Spring Ioc源码分析系列--@Autowired注解的实现原理
Spring Ioc源码分析系列--@Autowired注解的实现原理
前言
前面系列文章分析了一把Spring Ioc的源码,是不是云里雾里,感觉并没有跟实际开发搭上半毛钱关系?看了一遍下来,对我的提升在哪?意义何在?如果没点收获,那浪费时间来看这个作甚,玩玩游戏不香?
这段玩笑话可不是真的玩笑,提升需要自己去把握,意义也需要自己去挖掘。纸上得来终觉浅,绝知此事要躬行。最好是跟着代码调试一遍才会留下自己的印象,这过程收获的会比你想象中的要多。看山是山,看水是水。看山不是山,看水不是水。看山还是山,看水还是水。
话不多说,既然这里是讲解@Autowired的原理,那么这篇文章就会暂时先摒弃本系列文章开始所使用的xml配置方式,投入到注解驱动的怀抱。这两者对比而言,注解模式已经开始走向了自动装配,后续的Spring Boot更是彻底走上了自动装配这条路。
在正式分析之前,先来简单说一下传统的装配和自动装配的区别。
- 传统装配:配置量大,配置复杂,需要手动维护的地方多。
- 自动装配:只需要简单配置,不需要维护大量的配置,Spring会根据你现有的要求提前给你配置好需要的东西,省略了很多手动的维护。
那废话少说,下面搞个例子分析一下吧。
代码样例
例子很简单,建两个Service,利用@Autowired给其中一个注入,启动容器,查看是否能够成功注入。
先整个UserService,这个类只有一个sayHi()方法。
/**
* @author Codegitz
* @date 2022/6/1
**/
@Component
public class UserService {
public void sayHi(String name){
System.out.println("hi " + name);
}
}
再新建个ManagerService,前面的UserService会注入到这里,然后greet()方法会调用UserService#sayHi()方法。
/**
* @author Codegitz
* @date 2022/6/1
**/
@Component
public class ManagerService {
@Autowired
private UserService userService;
public void greet(String name){
userService.sayHi(name);
}
}
万事俱备,只欠东风,搞个启动类AutowiredApplication,看是否能够够实现注入。
/**
* @author Codegitz
* @date 2022/6/1 10:19
**/
public class AutowiredApplication {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext("io.codegitz.inject");
ManagerService managerService = (ManagerService) applicationContext.getBean("managerService");
managerService.greet("codegitz");
}
}
启动之后可以看到注入成功。
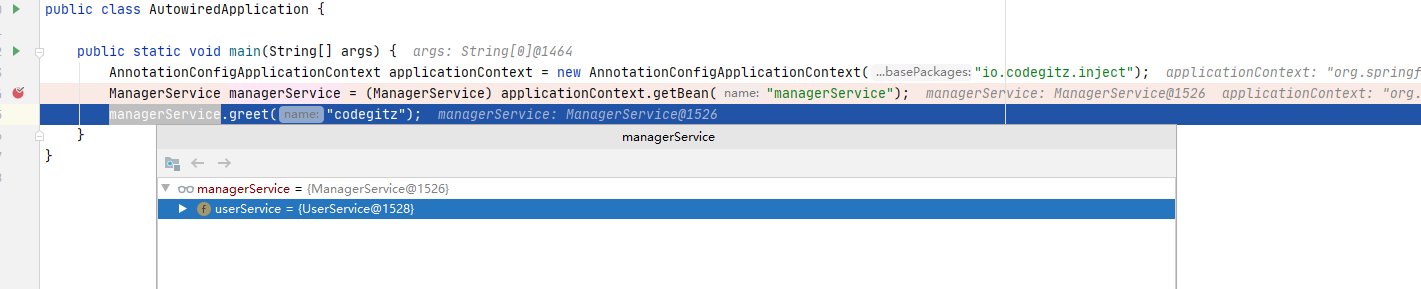
运行结束查看输出,符合逾期。

上面就是一个简单的注入例子,日常的业务开发是不是经常这样写,终于看到点跟业务相关的逻辑,那接下来就分析一下它的原理。
源码分析
这篇文章主要是展示一个过程,所以debug展示的图片较多
这里就不遮遮掩掩了,实现@Autowired注解功能的是一个后置处理器AutowiredAnnotationBeanPostProcessor,这个处理器的postProcessMergedBeanDefinition()方法会对标注了@Autowired进行预处理,然后调用postProcessProperties()进行注入,这里分两步,预处理和真正注入,这个处理器是在什么时候执行的呢?可以参考文章 Spring Ioc源码分析系列--Bean实例化过程(二) 里面MergedBeanDefinitionPostProcessor的应用那一节。
