
浅析索引
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
一. 索引结构(方法、算法)
在mysql中常用两种索引结构(算法)B+Tree和Hash
1. B+树
B+Tree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:* select * from user where name like 'jack%'; select * from user where name like 'jac%k%'; 如果一通配符开头,或者没有使用常量,则不会使用索引,而是使用全表扫描,例如: select * from user where name like '%jack'; select * from user where name like simply_name;(最左前缀原则)
2.hash
二. 索引方式
Mysql数据库中的B+树索引可以分为聚集索引和二级索引(辅助索引)
1.聚集索引


![]()
结构:
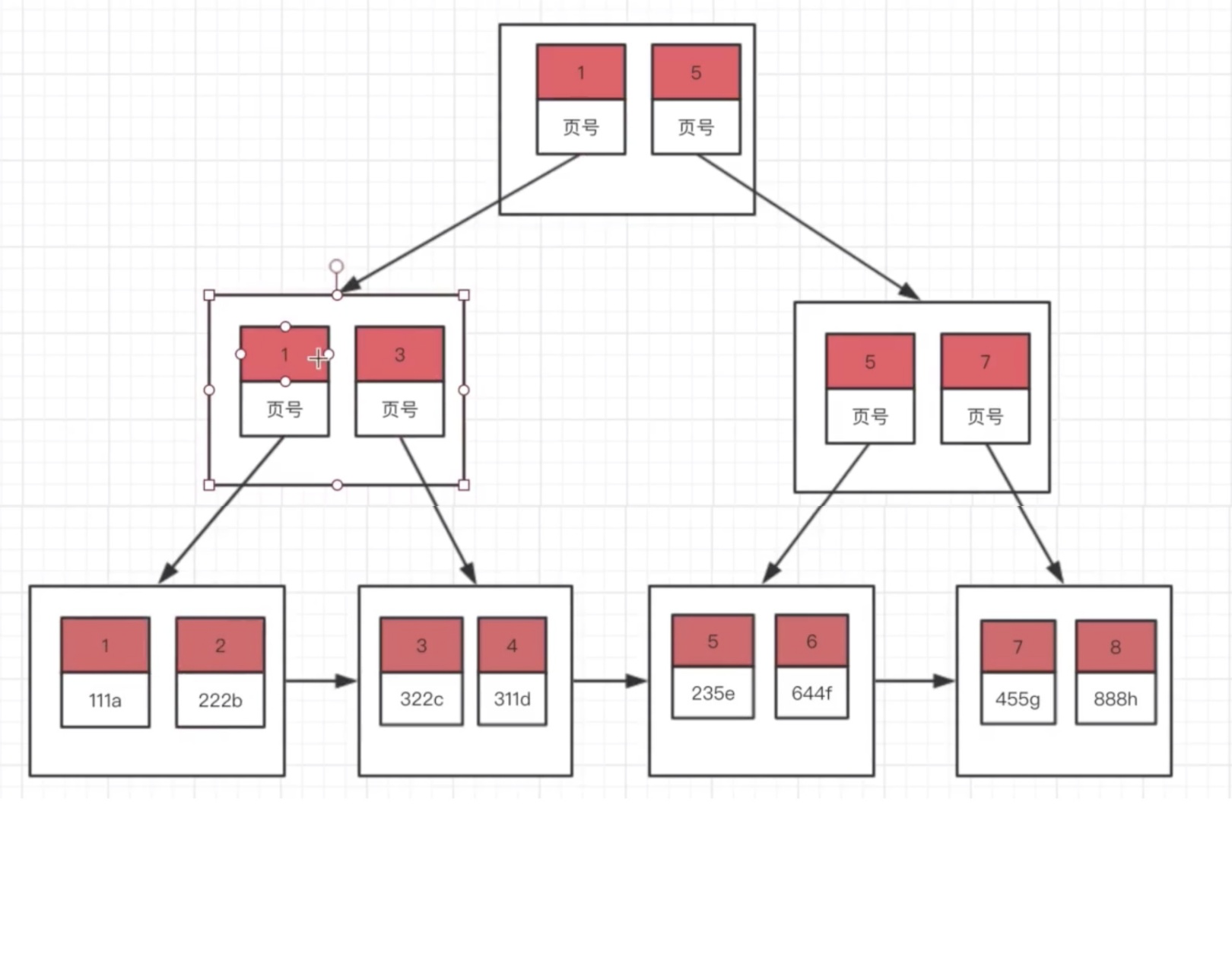
(1)按主键值的大小进行记录和页的排序:
数据页(叶子节点)里的记录是按照主键值从小到大排序的一个单向链表。
数据页(叶子节点)之间也是是按照主键值从小到大排序的一个双向链表。
B+树中同一个层的页目录也是按照主键值从小到大排序的一个双向链表。
(2)B+树的叶子节点存储的是完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
聚集索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建。InnoDB存储引擎会自动的为我们创建聚集索引(设置默认主键)。 在InnoDB存储引擎中,聚集索引就是数据的存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。
2.二级索引(复制索引、辅助索引)
当我们想以别的列(们)作为搜索条件时我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。

![]()
结构:
