18.哈夫曼编码
哈夫曼(Huffman)编码算法是基于二叉树构建编码压缩结构的,它是数据压缩中经典的一种算法。算法根据文本字符出现的频率,重新对字符进行编码。
首先请大家阅读下面两段中外小学作文:
中国- 今天天气晴朗,我和小明出去玩!小明贪玩,不小心摔了一跤,小明被摔得哇哇哭了,小明的爸爸闻声赶来,又把小明痛扁了一阵。小明的小屁屁都被揍扁了,因为小明把妈妈刚买给他的裤子弄破了!
外国- 今天天气晴朗,我和乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿出去玩!乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿贪玩,不小心摔了一跤,乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿被摔得哇哇哭了,乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿的爸爸闻声赶来,又把乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿痛扁了一阵。乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿的小屁屁都被揍扁了,因为乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿把妈妈刚买给他的裤子弄破了!
同一段内容,当小明换成了外国小朋友的名字,篇幅就增加了几倍,有没有办法把内容缩减呢?
当然有!在文章的开头,先声明一个缩写:
| 名字 | 缩写 |
|---|---|
| 乔伊·亚历山大·比基·卡利斯勒·达夫·埃利奥特·福克斯·伊维鲁莫·马尔尼·梅尔斯·帕特森·汤普森·华莱士·普雷斯顿 | 乔顿 |
那么,上面这段文字就可以缩成很小的一段:
今天天气晴朗,我和乔顿出去玩!乔顿贪玩,不小心摔了一跤,乔顿被摔得哇哇哭了,乔顿的爸爸闻声赶来,又把小明痛扁了一阵。乔顿的小屁屁都被揍扁了,因为乔顿把妈妈刚买给他的裤子弄破了!
哈夫曼编码就是这样一个原理!按照文本字符出现的频率,出现次数越多的字符用越简短的编码替代,因为为了缩短编码的长度,我们自然希望频率越高的词,编码越短,这样最终才能最大化压缩存储文本数据的空间。
哈夫曼编码举例: 假设要对“we will we will r u”进行压缩。
压缩前,使用ASCII 码保存:
| 119 | 101 | 32 | 119 | 105 | 108 | 108 | 32 | 119 | 101 | 32 | 119 | 105 | 108 | 108 | 32 | 114 | 32 | 117 |
|---|
共需: 19 个字节-152 个位保存
下面我们先来统计这句话中每个字符出现的频率。如下表,按频率高低已排序:
| 字符 | 空格 | w | l | e | i | r | u |
|---|---|---|---|---|---|---|---|
| 频率 | 5 | 4 | 4 | 2 | 2 | 1 | l |
接下来,我们按照字符出现的频率,制定如下的编码表:
| 字符 | l | w | 空格 | e | i | u | r |
|---|---|---|---|---|---|---|---|
| 频率 | 00 | 01 | 10 | 110 | 1111 | 11100 | 11101 |
这样,“we will we will r u”就可以按如下的位来保存:
01 110 10 01 1111 00 00 10 01 110 10 01 1111 00 00 10 11101 10 11100
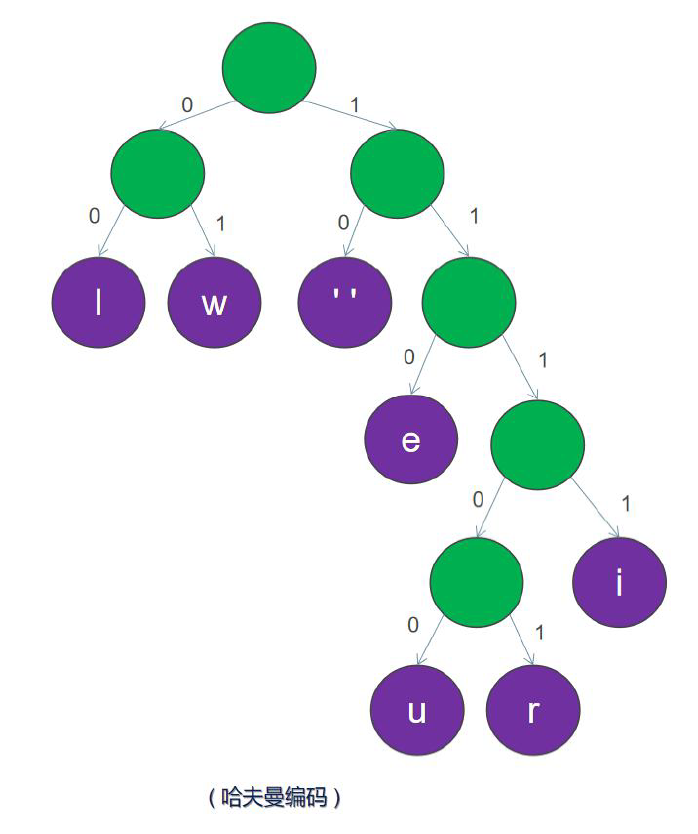
1.哈夫曼二叉树构建
1.1按出现频率高低将其放入一个数组中,从左到右依次为频率逐渐增加


