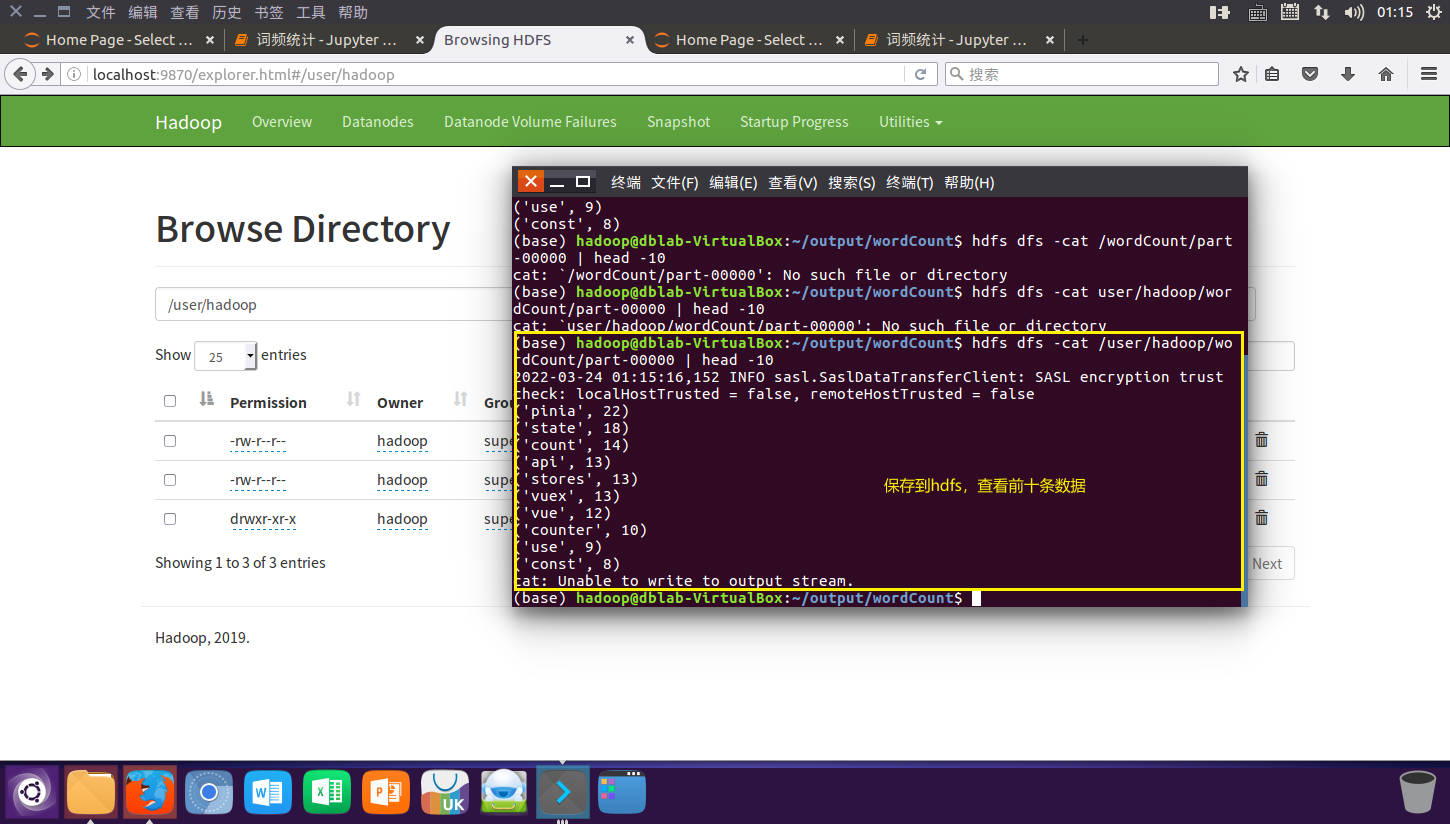
# 保存到hadoop
wordCount.saveAsTextFile("hdfs://localhost:9000/user/hadoop/wordCount")
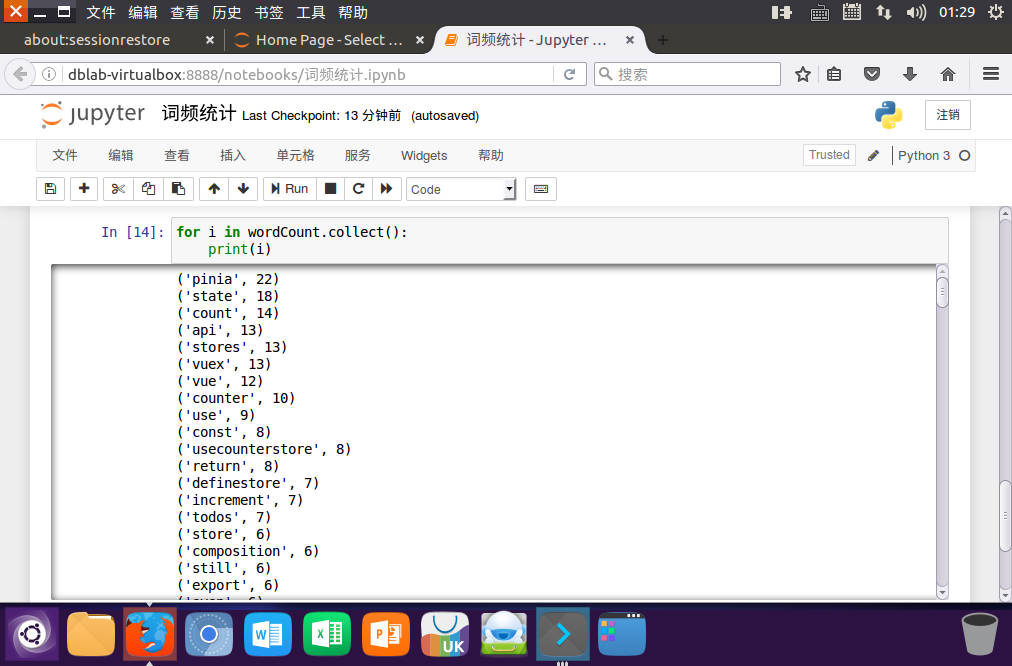
for i in wordCount.collect():
print(i)
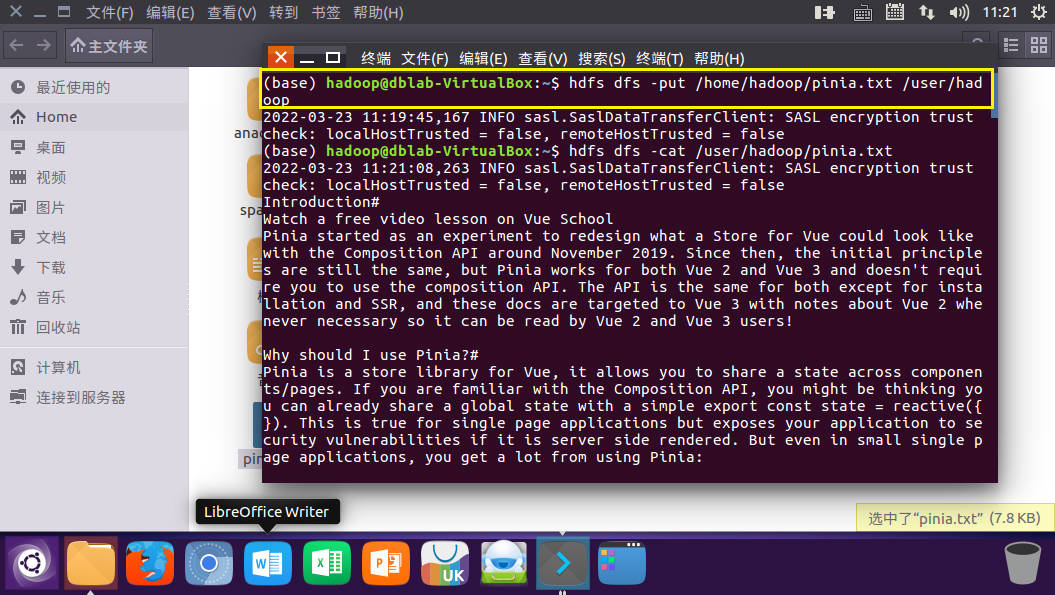
准备文件,上传到hdfs上
![image]()
读文件创建RDD
![image]()
分词、排除大小写,标点符号,停用词,长度小于2的词
![image]()
统计词频、排序
![image]()
输出
![image]()
输出到文件
本地
![image]()
hadoop
![image]()
B. 一句话实现:文件入文件出
