好用的parallel命令
原创:打码日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处。
简介
有时,我们需要处理一批数据,使用while循环是个不错的想法,但while循环中的命令是一个一个执行的,如果要批量处理的数据很多,执行时间就会很长,而parallel可以让命令并行执行,从而缩短命令执行时间。
下面,我们先用ncat来模拟一个处理数据的接口。
模拟接口
ncat -lk 8088 -c 'sleep 1;printf "HTTP/1.1 200 OK\r\nContent-Type: plain/text\r\nContent-Length: 3\r\n\r\nok\n"'
此接口直接睡眠1秒,然后返回一个ok,表示数据处理成功。
调用接口
curl -X POST http://localhost:8088/user/add -d '{"user_id": 1, "user_name":"u1"}'
测试数据
假设有10条数据,在data.txt中,如下:
1 u1
2 u2
3 u3
...
使用while循环处理
$ time while read -r -a line; do
curl -X POST http://localhost:8088/user/add -d '{"user_id": '${line[0]}', "user_name":"'${line[1]}'"}'
done < data.txt
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
real 0m10.276s
user 0m0.094s
sys 0m0.096s
使用while循环处理,其中time命令用来计时,real表示while命令的执行时间,可以看到,处理完10条数据花了约10秒,接下来我们使用parallel并发执行。
使用parallel并发执行
$ time cat data.txt | parallel -j10 -C '\s+' curl -s -X POST http://localhost:8088/user/add -d \'{\"user_id\": {1}, \"user_name\":\"{2}\"}\'
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
real 0m1.205s
user 0m0.203s
sys 0m0.060s
使用parallel命令并发执行curl,-j10表示最多10个并发进程,-C '\s+' 表示使用空白来拆分每行(注:\s+是表示空白的正则表达式),这样就可以使用{1}表示第1列,{2}表示第2列了,如我们所预期的,10条数据使用10个并发,处理完约1秒。
有用的--tag选项
上例的接口很简单,直接返回ok,但在有大量数据需要处理时,有可能出现部分数据处理失败,像上面的执行结果中,就很难知道是哪些数据处理失败了,还好parallel提供了--tag选项,可以将处理的数据与执行结果都打印出来,如下:
$ cat data.txt | parallel -j10 -C '\s+' --tag curl -s -X POST http://localhost:8088/user/add -d \'{\"user_id\": {1}, \"user_name\":\"{2}\"}\'
1 u1 ok
2 u2 ok
4 u4 ok
3 u3 ok
5 u5 ok
6 u6 ok
7 u7 ok
8 u8 ok
9 u9 ok
10 u10 ok
这样,什么数据执行对应什么结果,就一目了然了。
查看进度
如果有大量数据需要处理,处理时能直观的看到一个进度就再好不过了,parallel提供了3个查看进度的选项,--bar、--progress和--eta,一般使用--bar、--progress即可。
其中--bar适合待处理数据量确定的场景,因为parallel需要读取所有数据后才能根据数据总量计算进度条。
而--progress适合待处理数据量未知的场景,只能看到已经处理了多少条数据,如下:
# 使用 --bar 显示进度条
cat data.txt | parallel -j10 -C '\s+' --tag --bar curl -s -X POST http://localhost:8088/user/add -d \'{\"user_id\": {1}, \"user_name\":\"{2}\"}\'
# 使用 --progress 显示处理条数
cat data.txt | parallel -j10 -C '\s+' --tag --progress curl -s -X POST http://localhost:8088/user/add -d \'{\"user_id\": {1}, \"user_name\":\"{2}\"}\'
--joblog与--resume-failed选项
相信当你使用脚本处理有一定数据量的数据时,一定会遇到数据偶尔处理失败的情况(由于网络不稳定),这时你需要将处理失败的数据再次找出来,然后再次处理,过程还是挺麻烦的。
好在parallel命令已经考虑到了这种场景,并提供了--joblog与--resume-failed选项,当有失败产生时,你只需要再次执行整个命令行即可。
# 模拟接口修改如下,使得接口有概率失败,成功返回true,失败返回fail
ncat -lk 8088 -c 'sleep 1;r=$(head /dev/urandom | tr -dc 0-9 | head -c 1);printf "HTTP/1.1 200 OK\r\nContent-Type: plain/text\r\nContent-Length: 5\r\n\r\n";[ $r -lt 5 ] && printf "true\n" || printf "fail\n"'
# parallel添加--joblog job.log --resume-failed参数,这次我们将处理脚本封装为一个函数,并用export -f使其生效,这样就可以在parallel中直接使用函数了
function deal_data(){
res=$(curl -s -X POST http://localhost:8088/user/add -d '{"user_id": '$1', "user_name":"'$2'"}')
echo "$res"
[[ "$res" == "true" ]] && return 0 || return 1
}
export -f deal_data
$ cat data.txt | parallel -j10 -C '\s+' --tag --joblog job.log --resume-failed deal_data
