Linux 0.11 进程0、1、2
本博客研究重点主要放在进程0、1、2的创建和fork、execv等系统调用,因此会省去很多内部细节,只在代码上加上必要注释,这对我们理解重点没有影响。文章全部参考《Linux内核设计的艺术(第二版)》
进程0初始化
进程0是Linux操作系统中运行的第一个进程,也是Linux操作系统父子进程创建机制的第一个父进程。Linux初始化主要包含以下三方面:
- 系统初始化进程0。进程管理结构task_struct的母本(init_task = {INIT_TASK})已经在代码设计阶段事先准备好了。之后要对进程0的task_struct中的LDT、TSS与GDT挂接,并对GDT、task[64]以及与进程调度有关的寄存器进行初始化
- 设置时钟中断,支持多进程轮转。
- 进程0要具备处理系统调用的能力,通过set_system_gate将system_call与IDT相挂接。
这三点的实现都是在sched_init()函数中实现的,具体代码如下:
//代码路径:include/linux/head.h
typedef struct desc_struct {
unsigned long a,b;
} desc_table[256];
//代码路径:kernel/sched.c
#define LATCH (1193180/HZ)
union task_union {
struct task_struct task;
char stack[PAGE_SIZE];
};
static union task_union init_task = {INIT_TASK,};
struct task_struct *current = &(init_task.task);
struct task_struct *last_task_used_math = NULL;
//初始化进程槽task[NR_TASKS]的第一项为进程0,即task[0]为进程0占用
struct task_struct * task[NR_TASKS] = {&(init_task.task), };
void sched_init(void)
{
int i;
struct desc_struct * p;
if (sizeof(struct sigaction) != 16)
panic("Struct sigaction MUST be 16 bytes");
set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
p = gdt+2+FIRST_TSS_ENTRY;
for(i=1;i<NR_TASKS;i++) {
task[i] = NULL;
p->a=p->b=0;
p++;
p->a=p->b=0;
p++;
}
/* Clear NT, so that we won't have troubles with that later on */
__asm__("pushfl ; andl $0xffffbfff,(%esp) ; popfl");
ltr(0);
lldt(0);
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
outb(inb_p(0x21)&~0x01,0x21);
set_system_gate(0x80,&system_call);
}
//代码路径:include/linux/sched.h
struct tss_struct {
long back_link; /* 16 high bits zero */
long esp0;
long ss0; /* 16 high bits zero */
long esp1;
long ss1; /* 16 high bits zero */
long esp2;
long ss2; /* 16 high bits zero */
long cr3;
long eip;
long eflags;
long eax,ecx,edx,ebx;
long esp;
long ebp;
long esi;
long edi;
long es; /* 16 high bits zero */
long cs; /* 16 high bits zero */
long ss; /* 16 high bits zero */
long ds; /* 16 high bits zero */
long fs; /* 16 high bits zero */
long gs; /* 16 high bits zero */
long ldt; /* 16 high bits zero */
long trace_bitmap; /* bits: trace 0, bitmap 16-31 */
struct i387_struct i387;
};
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};
/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x9ffff (=640kB)
*/
#define INIT_TASK \
/* state etc */ { 0,15,15, \
/* signals */ 0,{{},},0, \
/* ec,brk... */ 0,0,0,0,0,0, \
/* pid etc.. */ 0,-1,0,0,0, \
/* uid etc */ 0,0,0,0,0,0, \
/* alarm */ 0,0,0,0,0,0, \
/* math */ 0, \
/* fs info */ -1,0022,NULL,NULL,NULL,0, \
/* filp */ {NULL,}, \
{ \
{0,0}, \
/* ldt */ {0x9f,0xc0fa00}, \
{0x9f,0xc0f200}, \
}, \
/*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\
0,0,0,0,0,0,0,0, \
0,0,0x17,0x17,0x17,0x17,0x17,0x17, \
_LDT(0),0x80000000, \
{} \
}, \
}
extern struct task_struct *task[NR_TASKS];
extern struct task_struct *last_task_used_math;
extern struct task_struct *current;
/*
* Entry into gdt where to find first TSS. 0-nul, 1-cs, 2-ds, 3-syscall
* 4-TSS0, 5-LDT0, 6-TSS1 etc ...
