
mysql(二)索引学习

1.索引作用是什么?使用什么数据结构存储?
【作用】:加快数据检索
【数据结构】:B+树
mysql的innodb在进行数据读取的时候也是和页相关的,datapagesize,默认是16KB。
索引存储是k-v格式的,即索引-行数据,那么常见可以选择的数据结构有:hash表、二叉树、B树、B+树。
链表:查询时,时间复杂度比较高,效率低
hash表:需要很优良的hash算法避免数据散列带来的浪费空间和查询快慢不均匀,并且hash表是无序的,相当于全表扫描,但是由于hash是在内存中进行的,所以即使如此依旧很快,但是核心问题就是在内存中太消耗内存。
即:1.算法要求高;2,只能进行等值查询,不支持范围查询;3.当数据量很大时,比较费内存
二叉树、平衡二叉树、红黑树:都是二叉树,当数据量很大的时候,树的层级就会很深,查找的次数会很大。会影响效率
B树:B树相当于二叉树来说,每个节点可以有多个子树,这样就保证了层级较浅,查询效率提高,但是,由于索引数据存在磁盘,查询需要IO操作,IO操作相对内存来说是非常慢的,因此需要尽量减少IO操作次数,因此读取数据是按照磁盘块(文件系统读写数据的最小单位)读取,而Innodb中页(内存的最小存储单位。页的大小通常为磁盘块大小的 2^n 倍)的默认大小是16kb,由于B树的页中存储的是k-v,大大降低了页中存储的索引数,因此,增加了IO操作次数,降低了查询效率。另外,B树的数据分散在各个节点,要实现范围查找,排序查找,分组查找以及去重查找相对较复杂,也降低了速率。
B+树:B+树除底层页以外,页中只存k,这样单页中就能存储更多的索引值,减少了IO操作,从而加快了查询速率。
因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。