first:
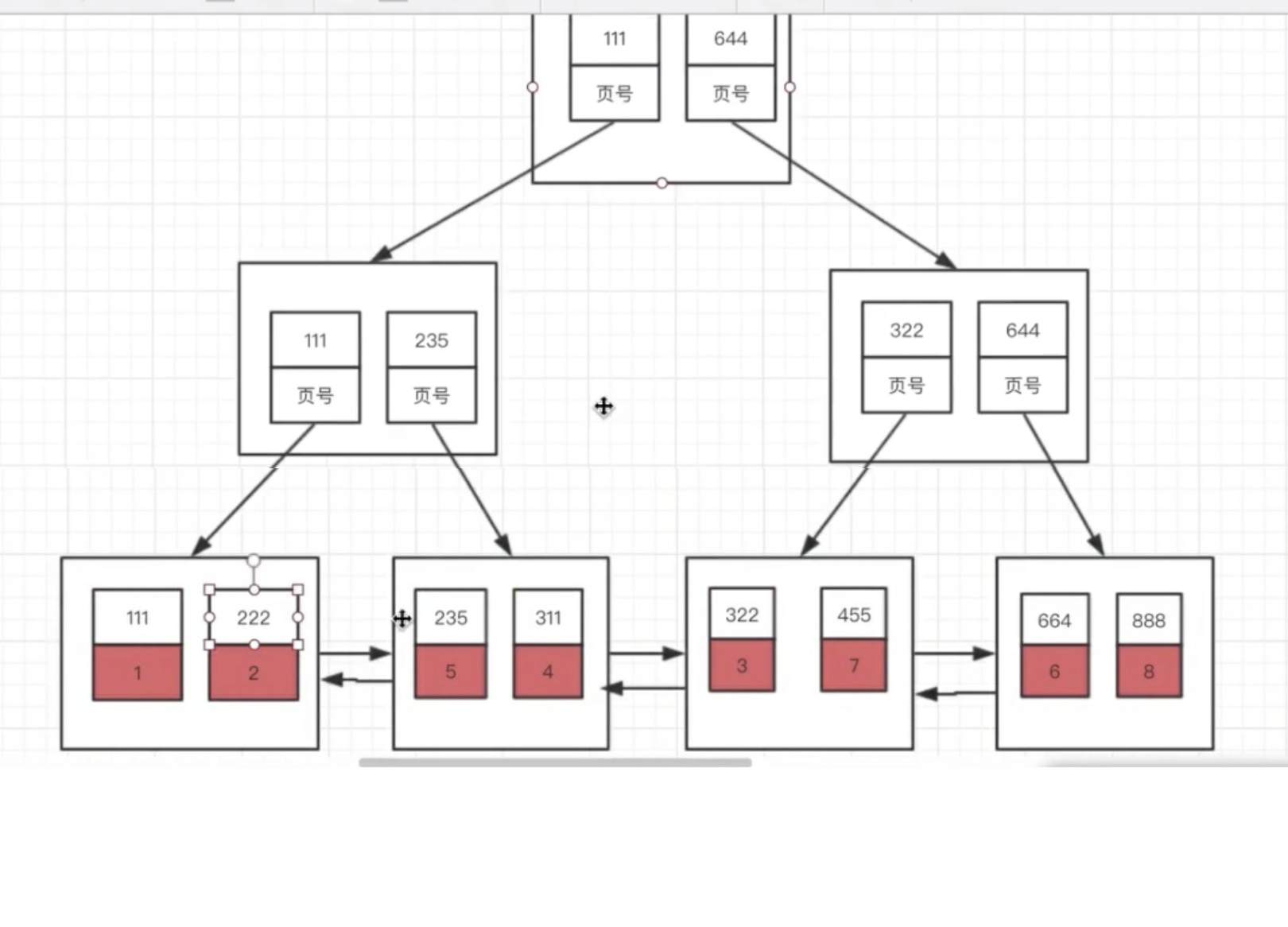
辅助索引(利用自定义的索引)
next:
聚集索引(根据主键)
二级索引与聚集索引有几处不同:
(1)按指定的索引列的值来进行排序
(2)叶子节点存储的不是完整的用户记录,而只是索引列+主键。
(3)目录项记录中不是主键+页号(地址),变成了索引列+页号(地址)。
(4)在对二级索引进行查找数据时,现在二级索引中找到所需主键值,再根据主键值去聚集索引中再查找一遍完整的用户记录,这个过程叫做回表
3.联合索引
以多个列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引。
4.最左前缀原则
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引
查询的时候如果两个条件都用上了,但是顺序不同,如 city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
————————————————
版权声明:本段为CSDN博主「海洋之心kkk」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kqqkqq123/article/details/98057744
三、总结
-
每个索引都对应一棵B+树。用户记录都存储在B+树的叶子节点,所有目录记录都存储在非叶子节点。
-
InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录。
-
可以为指定的列建立二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再到聚簇索引中查找完整的用户记录。
-
B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。
-
通过索引查找记录是从B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了页目录,所以在这些页面中的查找非常快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号