*/
#define FIRST_TSS_ENTRY 4
#define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY+1)
#define _TSS(n) ((((unsigned long) n)<<4)+(FIRST_TSS_ENTRY<<3))
#define _LDT(n) ((((unsigned long) n)<<4)+(FIRST_LDT_ENTRY<<3))
#define ltr(n) __asm__("ltr %%ax"::"a" (_TSS(n)))
#define lldt(n) __asm__("lldt %%ax"::"a" (_LDT(n)))
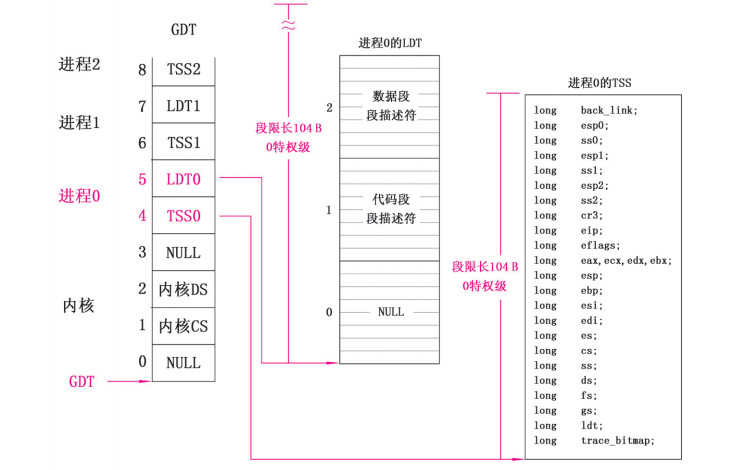
设置GDT中对应进程0的TSS、LDT描述符
#define FIRST_TSS_ENTRY 4
#define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY+1)
set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
设置GDT中和进程0相关的TSS和LDT描述符,进程0的tss内容和ldt内容均放在自己的task_struct中,因此向set_xxx_desc传入描述符对应的偏移量和地址即可进行初始化。
p = gdt+2+FIRST_TSS_ENTRY;
for(i=1;i<NR_TASKS;i++) {
task[i] = NULL; //进程i的指针为null
p->a=p->b=0; //进程i的tss描述符
p++;
p->a=p->b=0; //进程i的ldt描述符
p++;
}
之后对gdt中的其他内容和task数组的其他内容都清零。
#define FIRST_TSS_ENTRY 4
#define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY+1)
#define _TSS(n) ((((unsigned long) n)<<4)+(FIRST_TSS_ENTRY<<3))
#define _LDT(n) ((((unsigned long) n)<<4)+(FIRST_LDT_ENTRY<<3))
#define ltr(n) __asm__("ltr %%ax"::"a" (_TSS(n)))
#define lldt(n) __asm__("lldt %%ax"::"a" (_LDT(n)))
ltr(0);
lldt(0);
设置tr寄存器和ldt寄存器,指向进程0的tss描述符和ldt描述符。
设置时钟中断
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
outb(inb_p(0x21)&~0x01,0x21); //打开时钟中断
时钟中断处理程序timer_interrupt的代码进程调度时再进行介绍,先略过。
设置系统调用总入口
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr) //陷阱门
set_system_gate(0x80,&system_call);
将系统调用处理函数system_call与int0x80中断描述符表挂接。system_call是整个操作系统中系统调用软中断的总入口。所有用户程序使用系统调用,产生int 0x80软中断后,操作系统都是通过这个总入口找到具体的系统调用函数。
进程0由0特权级反转到3特权级,成为真正的进程
Linux操作系统规定,除进程0之外,所有进程都要由一个已有进程在3特权级下创建。
在Linux0.11中,进程0的代码和数据都是由操作系统的设计者写在内核代码、数据区,并且,此前处在0特权级,严格说还不是真正意义上的进程。为了遵守规则,在进程0正式创建进程1之前,要将进程0由0特权级转变为3特权级。方法是调用move_ to_ user_ mode()函数,模仿中断返回动作,实现进程0的特权级从0转变为3。
//代码路径:init/main.c
void main()
{
...
move_to_user_mode();
...