预处理
我们先看预处理,直接定位到这里的实现代码位置,在AbstractAutowireCapableBeanFactory#applyMergedBeanDefinitionPostProcessors()方法里。调试的时候加上条件,这样一步到位节省很多时间。
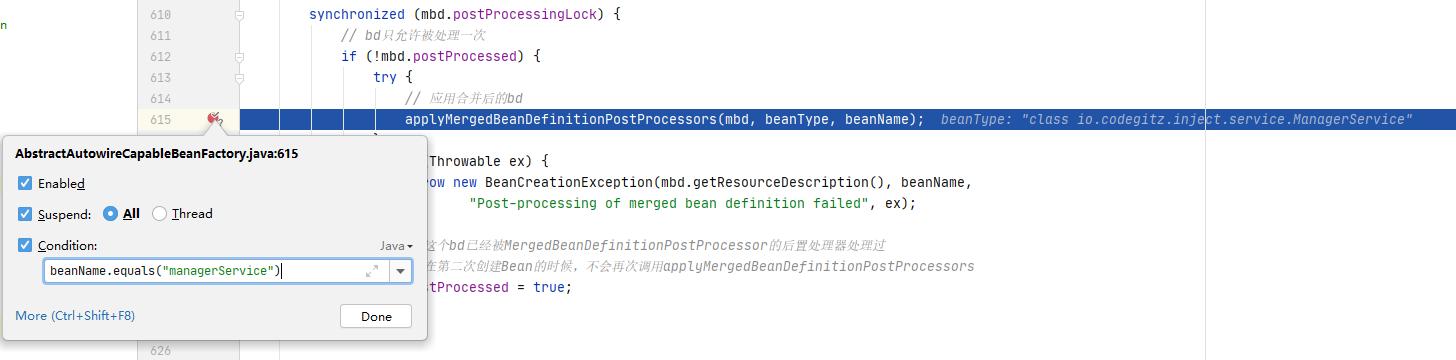
跟进方法,这里也一样,加上条件bdp instanceof AutowiredAnnotationBeanPostProcessor,聚焦目标一步到位。

进入postProcessMergedBeanDefinition()方法,显然这里的实现是AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition()里。预处理方法postProcessMergedBeanDefinition()会比真正的注入方法postProcessProperties()先执行,因此调用postProcessProperties()时都是直接拿缓存。

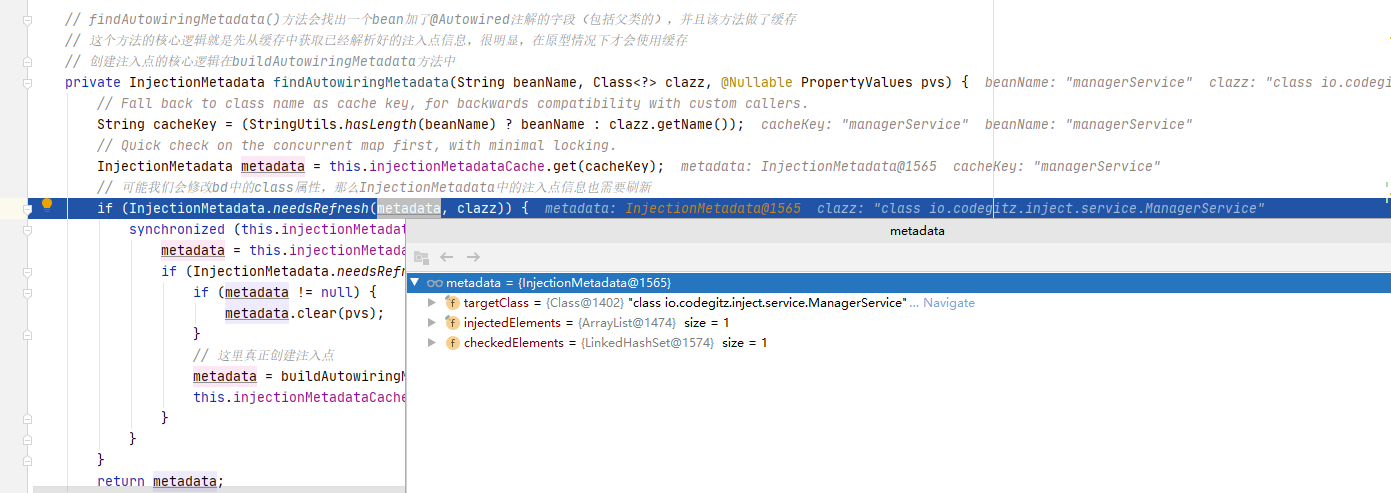
可以看到这里会先调用findAutowiringMetadata()方法,findAutowiringMetadata()方法会找出一个bean加了@Autowired注解的字段(包括父类的),并且该方法做了缓存,这个方法的核心逻辑就是先从缓存中获取已经解析好的注入点信息,很明显,在原型情况下才会使用缓存,接下来创建注入点的核心逻辑在buildAutowiringMetadata()方法中。
跟进findAutowiringMetadata()方法,可以看到这里第一次进来是没有缓存的,这里会采用一个双重校验的方式去解决线程安全问题,接下来就是真正创建注入点。
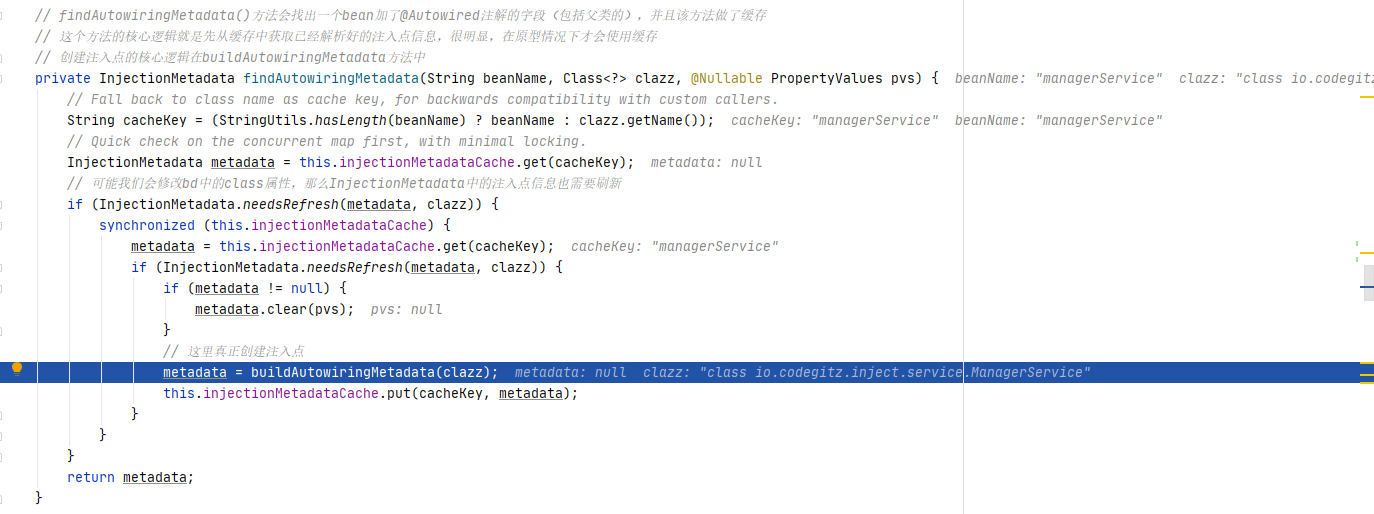
跟进buildAutowiringMetadata()方法,这个方法将@Autowired注解标注的方法以及字段封装成InjectionMetadata 在后续阶段会调用InjectionMetadata#inject()方法进行注入。
先贴一下这个方法的代码,可以看到这里会分别去处理属性和方法上面的注解,我们这里只是使用了属性的注入,因此我们关注的是ReflectionUtils#doWithLocalFields()这一段。
// 我们应用中使用@Autowired注解标注在字段上或者setter方法能够完成属性注入
// 就是因为这个方法将@Autowired注解标注的方法以及字段封装成InjectionMetadata
// 在后续阶段会调用InjectionMetadata的inject方法进行注入
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
if (!AnnotationUtils.isCandidateClass(clazz, this.autowiredAnnotationTypes)) {
return InjectionMetadata.EMPTY;
}
List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();
// 处理所有的被@AutoWired/@Value注解标注的字段
ReflectionUtils.doWithLocalFields(targetClass, field -> {
MergedAnnotation<?> ann = findAutowiredAnnotation(field);
if (ann != null) {
// 静态字段会直接跳过