1 u1 true
2 u2 true
4 u4 true
5 u5 true
3 u3 fail
6 u6 true
8 u8 true
7 u7 true
9 u9 true
10 u10 fail
# 上面有2条数据处理失败,我们再次执行以上命令,如下,可以看到本次只执行了之前失败的2条数据,perfect!
$ cat data.txt | parallel -j10 -C '\s+' --tag --joblog job.log --resume-failed deal_data
3 u3 true
10 u10 true
--semaphore选项
parallel既然提供了并发,那么必然会遇到并发冲突问题,比如sed命令就不支持并发的修改同一文件,不过parallel已经提供了--semaphore选项来解决这个问题了。
如下,其中sem是parallel --semaphore的别名,与其是等价的。
function deal_data(){
res=$(curl -s -X POST http://localhost:8088/user/add -d '{"user_id": '$1', "user_name":"'$2'"}')
echo "$res"
[[ "$res" == "true" ]] && return 0 || return 1
}
export -f deal_data
$ grep -vnP 'ok$' data.txt |parallel -C ':|\s+' --tag 'deal_data {2} {3}; [[ $? -eq 0 ]] && sem -j1 sed -i \"{1} s/$/ ok/\" data.txt'
这里的逻辑是,每处理成功data.txt中的一条数据,就使用sed将data.txt中的那行数据末尾加一个ok,表示执行成功,然后在前面使用grep找不包含ok的数据,就达到了命令每次都处理未处理或处理失败数据的逻辑。而sem -j1保护了sed,避免sed命令并发执行。
与mysql结合使用
parallel还可以和mysql结合使用,将任务导入mysql中或是执行mysql中的任务,如下:
# 1.将任务数据导入到pardb库的paralleljobs表中,pardb库需要事先自行创建
cat data.txt |parallel --sqlmaster 'sql:mysql://user:pass@localhost:3306/pardb/paralleljobs'
# 2.执行paralleljobs表中待处理任务,Exitval=-1000为待处理任务
function deal_data(){
p=($*)
res=$(curl -s -X POST http://localhost:8088/user/add -d '{"user_id": '${p[0]}', "user_name":"'${p[1]}'"}')
echo "$res"
[[ "$res" == "true" ]] && return 0 || return 1
}
export -f deal_data
parallel --sqlworker 'sql:mysql://user:pass@localhost:3306/pardb/paralleljobs' --tag deal_data
处理csv数据
parallel命令还能很方便的处理csv文件数据,比如将data.txt改为data.csv,如下:
$ cat data.csv
user_id,user_name
1,u1