}
//代码路径:include/system.h
#define move_to_user_mode() \
__asm__ ("movl %%esp,%%eax\n\t" \
"pushl $0x17\n\t" \ //ss 0b10111: CPL=3,LDT中的第3个描述符
"pushl %%eax\n\t" \ //esp
"pushfl\n\t" \ //flags
"pushl $0x0f\n\t" \ //cs 0b1111: CPL=3, LDT中的第2个描述符
"pushl $1f\n\t" \ //把标号1对应的eip压到栈中
"iret\n" \
"1:\tmovl $0x17,%%eax\n\t" \
"movw %%ax,%%ds\n\t" \
"movw %%ax,%%es\n\t" \
"movw %%ax,%%fs\n\t" \
"movw %%ax,%%gs" \
:::"ax")
手工模拟特权级从0到3的栈的内容,使用iret反转到3特权级,执行3特权级的代码
此时我们再来看一下进程0的LDT内容
/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x9ffff (=640kB)
*/
#define INIT_TASK \
/* state etc */ { 0,15,15, \
/* signals */ 0,{{},},0, \
/* ec,brk... */ 0,0,0,0,0,0, \
/* pid etc.. */ 0,-1,0,0,0, \
/* uid etc */ 0,0,0,0,0,0, \
/* alarm */ 0,0,0,0,0,0, \
/* math */ 0, \
/* fs info */ -1,0022,NULL,NULL,NULL,0, \
/* filp */ {NULL,}, \
{ \
{0,0}, \
/* ldt */ {0x9f,0xc0fa00}, \ //代码段,base=0,G=1,DPL=3,Execute/Read
{0x9f,0xc0f200}, \ //数据段,base=0,G=1,DPL=3,Read/Write
}, \
/*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\
0,0,0,0,0,0,0,0, \
0,0,0x17,0x17,0x17,0x17,0x17,0x17, \
_LDT(0),0x80000000, \
{} \
}, \
}
可以看到此时进程0的代码段都是从0开始,界限为640KB。ss0为0x10,指向GDT中内核数据段,esp0为init_task页面最顶端。
进程1的创建
进程0现在处在3特权级状态,即进程状态。正式开始运行要做的第一件事就是作为父进程调用fork函数创建第一个子进程—进程 1,这是父子进程创建机制的第一次实际运用。以后,所有进程都是基于父子进程创建机制由父进程创建出来的。
//代码路i纪念馆:init/main.c
static inline _syscall0(int, fork)
void main(void)
{
move_to_user_mode();
if(!fork()){
init();
}
/*
* NOTE!! For any other task 'pause()' would mean we have to get a
* signal to awaken, but task0 is the sole exception (see 'schedule()')
* as task 0 gets activated at every idle moment (when no other tasks
* can run). For task0 'pause()' just means we go check if some other
* task can run, and if not we return here.