if (Modifier.isStatic(field.getModifiers())) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation is not supported on static fields: " + field);
}
return;
}
// 得到@AutoWired注解中的required属性
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
});
// 处理所有的被@AutoWired注解标注的方法,相对于字段而言,这里需要对桥接方法进行特殊处理
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
// 只处理一种特殊的桥接场景,其余的桥接方法都会被忽略
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
MergedAnnotation<?> ann = findAutowiredAnnotation(bridgedMethod);
// 处理方法时需要注意,当父类中的方法被子类重写时,如果子父类中的方法都加了@Autowired
// 那么此时父类方法不能被处理,即不能被封装成一个AutowiredMethodElement
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
if (Modifier.isStatic(method.getModifiers())) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation is not supported on static methods: " + method);
}
return;
}
if (method.getParameterCount() == 0) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation should only be used on methods with parameters: " +
method);
}
}
boolean required = determineRequiredStatus(ann);
// PropertyDescriptor: 属性描述符
// 就是通过解析getter/setter方法,例如void getA()会解析得到一个属性名称为a
// readMethod为getA的PropertyDescriptor,
// 这里之所以来这么一次查找是因为当XML中对这个属性进行了配置后,
// 那么就不会进行自动注入了,XML中显示指定的属性优先级高于注解
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);
// 方法的参数会被自动注入,这里不限于setter方法
currElements.add(new AutowiredMethodElement(method, required, pd));
}
});
// 会处理父类中字段上及方法上的@AutoWired注解,并且父类的优先级比子类高
elements.addAll(0, currElements);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
return InjectionMetadata.forElements(elements, clazz);
}
跟进ReflectionUtils#doWithLocalFields()方法,可以看到这里会获取类上所有声明的注释,然后逐个放入到FieldCallback进行处理,可以看到这里已经获取到了我们类上的userService属性,跟进fc.doWith(field)方法。
 这里回到了之前的这一段