这样如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO。
B+树和B-树的主要区别如下:
- B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
- B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。
- 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束
- B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
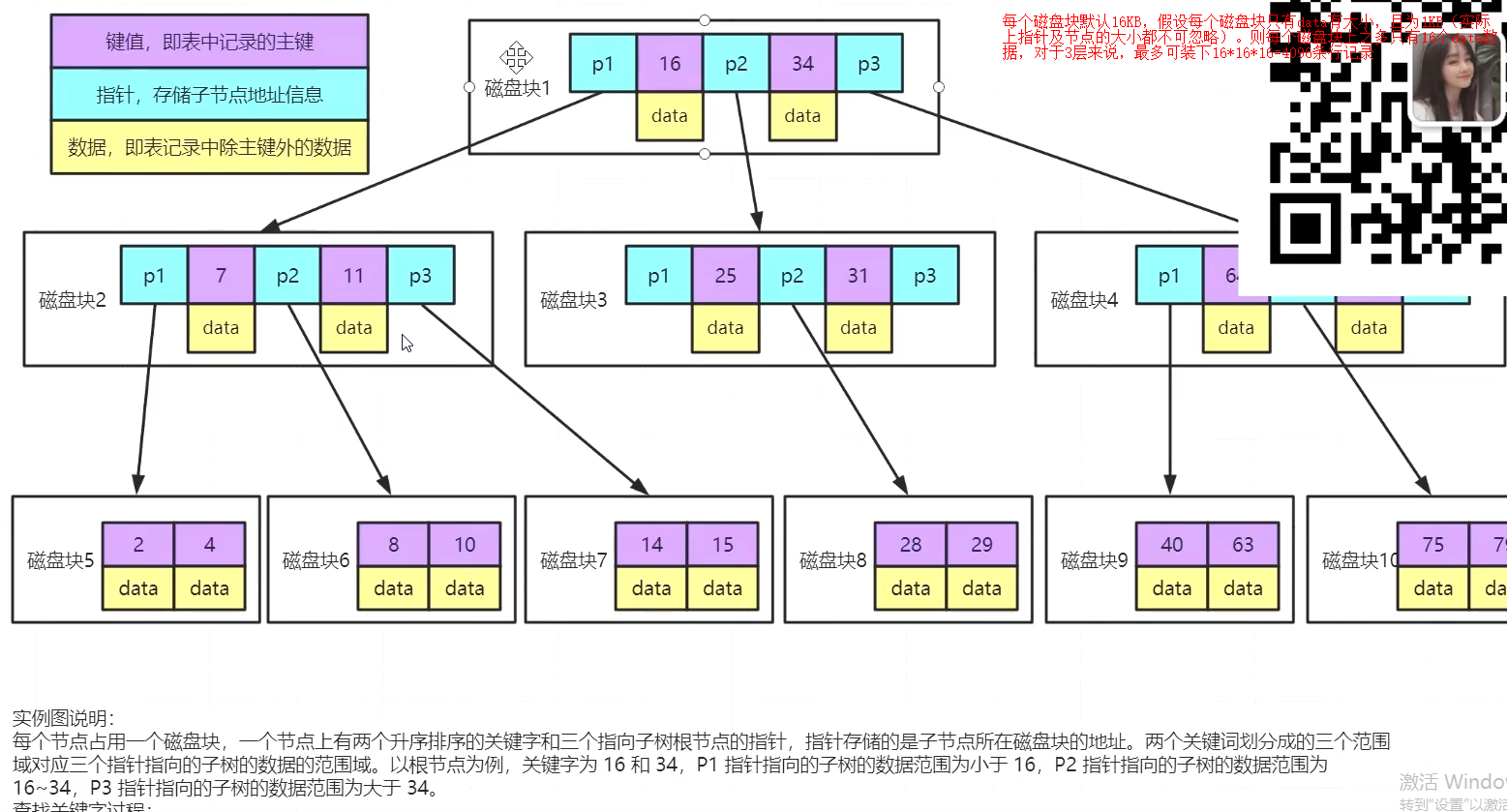
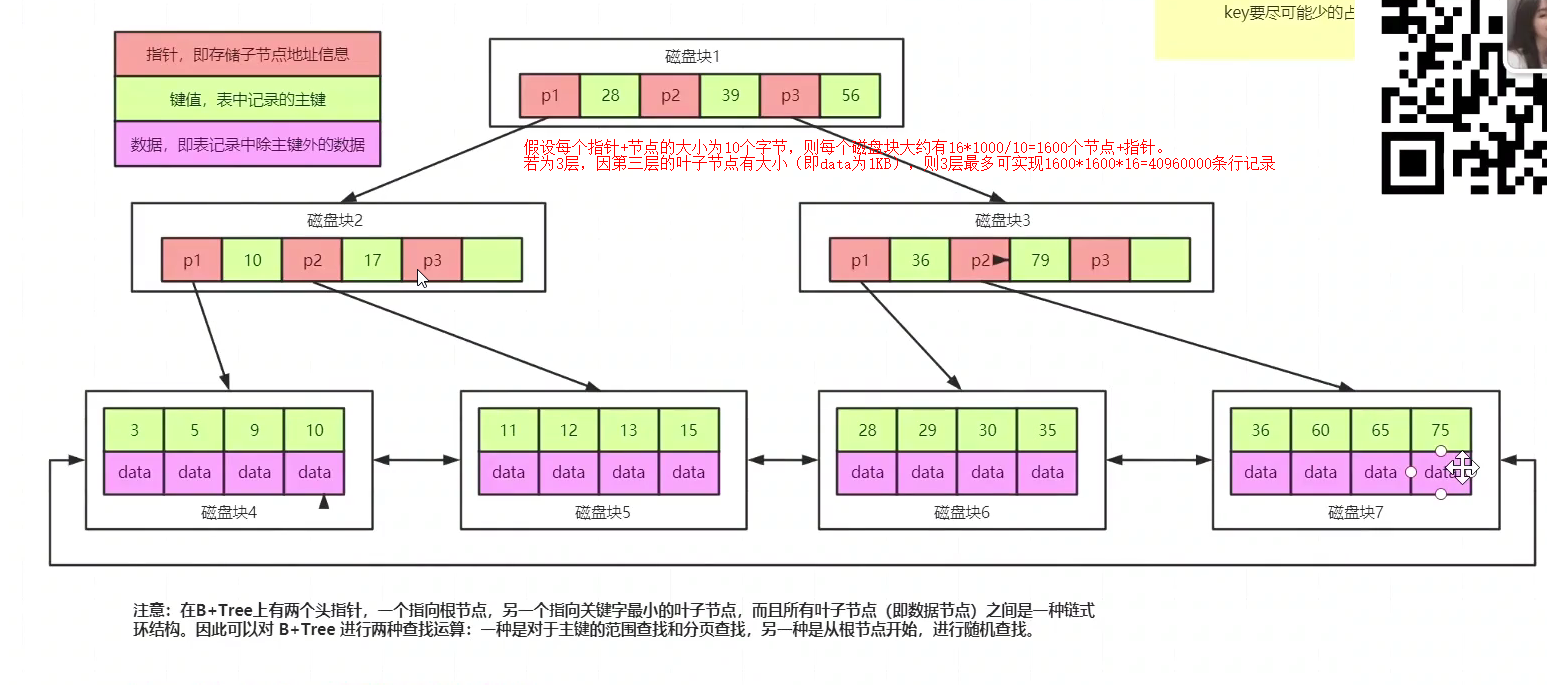
1.要达到几千万的记录,B+树需要几层?高度为2,大约可以存储一两千行条记录,3层一般千万级别。正常来说,3-4层够用
2.层数的大小和索引值的大小有关
3.选择索引的时候,使用int还是varchar? 目标是让索引key占用最少的空间。若key的长度小于4,则使用varchar,否则使用int类型
4.在mysql中,若ID作为索引列的值,ID是否要自增? ---要,索引自增可以减少分裂。如果不是自增的,那索引值是无序的,但是B+树底层节点是排序的,因此当需要插入的页满了,则需要分裂为两个页,上层也需要做出相应变化。而如果是自增的,那只需要往后追加,不会影响前面的数据。即索引维护,页分裂,页合并。
重要补充:https://mp.weixin.qq.com/s/opbgvTX_GDytR-MS3-6yEA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号