*/
for(;;) pause();
}
//代码路径:include/unistd.h
#define __NR_setup 0 /* used only by init, to get system going */
#define __NR_exit 1
#define __NR_fork 2
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \ //将调用号传入eax寄存器中作为参数,fork中为2,2为sys_fork在sys_call_table中的偏移值
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
extern int errno;
//代码路径:include/linux/sys.h
extern int sys_setup();
extern int sys_exit();
extern int sys_fork();
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
执行int 0x80程序后,产生一个软中断,CPU从特权级3的进程0代码跳转到0特权级的内核代码中执行,中断将SS、ESP、EFLAGS、CS和EIP这5个寄存器自动压栈,压入init_task中的进程0内核栈。
# 代码路径:kernel/system_call.s
nr_system_calls = 72
.align 2
bad_sys_call:
movl $-1,%eax
iret
.align 2
reschedule:
pushl $ret_from_sys_call
jmp _schedule
.align 2
_system_call:
cmpl $nr_system_calls-1,%eax //比较eax中的进程号和nr_system_calls,查看
ja bad_sys_call //是否越界
push %ds //继续压入参数
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call _sys_call_table(,%eax,4) //执行函数
pushl %eax
movl _current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
ret_from_sys_call:
movl _current,%eax # task[0] cannot have signals
cmpl _task,%eax
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
call _do_signal
popl %eax
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
接下来到了我们的重点fork函数,代码如下
.align 2
_sys_fork:
call _find_empty_process
testl %eax,%eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call _copy_process
addl $20,%esp
1: ret
-
首先在task[64]中为进程1申请一个空闲位置并获取进程号
调用find_empty_process()函数为进程1获得一个可用的进程号和task[64]中的一个位置,将该位置放入eax寄存器中返回。
在该函数中,内核用全局变量last_pid来存放系统自开机以来累计的进程数,也将此变量用作新建进程的进程号(task_struct中的pid变量)。因为Linux 0.11的task[64]只有64项,最多只能同时运行64个进程,如果find_empty_process()函数返回-EAGAIN,意味着当前已经有64个进程在运行。
-
继续压入寄存器
-
调用copy_process函数
copy_process是我们关注的重点,接下来好好研究一下。
copy_process
进程0已经成为一个可以创建子进程的父进程,在内核中有“进程0的task_ struct” 和“进程0的页表项”等专属进程0的管理信息。进程0将在copy_ process() 函数中做非常重要的、体现父子进程创建机制的工作:
- 为进程1创建task_struct,将进程0的task_struct的内容复制给进程1
- 为进程1的task_struct、tss以及LDT中的内容做个性化设置
- 为进程1创建第一个页表,将进程0的页表项内容赋给这个页表
- 进程1共享进程0的文件
- 设置进程1的GDT项
- 最后将进程1设置为就绪态,使其可以参与进程间的轮转。
//代码路径:kernel/fork.c
/*
* Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It
* also copies the data segment in it's entirety.
*/
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
p->state = TASK_UNINTERRUPTIBLE;
p->pid = last_pid;
p->father = current->pid;
p->counter = p->priority;
p->signal = 0;
p->alarm = 0;
p->leader = 0; /* process leadership doesn't inherit */
p->utime = p->stime = 0;
p->cutime = p->cstime = 0;
p->start_time = jiffies;
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p; //内核栈发生变化,
p->tss.ss0 = 0x10;
p->tss.eip = eip; //int 0x80后面的那条指令
p->tss.eflags = eflags;
p->tss.eax = 0; //子进程fork返回值为0
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff; //es是long类型的,因此要取低16位
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr); //设置ldt
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current)
__asm__("clts ; fnsave %0"::"m" (p->tss.i387));
if (copy_mem(nr,p)) { //设置页表、以及ldt中段描述符的新基址
task[nr] = NULL;
free_page((long) p);
return -EAGAIN;
}
for (i=0; i<NR_OPEN;i++) //共享文件