这里回到了之前的这一段lambada表达式,首先会调用findAutowiredAnnotation()查找是否存在该注解,有则返回该注解(包括注解上的属性),否则返回null。
跟进findAutowiredAnnotation()方法,这里会找到并且返回该注解。至于怎么找到该注解的,具体的实现都在annotations.get(type)方法里,大概的思路就是获取上面的注解,然后去扫描一遍,寻找符合类型要求的注解并且返回。

获取到注解后返回,回到那一段lambda表达式里,会继续调用determineRequiredStatus()确定属性required的值,显然这里会获取到true,随后会将当前属性field和是否必须required封装成AutowiredFieldElement对象加入到当前元素currElements集合中。这个集合最后会被加入到所有elements集合中,最后封装成InjectionMetadata对象返回,然后放入到缓存injectionMetadataCache里,后续真正的属性注入就会从缓存中获取。

到这里其实已经完成了注解属性的获取,
随后回AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition()方法里,随后会调用metadata.checkConfigMembers(beanDefinition)排除掉被外部管理的注入点。

进入该方法可以看到,这里就是判断一下是不是被外部管理,没有就注册一下,然后加入checkedElements集合里。
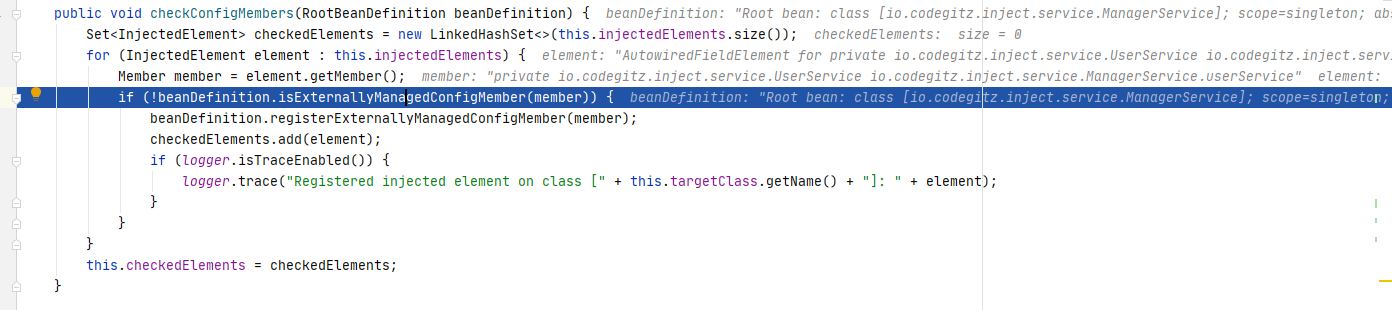
至此,预处理已经完成了。继续往下走,准备进行真正的注入操作。
执行注入
上面的预处理已经完成,预处理找出了需要执行自动注入的字段,接下来就是准备自动注入了。
获取注入点
继续回到AbstractAutowireCapableBeanFactory#doCreateBean()方法里,真正注入的逻辑在populateBean()方法里,进入该方法。略过前面部分逻辑,如果需要分析略过的逻辑,可以看文章 Spring Ioc源码分析系列--Bean实例化过程(二) ,这里不再赘述。
可以看到,这里会判断是否存在InstantiationAwareBeanPostProcessor类型的后置处理器,如果有,则执行其postProcessProperties()方法。我们关注的是AutowiredAnnotationBeanPostProcessor后置处理器的实现,直接进入到里面的逻辑。
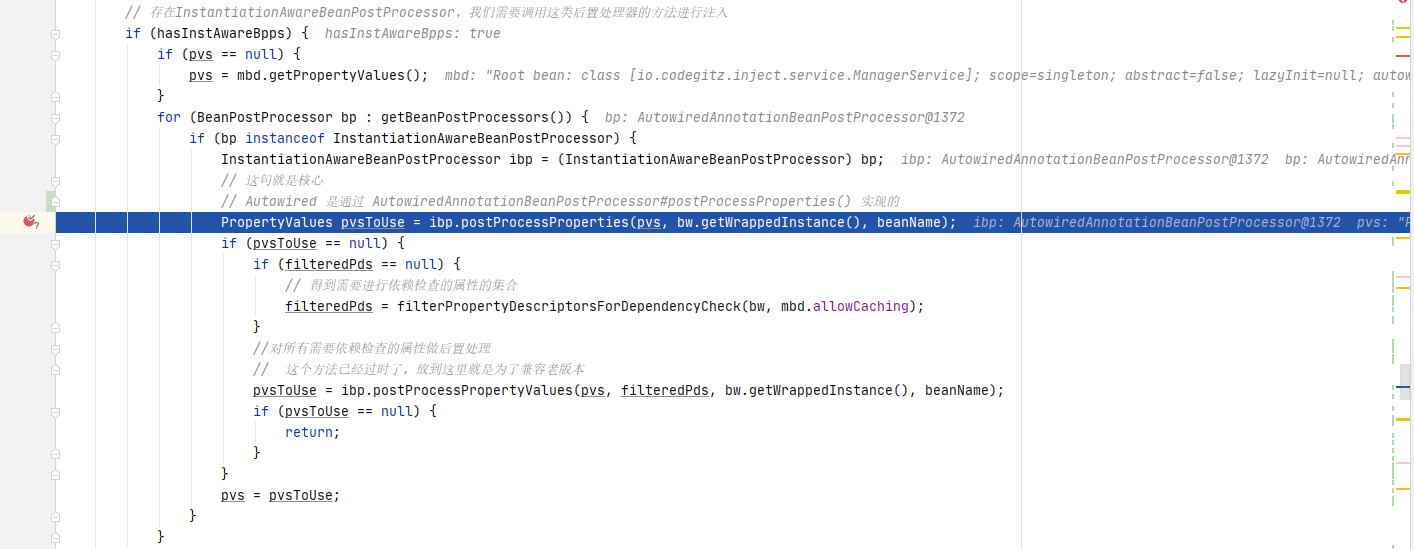
进入AutowiredAnnotationBeanPostProcessor#postProcessProperties()实现,这里也是调用findAutowiringMetadata()方法获取需要注入的属性,由于经过了之前的预处理,这里会直接从缓存中获取。
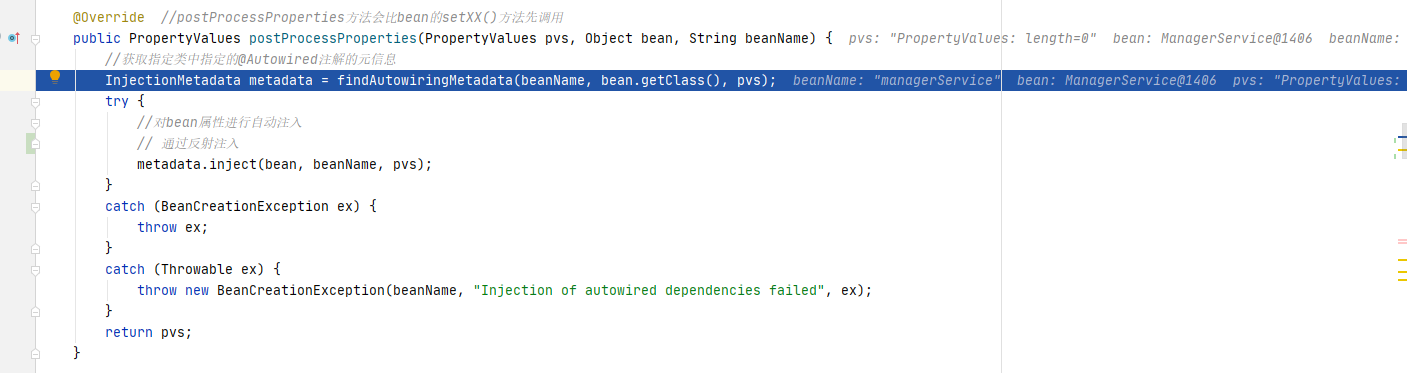
这里缓存是命中,直接返回。
接下来调用metadata.inject(bean, beanName, pvs)执行属性注入。
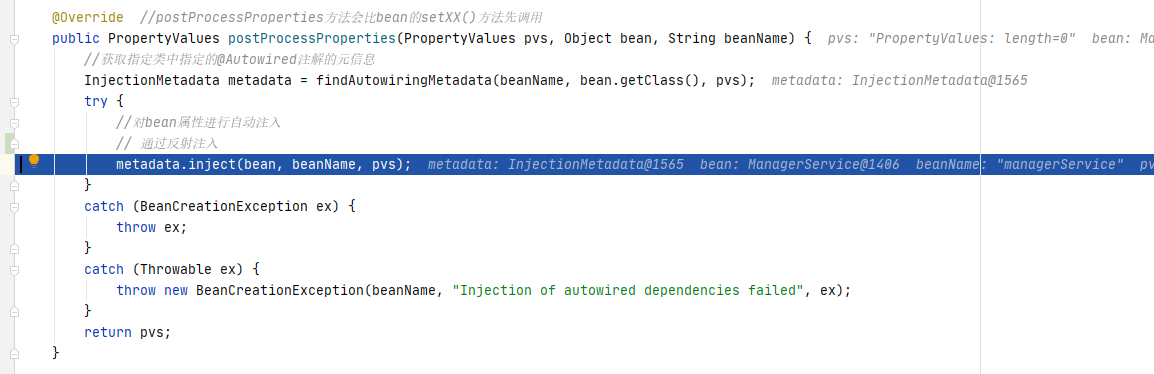
进入inject()方法,可以看到这里就会获取checkedElements里面的注入点,然后进行逐个执行注入。
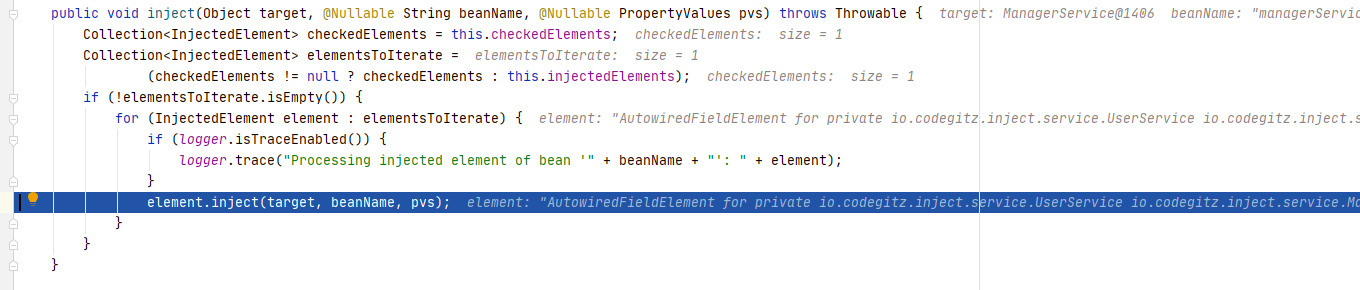
解析注入点依赖
代码实现在AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement#inject()里,这里最关键的就是这一句beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter)了,这里会去解析依赖,获取我们需要的对象,随后进行注入。

beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter)这个方法十分关键,这个方法会处理依赖之间的逻辑,例如处理优先级,处理Map、数组、Collection等类型属性。
下面来重点分析一下这段代码,实现是在DefaultListableBeanFactory#resolveDependency()方法里,先贴一下代码。可以看到这里解析的依赖分几种类型:
- Optional
类型 - ObjectFactory
、ObjectProvider 类型 - javax.inject.Provider
类型 - @Lazy类型
- 正常Bean类型
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
// descriptor代表当前需要注入的那个字段,或者方法的参数,也就是注入点
// ParameterNameDiscovery用于解析方法参数名称
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
// 1. Optional<T>
if (Optional.class == descriptor.getDependencyType()) {
return createOptionalDependency(descriptor, requestingBeanName);
}
// 2. ObjectFactory<T>、ObjectProvider<T>
else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
//ObjectFactory和ObjectProvider类的特殊注入处理
return new DependencyObjectProvider(descriptor, requestingBeanName);
}
// 3. javax.inject.Provider<T>
else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);
}
else {
// 4. @Lazy
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
//通用处理逻辑
// 5. 正常情况
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
我们这里的注入类型是正常的Bean,所以这里会走到最后的doResolveDependency()方法里,跟进方法。
可以看到这个方法会先进行占位符的处理,然后调用resolveMultipleBeans()方法处理数组或者集合类型的依赖。如果不是,则调用findAutowireCandidates()寻找合适的依赖,如果找到多个,则需要调用determineAutowireCandidate()确定哪个依赖最合适,包括处理优先级、类型和名称等,处理完成后返回待注入的依赖。
对于我们这里而言,重点在于findAutowireCandidates()方法。
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
// 依赖的具体类型
Class<?> type = descriptor.getDependencyType();
//用于支持spring中新增的注解@Value
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
// 解析@Value中的占位符
String strVal = resolveEmbeddedValue((String) value);
// 获取到对应的bd
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
// 处理EL表达式
value = evaluateBeanDefinitionString(strVal, bd);
}
// 通过解析el表达式可能还需要进行类型转换
