
集群故障处理之处理思路以及健康状态检查(三十二)
前言
按照笔者的教程,大家应该都能够比较顺畅的完成k8s集群的部署,不过由于环境、配置以及对Linux、k8s的不了解会导致很多问题、异常和故障,这里笔者分享一些处理技巧和思路,以及部分常见的问题,以供大家参考和学习。
总之,出现问题不要慌,先根据异常、故障症状初步推敲问题的所在,然后结合相关命令、工具、日志推敲出具体问题。其中,具体的日志内容是关键,请务必获得相关异常的详细日志进行诊断,而不是被表象所迷惑,或者根据表象问题(比如“XXXX”pod崩溃了)去猜、搜索或者请教他人。总体上,思路如下图所示:
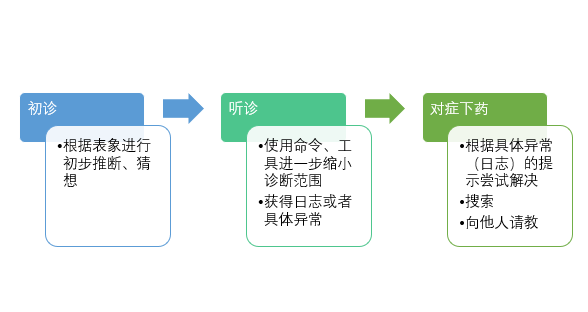
如果问题实在无法解决或者无法确定是哪里的配置以及操作不当引起的,可以试着重置节点以及重置集群。
如果出现问题,我们应该怎么去分析和解决问题呢?下面,笔者将分享一些思路和经验:
目录
健康状态检查——初诊
-
组件、插件健康状态检查
-
Kubernetes 组件异常分析
-
节点健康状态检查
-
Pod健康状态检查
健康状态检查——初诊
首先,我们需要根据表象进行初步诊断,以便沿着线索按图索骥。
组件、插件健康状态检查
使用命令:
kubectl get componentstatus
或
kubectl get cs
健康情况下如下图所示:

Kubernetes组件(插件)部分默认基于systemd运行,比如kubelet、docker等,我们需要使用以下命令确保其处于活动(active)状态:
systemctl status kubelet docker

而大部分的Kubernetes的组件则运行在命名空间为“kube-system”的静态Pod 之中(参见“kubeadm init”一节),我们可以使用以下命令来查看这些Pod 的状态:
kubectl get pods -o wide -n kube-system

Kubernetes 组件异常分析
k8s组件主要分为Master组件和节点组件,Master组件对集群做出全局性决策(比如调度), 以及检测和响应集群事件。如果Master组件出现问题,可能会导致集群不可访问,Kubernetes API 访问出错,各种控制器无法工作等等。而节点组件在每个节点上运行,维护运行的Pod并提供 Kubernetes运行时环境。如果节点组件出现问题,可能会导致该节点异常并且该节点Pod无法正常运行和结束。
因此,根据不同的组件,可能会出现不同的异常。
kube-apiserver对外暴露了Kubernetes API,如果kube-apiserver出现异常可能会导致:
-
集群无法访问,无法注册新的节点
-
资源(Deployment、Service等)无法创建、更新和删除
-
现有的不依赖Kubernetes API的pods和services可以继续正常工作
etcd用于Kubernetes的后端存储,所有的集群数据都存在这里。保持稳定的etcd集群对于Kubernetes集群的稳定性至关重要。因此,我们需要在专用计算机或隔离环境上运行etcd集群以确保资源需求。当etcd出现异常时可能会导致:
-
kube-apiserver无法读写集群状态,apiserver无法启动
-
Kubernetes API访问出错
-
kubectl操作异常
-
kubelet无法访问apiserver,仅能继续运行已有的Pod
kube-controller-manager和kube-scheduler分别用于控制器管理和Pod 的调度,如果他们出现问题,则可能导致:
-
相关控制器无法工作
-
资源(Deployment、Service等)无法正常工作
-
无法注册新的节点
-
Pod无法调度,一直处于Pending状态
kubelet是主要的节点代理,如果节点宕机(VM关机)或者kubelet出现异常(比如无法启动),那么可能会导致:
-
该节点上的Pod无法正常运行,如果节点关机,则当前节点上所有Pod都将停止运行
-
已运行的Pod无法伸缩,也无法正常终止
-
无法启动新的Pod
-
节点会标识为不健康状态
-
副本控制器会在其它的节点上启动新的Pod
-
Kubelet有可能会删掉当前运行的Pod
CoreDNS(在1.11以及以上版本的Kubernetes中,CoreDNS是默认的DNS服务器)是k8s集群默认的DNS服务器,如果其出现问题则可能导致:
-
无法注册新的节点
-
集群网络出现问题
-
Pod无法解析域名
kube-proxy是Kubernetes在每个节点上运行网络代理。如果它出现了异常,则可能导致:
-
该节点Pod通信异常
节点健康状态检查
我们可以使用以下命令来检查节点状态:
kubectl get nodes
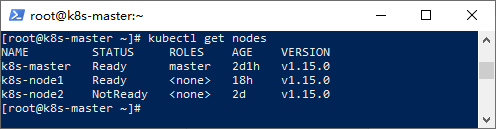
其中,“Ready”表示节点已就绪,为正常状态,反之则该节点出现异常。节点出现问题,则Pod无法无法调度到该节点。
Pod健康状态检查
如果是集群应用出现异常,我们需要检查相关Pod是否运行正常,可以使用以下命令:
kubectl get pods -o wide
如果存在命名空间,需要使用-n参数指定命名空间。如上图所示,Pod为“Running”状态才是正常。
如果Pod运行正常,但是又无法访问(集群内部、外部),这时,我们需要检查Service是否正常,可使用以下命令:
kubectl get svc -o wide

出处:http://www.cnblogs.com/codelove/
如果喜欢作者的文章,请关注【CodeSpirit-码灵】公众号以便第一时间获得最新内容。本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
静听鸟语花香,漫赏云卷云舒。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号