if (f=p->filp[i])
f->f_count++;
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss)); //设置对应的GDT
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->state = TASK_RUNNING; /* do this last, just in case */
return last_pid; //父进程返回值为子进程的pid
}
其中比较重要的copy_mem函数,该函数改变了LDT中代码段和数据段的基址,将进程0的页表拷贝给进程1。
//代码路径:include/linux/sched.h
#define _set_base(addr,base) \
__asm__("movw %%dx,%0\n\t" \
"rorl $16,%%edx\n\t" \
"movb %%dl,%1\n\t" \
"movb %%dh,%2" \
::"m" (*((addr)+2)), \
"m" (*((addr)+4)), \
"m" (*((addr)+7)), \
"d" (base) \
:"dx")
#define _set_limit(addr,limit) \
__asm__("movw %%dx,%0\n\t" \
"rorl $16,%%edx\n\t" \
"movb %1,%%dh\n\t" \
"andb $0xf0,%%dh\n\t" \
"orb %%dh,%%dl\n\t" \
"movb %%dl,%1" \
::"m" (*(addr)), \
"m" (*((addr)+6)), \
"d" (limit) \
:"dx")
#define set_base(ldt,base) _set_base( ((char *)&(ldt)) , base )
#define set_limit(ldt,limit) _set_limit( ((char *)&(ldt)) , (limit-1)>>12 )
#define _get_base(addr) ({\
unsigned long __base; \
__asm__("movb %3,%%dh\n\t" \
"movb %2,%%dl\n\t" \
"shll $16,%%edx\n\t" \
"movw %1,%%dx" \
:"=d" (__base) \
:"m" (*((addr)+2)), \
"m" (*((addr)+4)), \
"m" (*((addr)+7))); \
__base;})
#define get_base(ldt) _get_base( ((char *)&(ldt)) )
#define get_limit(segment) ({ \
unsigned long __limit; \
__asm__("lsll %1,%0\n\t incl %0":"=r" (__limit):"r" (segment)); \
__limit;})
//代码路径:kernel/fork.c
int copy_mem(int nr,struct task_struct * p)
{
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
code_limit=get_limit(0x0f);
data_limit=get_limit(0x17);
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)
panic("Bad data_limit");
new_data_base = new_code_base = nr * 0x4000000;
p->start_code = new_code_base;
set_base(p->ldt[1],new_code_base);
set_base(p->ldt[2],new_data_base);
if (copy_page_tables(old_data_base,new_data_base,data_limit)) { //old_data_base 为 0,new_data_base为nr * 0x4000000,data_limit为640KB
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
}
return 0;
}
该函数更改进程1的代码段和数据段基址后调用copy_page_table设置页目录项和复制页表。
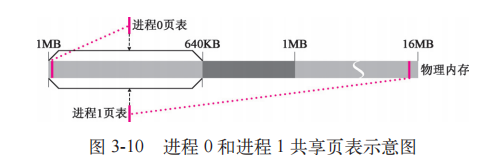
进入copy_ page_tables() 函数后,先为新的页表申请- - 个空闲页面,并把进程0中第一个页表里面前160 个页表项复制到这个页面中(1 个页表项控制一个页面4 KB内存空间,160 个页表项可以控制640KB内存空间)。进程0和进程1的页表暂时都指向了相同的页面,意味着进程1也可以操作进程0的页面。之后对进程1的页目录表进行设置。最后,用重置CR3的方法刷新页变换高速缓存。进程1的页表和页目录表设置完毕。
/*
* Well, here is one of the most complicated functions in mm. It
* copies a range of linerar addresses by copying only the pages.
* Let's hope this is bug-free, 'cause this one I don't want to debug :-)
*
* Note! We don't copy just any chunks of memory - addresses have to
* be divisible by 4Mb (one page-directory entry), as this makes the
* function easier. It's used only by fork anyway.
*
* NOTE 2!! When from==0 we are copying kernel space for the first
* fork(). Then we DONT want to copy a full page-directory entry, as
* that would lead to some serious memory waste - we just copy the
* first 160 pages - 640kB. Even that is more than we need, but it
* doesn't take any more memory - we don't copy-on-write in the low
* 1 Mb-range, so the pages can be shared with the kernel. Thus the
* special case for nr=xxxx.