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
// 如果需要的话进行类型转换
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
// 对map,collection,数组类型的依赖进行处理
// 最终会根据集合中的元素类型,调用findAutowireCandidates方法
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
/**
* 根据属性类型找到beanFactory中所有类型匹配的bean
* 返回值的构成为:key=匹配的beanName,value=beanName对应的实例化的bean(通过getBean(beanName)返回
*/
// 根据指定类型可能会找到多个bean
// 这里返回的既有可能是对象,也有可能是对象的类型
// 这是因为到这里还不能明确的确定当前bean到底依赖的是哪一个bean
// 所以如果只会返回这个依赖的类型以及对应名称,最后还需要调用getBean(beanName)
// 去创建这个Bean
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
// 一个都没找到,直接抛出异常
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
//如果required属性为true,但是找到的列表属性却为空,抛异常
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
// 通过类型找到了多个
if (matchingBeans.size() > 1) {
// 根据是否是主Bean
// 是否是最高优先级的Bean
// 是否是名称匹配的Bean
// 来确定具体的需要注入的Bean的名称
// 到这里可以知道,Spring在查找依赖的时候遵循先类型再名称的原则(没有@Qualifier注解情况下)
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
// 无法推断出具体的名称
// 如果依赖是必须的,直接抛出异常
// 如果依赖不是必须的,但是这个依赖类型不是集合或者数组,那么也抛出异常
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
// 依赖不是必须的,但是依赖类型是集合或者数组,那么返回一个null
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
// 在可选的 CollectionMap 的情况下,
// 默默地忽略非唯一的情况:可能它是多个常规 bean 的空集合(特别是在 4.3 之前,当我们甚至不寻找集合 bean 时)。
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
// 直接找到了一个对应的Bean
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 前面已经说过了,这里可能返回的是Bean的类型,所以需要进一步调用getBean
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
// 做一些检查,如果依赖是必须的,查找出来的依赖是一个null,那么报错
// 查询处理的依赖类型不符合,也报错
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
// 更新当前的注入点为前一个
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
跟进findAutowireCandidates()方法代码,注意这个方法返回的只是候选依赖的bean名称和class类型,找到名称后还需要进行获取bean对象的操作。
