
Docker最全教程之Python爬网实战(二十一)
Python目前是流行度增长最快的主流编程语言,也是第二大最受开发者喜爱的语言(参考Stack Overflow 2019开发者调查报告发布)。笔者建议.NET、Java开发人员可以将Python发展为第二语言,一方面Python在某些领域确实非常犀利(爬虫、算法、人工智能等等),另一方面,相信我,Python上手完全没有门槛,你甚至无需购买任何书籍!
由于近期在筹备4.21的长沙开发者大会,耽误了不少时间。不过这次邀请到了腾讯资深技术专家、.NET中国社区领袖,微软MVP张善友;52ABP开源框架的作者,微软MVP梁桐铭;知名技术类作家汪鹏,腾讯高级工程师卓伟,腾讯云高级产品经理胡李伟等等,有兴趣参加的朋友可以点击公众号菜单【联系我们】==>【报名】进行报名,技术不分语言,亦没有界限,期待和你分享、交流!
目录
关于Python
官方镜像
使用Python抓取博客列表
需求说明
了解Beautiful Soup
分析并获取抓取规则
编写代码实现抓取逻辑
编写Dockerfile
运行并查看抓取结果
关于Python
Python是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。Python目前是流行度增长最快的主流编程语言,也是第二大最受开发者喜爱的语言(参考Stack Overflow 2019开发者调查报告发布)。
Python是一种解释型脚本语言,可以应用于以下领域:
- Web 和 Internet开发
- 科学计算和统计
- 教育
- 桌面界面开发
- 软件开发
- 后端开发
Python学习起来没有门槛,但是通过它,你可以用更短的时间,更高的效率学习和掌握机器学习,甚至是深度学习的技能。不过单单只会Python对大多数人来说是不行的,你最好还掌握一门静态语言(.NET/Java)。同时,笔者也建议.NET、Java开发人员可以将Python发展为第二语言,一方面Python在某些领域确实非常犀利(爬虫、算法、人工智能等等),另一方面,相信我,Python上手完全没有门槛,你甚至无需购买任何书籍!