*/
int copy_page_tables(unsigned long from,unsigned long to,long size)
{
unsigned long * from_page_table;
unsigned long * to_page_table;
unsigned long this_page;
unsigned long * from_dir, * to_dir;
unsigned long nr;
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
to_dir = (unsigned long *) ((to>>20) & 0xffc);
size = ((unsigned) (size+0x3fffff)) >> 22; //得到需要复制的页目录项个数,data_limit除以4MB,此时size = 1
for( ; size-->0 ; from_dir++,to_dir++) {
if (1 & *to_dir)
panic("copy_page_tables: already exist");
if (!(1 & *from_dir)) //看目录项最低为p位是否为1
continue;
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
if (!(to_page_table = (unsigned long *) get_free_page())) //为页表分配内存
return -1; /* Out of memory, see freeing */
*to_dir = ((unsigned long) to_page_table) | 7; //用户,可写,存在
nr = (from==0)?0xA0:1024; //如果是拷贝进程0的页表,则复制160个页表项,否则复制1024个页表项
for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {
this_page = *from_page_table;
if (!(1 & this_page))
continue;
this_page &= ~2; //用户,只读,存在
*to_page_table = this_page;
if (this_page > LOW_MEM) { //1MB以内的内核区不参与用户分页管理
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
}
}
invalidate(); //重置CR3为0,刷新”页高速缓存“
return 0;
}
执行结束后,进程1和进程0管理页面完全一致,因为页表项是完全拷贝过来的,所以他们共享页面。效果如下:
copy_process结束时,进程1的创建工作完成,进程1已经具备了进程0的全部能力,可以在主机中正常地运行。返回sys_fork()中call_copy_process()的下一行执行,执行代码如下:
.align 2
_sys_fork:
call _find_empty_process
testl %eax,%eax
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call _copy_process //返回值last_pid放在eax寄存器中,层层返回
addl $20,%esp //将前面的gs、esi、edi、ebp和eax出栈
1: ret
.align 2
_system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call _sys_call_table(,%eax,4)
pushl %eax //将进程号压栈
movl _current,%eax //检查当前进程的状态和counter位
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
ret_from_sys_call:
movl _current,%eax # task[0] cannot have signals
cmpl _task,%eax //如果当前进程是进程0,跳到下面的3执行
je 3f
cmpw $0x0f,CS(%esp) # was old code segment supervisor ?
jne 3f
cmpw $0x17,OLDSS(%esp) # was stack segment = 0x17 ?
jne 3f
movl signal(%eax),%ebx
movl blocked(%eax),%ecx
notl %ecx
andl %ebx,%ecx
bsfl %ecx,%ecx
je 3f
btrl %ecx,%ebx
movl %ebx,signal(%eax)
incl %ecx
pushl %ecx
call _do_signal
popl %eax //
3: popl %eax //将进程号放入eax寄存器中
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
由于当前进程是进程0,所以就跳到标号3处,将压栈的各个寄存器数值还原。之后iret中断返回,CPU硬件自动将int 0x80的中断时压入的ss、esp、eflags、cs和eip值按压栈的反序出栈给CPU对应寄存器,从0特权级的内核代码切换到3特权级的进程0代码执行,CS:EIP指向fork()中int 0x80的下一行if(_res >= 0)。
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
if (__res >= 0) \ <----------iret返回后就这一行,eax寄存器此时存放在_res中
return (type) __res; \
errno = -__res; \
return -1; \
}
return (type) _res将进程号1返回,回到调用点if(!fork())处执行,!1为假,这样就不会执行到init()函数中,而是进程0继续执行,直到pause()函数
void main(void)
{
move_to_user_mode();
if(!fork()) {
init();
}
for(; ;) pause(); //执行
}
进入pause函数后,最终会映射到sys_pause函数,该函数将进程置为可中断等待状态,同时调用schedule函数。
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
schedule();
return 0;
}
schedule代码如下:
/*
* 'schedule()' is the scheduler function. This is GOOD CODE! There
* probably won't be any reason to change this, as it should work well
* in all circumstances (ie gives IO-bound processes good response etc).
* The one thing you might take a look at is the signal-handler code here.
*
* NOTE!! Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
/*
* switch_to(n) should switch tasks to task nr n, first
* checking that n isn't the current task, in which case it does nothing.
* This also clears the TS-flag if the task we switched to has used
* tha math co-processor latest.