/**
* Find bean instances that match the required type.
* Called during autowiring for the specified bean.
*
* 查找与所需类型匹配的 bean 实例。在指定 bean 的自动装配期间调用。
*
* @param beanName the name of the bean that is about to be wired
* @param requiredType the actual type of bean to look for
* (may be an array component type or collection element type)
* @param descriptor the descriptor of the dependency to resolve
* @return a Map of candidate names and candidate instances that match
* the required type (never {@code null})
* @throws BeansException in case of errors
* @see #autowireByType
* @see #autowireConstructor
*/
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
// 简单来说,这里就是到容器中查询requiredType类型的所有bean的名称的集合
// 这里会根据descriptor.isEager()来决定是否要匹配factoryBean类型的Bean
// 如果isEager()为true,那么会匹配factoryBean,反之,不会
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = new LinkedHashMap<>(candidateNames.length);
// 第一步会到resolvableDependencies这个集合中查询是否已经存在了解析好的依赖
// 像我们之所以能够直接在Bean中注入applicationContext对象
// 就是因为Spring之前就将这个对象放入了resolvableDependencies集合中
for (Map.Entry<Class<?>, Object> classObjectEntry : this.resolvableDependencies.entrySet()) {
Class<?> autowiringType = classObjectEntry.getKey();
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
// 如果resolvableDependencies放入的是一个ObjectFactory类型的依赖
// 那么在这里会生成一个代理对象
// 例如,我们可以在controller中直接注入request对象
// 就是因为,容器启动时就在resolvableDependencies放入了一个键值对
// 其中key为:Request.class,value为:ObjectFactory
// 在实际注入时放入的是一个代理对象
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
// 这里放入的key不是Bean的名称
// value是实际依赖的对象
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
// 接下来开始对之前查找出来的类型匹配的所有BeanName进行处理
for (String candidate : candidateNames) {
// 不是自引用,什么是自引用?