官方镜像
官方镜像地址:https://hub.docker.com/_/python
注意,请认准官方镜像:
使用Python抓取博客列表
需求说明
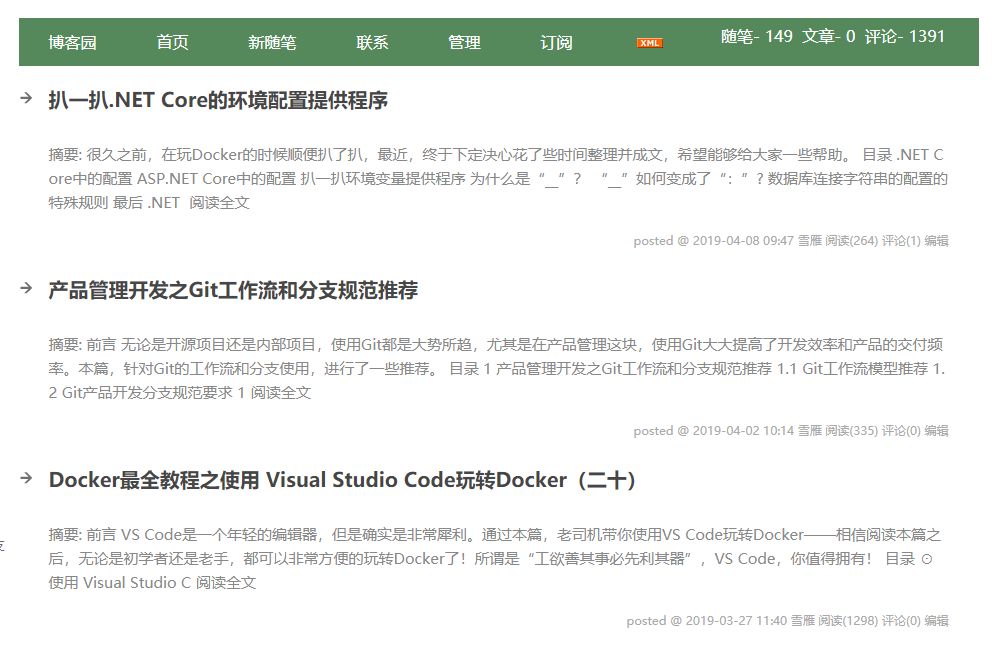
本篇使用Python来抓取我的博客园的博客列表,打印出标题、链接、日期和摘要。
博客地址:http://www.cnblogs.com/codelove/
内容如下所示:
了解Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,支持多种解析器。Beautiful Soup简单的说,就是一个灵活又方便的网页解析库,是一个爬网利器。本篇教程我们就基于Beautiful Soup来抓取博客数据。
Beautiful Soup官方网站:https://beautifulsoup.readthedocs.io
主要解析器说明:

分析并获取抓取规则
首先我们使用Chrome浏览器打开以下地址:http://www.cnblogs.com/codelove/
然后按下F12打开开发人员工具,通过工具我们梳理了以下规则:
- 博客块(div.day)
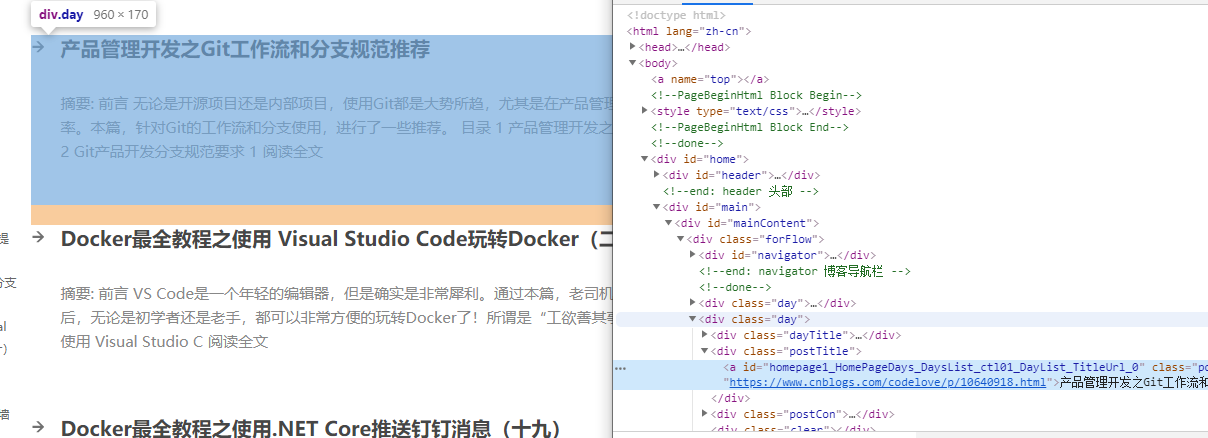
- 博客标题(div. postTitle a)
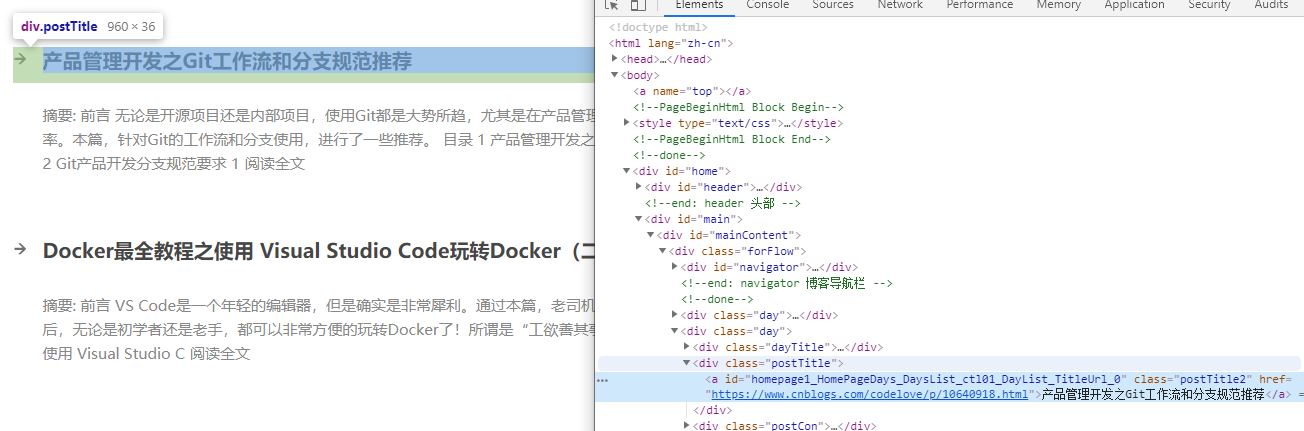
- 其他内容获取,如日期、博客链接、简介,这里我们就不截图了。
然后我们通过观察博客路径,获取到url分页规律:
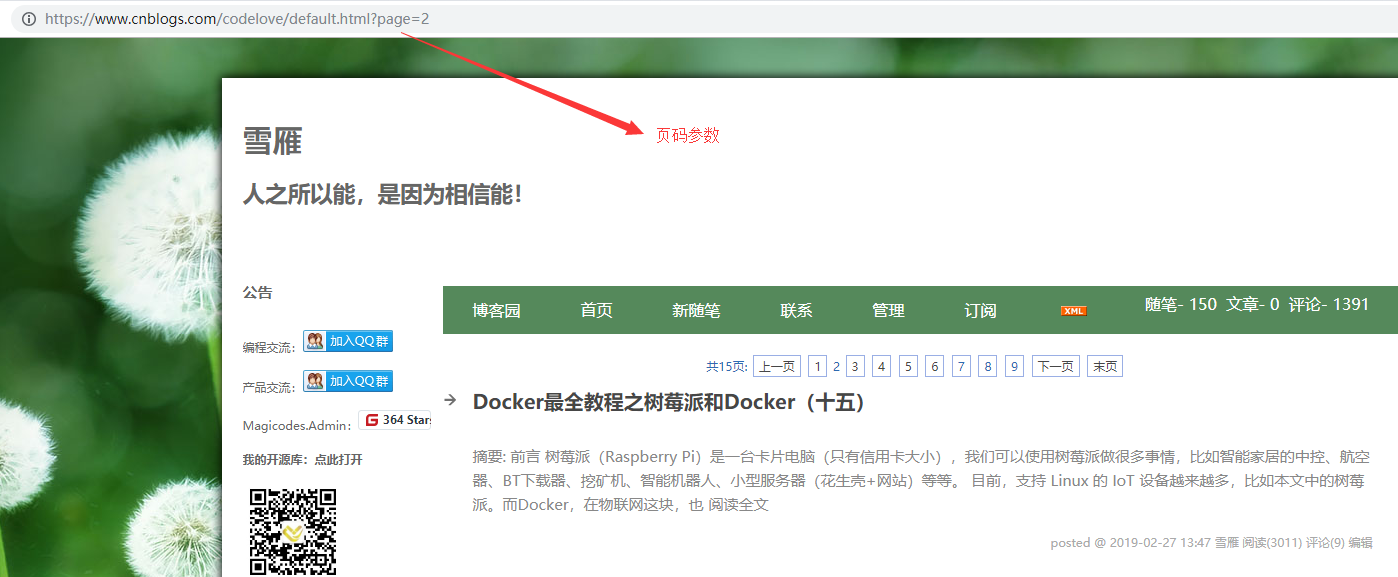
根据以上分析,我们胸有成竹,开始编码。
编写代码实现抓取逻辑
在编码前,请阅读BeautifulSoup官方文档。然后根据需求,我们编写Python的代码如下所示:
# 关于BeautifulSoup,请阅读官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id52
from bs4 import BeautifulSoup
import os
import sys
import requests
import time
import re
url = "https://www.cnblogs.com/codelove/default.html?page={page}"
#已完成的页数序号,初时为0
page = 0
while True:
page += 1
request_url = url.format(page=page)
response = requests.get(request_url)
#使用BeautifulSoup的html5lib解析器解析HTML(兼容性最好)
html = BeautifulSoup(response.text,'html5lib')
#获取当前HTML的所有的博客元素
blog_list = html.select(".forFlow .day")
# 循环在读不到新的博客时结束
if not blog_list:
break
print("fetch: ", request_url)
for blog in blog_list:
# 获取标题
title = blog.select(".postTitle a")[0].string
print('--------------------------'+title+'--------------------------');
# 获取博客链接
blog_url = blog.select(".postTitle a")[0]["href"]
print(blog_url);
# 获取博客日期
date = blog.select(".dayTitle a")[0].get_text()
print(date)
# 获取博客简介
des = blog.select(".postCon > div")[0].get_text()
print(des)
print('-------------------------------------------------------------------------------------');
如上述代码所示,我们根据分析的规则循环翻页并且从每一页的HTML中抽取出了我们需要的博客信息,并打印出来,相关代码已提供注释,这里我们就不多说了。
编写Dockerfile
代码写完,按照惯例,我们仍然是使用Docker实现本地无SDK开发,因此编写Dockerfile如下所示:
# 使用官方镜像 FROM python:3.7-slim # 设置工作目录 WORKDIR /app # 复制当前目录 COPY . /app # 安装模块 RUN pip install --trusted-host pypi.python.org -r requirements.txt # Run app.py when the container launches CMD ["python", "app.py"]
注意,由于我们使用到了比如beautifulsoup等第三方库,因此我们需要安装相关模块。requirements.txt内容如下所示(注意换行):
html5lib
beautifulsoup4
requests
运行并查看抓取结果
构建完成后,我们运行起来结果如下所示:
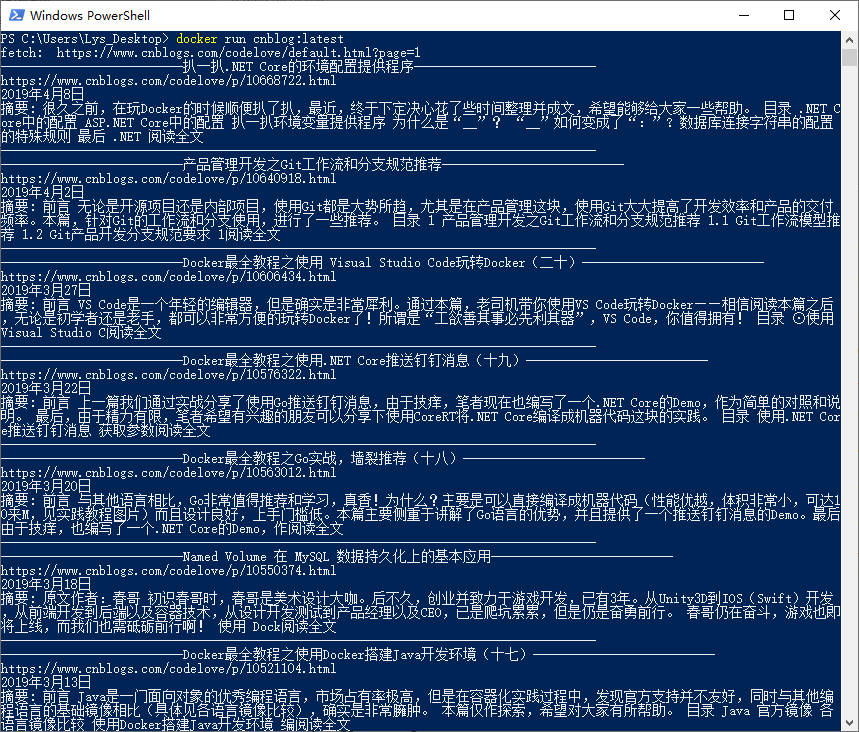
出处:http://www.cnblogs.com/codelove/
如果喜欢作者的文章,请关注【CodeSpirit-码灵】公众号以便第一时间获得最新内容。本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
静听鸟语花香,漫赏云卷云舒。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号