2,u2
3,u3
...
# 使用--header : 选项来读取csv的表头,然后就可以{user_id},{user_name}来占位命令参数了
$ cat data.csv | parallel --header : -C ',' --tag curl -s -X POST http://localhost:8088/user/add -d \'{\"user_id\": {user_id}, \"user_name\":\"{user_name}\"}\'
--pipe选项
有很多文本处理命令,并不从参数中获取数据,而是从标准输入中获取,比如paste,通过指定--pipe选项,能将数据传入到待执行命令的输入流中去。
# 比如我想把data.csv变成data.json,且每3条数据聚合成一个json数组,如下:
$ cat data.csv | parallel --header : -C ',' echo \'{\"user_id\": {user_id}, \"user_name\":\"{user_name}\"}\' | parallel -N3 --pipe paste -s -d, | sed -e 's/^/\[/' -e 's/$/]/'
[{"user_id": 7, "user_name":"u7"},{"user_id": 8, "user_name":"u8"},{"user_id": 9, "user_name":"u9"}]
[{"user_id": 1, "user_name":"u1"},{"user_id": 2, "user_name":"u2"},{"user_id": 3, "user_name":"u3"}]
[{"user_id": 4, "user_name":"u4"},{"user_id": 5, "user_name":"u5"},{"user_id": 6, "user_name":"u6"}]
[{"user_id": 10, "user_name":"u10"}]
第一个parallel将每条数据变成了{"user_id": 1, "user_name":"u1"}形式。
第二个parallel将每3个json传给paste的输入流,然后paste使用逗号将它们连接起来。
每三个sed给首尾加上[],即成为了需要的数据格式。
与tmux结合使用
parallel提供了--tmuxpane,使得可以实现在tmux的多个panel中执行命令,这非常适合用来观察一些监控命令的结果,比如查看每台主机的网络情况。
# 使用ping同时监控简书、百度、知乎的网络情况,注意,必须要加--delay选项
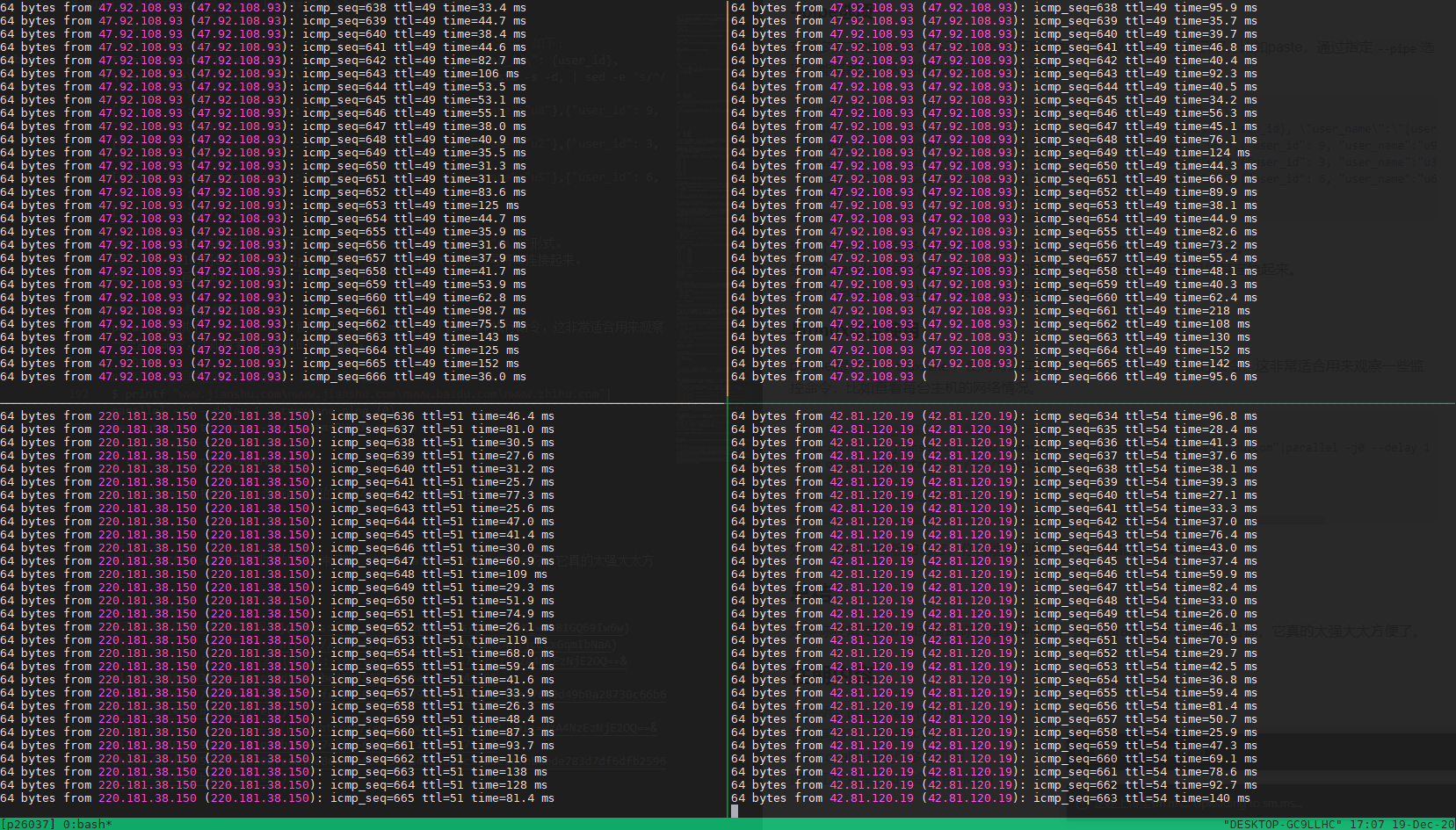
$ printf "www.jianshu.com\nwww.jianshu.com\nwww.baidu.com\nwww.zhihu.com"|parallel -j0 --delay 1 --tmuxpane ping {0}
See output with: tmux -S /tmp/tmsOHGXM attach
# 查看tmux面板
$ tmux -S /tmp/tmsOHGXM attach
如下,为tmux面板的内容,你将能直观的看到4台机器的ping实时结果。
总结
如果你经常使用shell来帮助你处理各种问题,我想parallel命令就非常适合你,它真的太强大太方便了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号