求top值
点击查看代码
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)
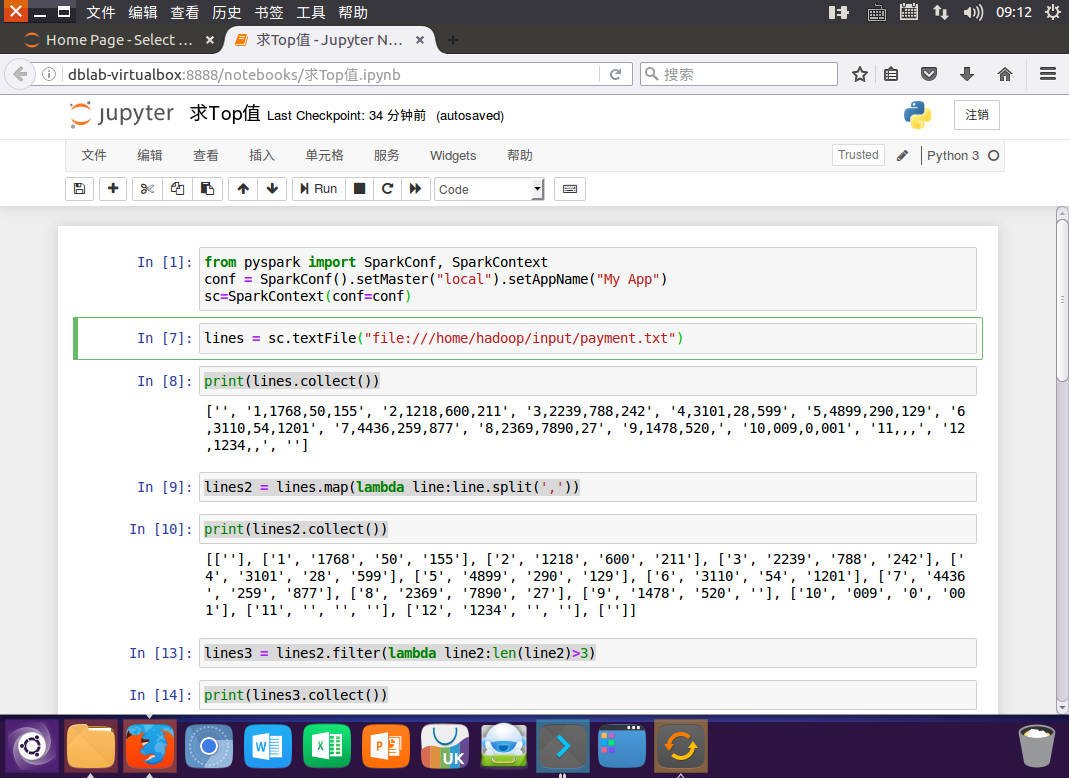
lines = sc.textFile("file:///home/hadoop/input/payment.txt")
print(lines.collect())
lines2 = lines.map(lambda line:line.split(','))
print(lines2.collect())
lines3 = lines2.filter(lambda line2:len(line2)>3)
print(lines3.collect())
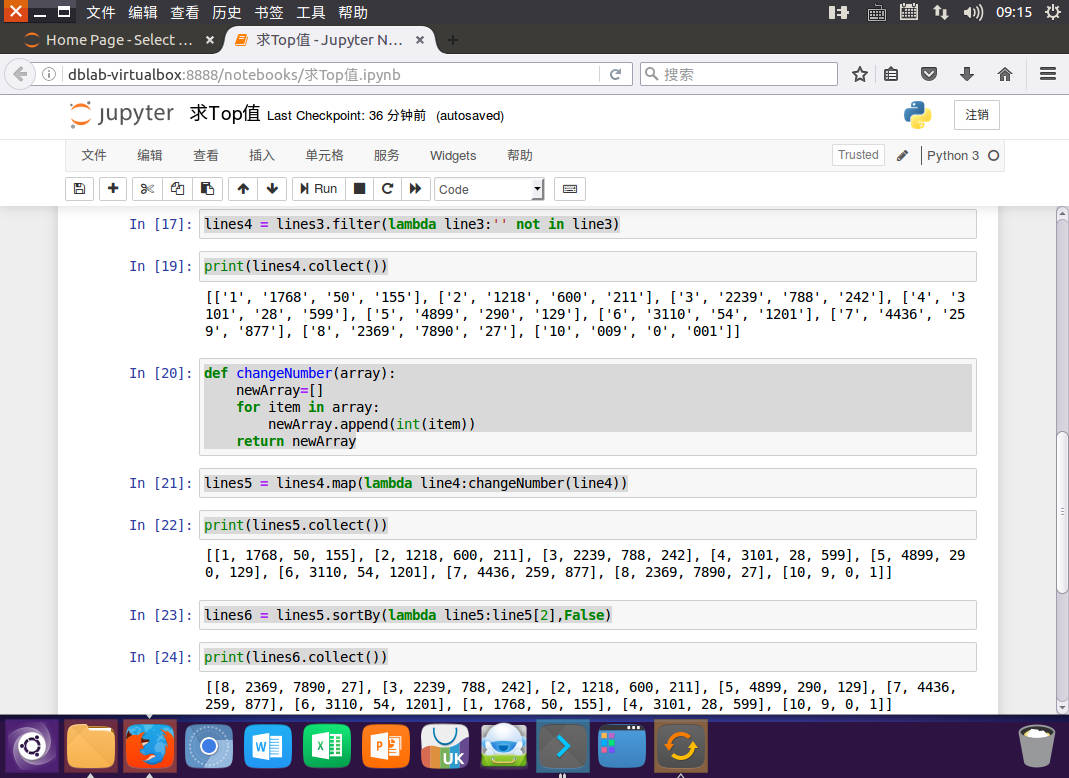
lines4 = lines3.filter(lambda line3:'' not in line3)
print(lines4.collect())
def changeNumber(array):
newArray=[]
for item in array:
newArray.append(int(item))
return newArray
lines5 = lines4.map(lambda line4:changeNumber(line4))
print(lines5.collect())
lines6 = lines5.sortBy(lambda line5:line5[2],False)
print(lines6.collect())
top3 = lines6.take(3)
print(top3)
![]()
![]()
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号