1.2从左到右进行合并,依次构建二叉树。第一步取前两个字符u 和r 来构造初始二叉树,第一个字符作为左节点,第二个元素作为右节点,然后两个元素相加作为新的空元素,并且两者权重相加作为新元素的权重。

1.3新节点加入后,依据权重重新排序,按照权重从小到大排列,上图已有序。
1.4红色区域的新增元素可以继续和i合并,如下图所示:
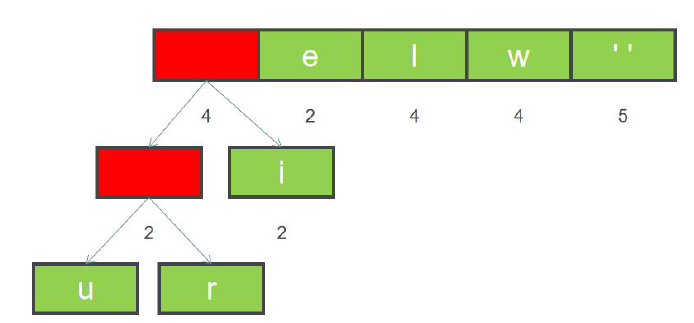
1.5合并节点后, 按照权重从小到大排列,如下图所示。

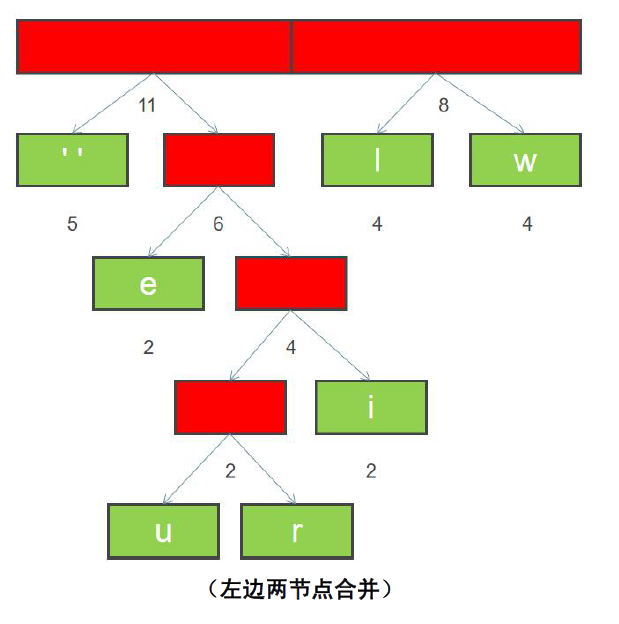
1.6排序后,继续合并最左边两个节点,构建二叉树,并且重新计算新节点的权重

1.7重新排序

1.8重复上面步骤6 和7,直到所有字符都变成二叉树的叶子节点





参考资料来源:
奇牛学院

 浙公网安备 33010602011771号
浙公网安备 33010602011771号