// 1.候选的Bean的名称跟需要进行注入的Bean名称相同,意味着,自己注入自己
// 2.或者候选的Bean对应的factoryBean的名称跟需要注入的Bean名称相同,
// 也就是说A依赖了B但是B的创建又需要依赖A
// 要符合注入的条件
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
// 调用addCandidateEntry,加入到返回集合中,后文有对这个方法的分析
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// fallback还是失败
if (result.isEmpty()) {
boolean multiple = indicatesMultipleBeans(requiredType);
// Consider fallback matches if the first pass failed to find anything...
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor) &&
(!multiple || getAutowireCandidateResolver().hasQualifier(descriptor))) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 排除自引用的情况下,没有找到一个合适的依赖
if (result.isEmpty() && !multiple) {
// Consider self references as a final pass...
// but in the case of a dependency collection, not the very same bean itself.
// 1.先走fallback逻辑,Spring提供的一个扩展吧,感觉没什么卵用
// 默认情况下fallback的依赖描述符就是自身
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}
到这里已经找到了bean名称,需要开始获取对象。

跟进descriptor.resolveCandidate(autowiredBeanName, type, this)方法查看,真是资本家看了都落泪,这里又开始了一个getBean()操作。这里又会进行一套操作,详细可见之前的文章Spring Ioc源码分析系列--Bean实例化过程(一),这里不再赘述。

所以上一步完成后,我们算是得到了一个可用的依赖,后续还会对依赖进行一个校验,校验通过就返回,然后就可以执行真正的反射注入了。
解析依赖这里有非常多的细节需要处理,我这里就不罗里吧嗦全部说清楚,感觉也说不清楚,这里就抓住一个脉络,注入的是一个简单对象的依赖,其他的细节不进行过分深究,有兴趣可以自行研究一下。
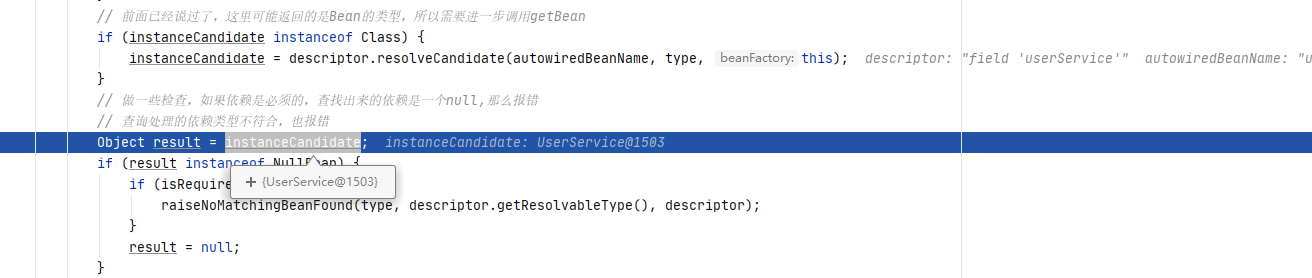
反射注入依赖
回到AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement#inject()方法里,可以看到注入的就是UserService@1503。至此,注入完成。

再进去就是反射的代码,这里也不再深入了。
@CallerSensitive
public void set(Object obj, Object value)
throws IllegalArgumentException, IllegalAccessException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
getFieldAccessor(obj).set(obj, value);
}
总结
这篇文章本来想简单写一下,但是发现这个简单不起来,都涉及到了很多,尽管已经简化着来写,但是写着写着也不短了。
回顾一下本文的思路,首先是通过一个例子,构造了一个业务场景经常使用的代码片段。虽然一针见血直接对原理直接分析,就不过多兜兜转转了。通过后面的源码分析得知,AutowiredAnnotationBeanPostProcessor会先去寻找注入点,然后去解析注入点需要的依赖,最后通过反射进行注入。原理就是这么简单,只不过实现起来比较复杂。
既然看到了这里,那么我留下一个问题,都知道是AutowiredAnnotationBeanPostProcessor完成了这些处理,但是你有没有留意到AutowiredAnnotationBeanPostProcessor是在哪里注册进了容器里以及是在哪里进行了初始化呢?前面的文章有答案,可以回想一下。
个人水平有限,如有错误,还请指出。
如果有人看到这里,那在这里老话重提。与君共勉,路漫漫其修远兮,吾将上下而求索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号