*/
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__("cmpl %%ecx,_current\n\t" \
"je 1f\n\t" \ //如果进程n是当前进程,则没必要切换,直接退出
"movw %%dx,%1\n\t" \
"xchgl %%ecx,_current\n\t" \
"ljmp %0\n\t" \ //通过TSS选择符进行跳转,此时保存各个寄存器到进程0的TSS中
"cmpl %%ecx,_last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
::"m" (*&__tmp.a),"m" (*&__tmp.b), \
"d" (_TSS(n)),"c" ((long) task[n])); \
}
ljmp跳转到进程1执行,将CPU的各个寄存器值保存在进程0的TSS中,将进程1的TSS数据以及LDT的代码段、数据段描述符数据恢复给CPU的各个寄存器,实现从0特权级的内核代码切换到3特权级的进程1代码执行。
进程1执行
当时为进程1的TSS中eax设置为0,eip设置为int 0x80下一指令的地址,即if(_res >= 0)。进程开始从这一行执行。
#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name)); \
if (__res >= 0) \ <----------进程0从这一行开始执行,但此时eax存放值为0
return (type) __res; \
errno = -__res; \
return -1; \
}
返回后,执行到main()函数中if(!fork())这一行,!0为“真”,调用init()函数!
void init(void)
{
int pid,i;
setup((void *) &drive_info);
(void) open("/dev/tty0",O_RDWR,0);
(void) dup(0);
(void) dup(0);
printf("%d buffers = %d bytes buffer space\n\r",NR_BUFFERS,
NR_BUFFERS*BLOCK_SIZE);
printf("Free mem: %d bytes\n\r",memory_end-main_memory_start);
if (!(pid=fork())) {
close(0);
if (open("/etc/rc",O_RDONLY,0))
_exit(1);
execve("/bin/sh",argv_rc,envp_rc);
_exit(2);
}
if (pid>0)
while (pid != wait(&i))
/* nothing */;
while (1) {
if ((pid=fork())<0) {
printf("Fork failed in init\r\n");
continue;
}
if (!pid) {
close(0);close(1);close(2);
setsid();
(void) open("/dev/tty0",O_RDWR,0);
(void) dup(0);
(void) dup(0);
_exit(execve("/bin/sh",argv,envp));
}
while (1)
if (pid == wait(&i))
break;
printf("\n\rchild %d died with code %04x\n\r",pid,i);
sync();
}
_exit(0); /* NOTE! _exit, not exit() */
}
执行setup函数对根文件系统初始化后,进程1又打开了/dev/tty0字符文件,之后调用fork函数创建进程2。
fork映射到sys_fork,执行过程和之前是一样的,会为进程2的task_struct以及内核栈申请页面,并复制task_struct,随后对进程2的task_struct进行各种个性化设置,包括各个寄存器的设置、内存页面的管理设置、共享文件的设置、GDT表项的设置等。不太一样的是进程2复制了进程1的1024个页表项。
进程2 shell
进程2创建完毕后,fork()函数返回,返回值为2,因此!(pid=fork())为假,于是调用wait()函数。此函数的功能是:如果进程1有等待退出的子进程,就为该进程的退出做善后工作;如果有子进程,但并不等待退出,则进行进程切换;如果没有子进程,函数返回。
//代码路径:/lib/wait.c
_syscall3(pid_t,waitpid,pid_t,pid,int *,wait_stat,int,options)
pid_t wait(int * wait_stat)
{
return waitpid(-1,wait_stat,0);
}
//代码路径:kernel/exit.c
int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
{
int flag, code;
struct task_struct ** p;
verify_area(stat_addr,4);
repeat:
flag=0;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
if (!*p || *p == current)
continue;
if ((*p)->father != current->pid)
continue;
if (pid>0) { //wait时传入pid为-1
if ((*p)->pid != pid)
continue;
} else if (!pid) {
if ((*p)->pgrp != current->pgrp)
continue;
} else if (pid != -1) {
if ((*p)->pgrp != -pid)
continue;
}
switch ((*p)->state) {
case TASK_STOPPED:
if (!(options & WUNTRACED))
continue;
put_fs_long(0x7f,stat_addr);
return (*p)->pid;
case TASK_ZOMBIE:
current->cutime += (*p)->utime;
current->cstime += (*p)->stime;
flag = (*p)->pid;
code = (*p)->exit_code;
release(*p);
put_fs_long(code,stat_addr);
return flag;
default: //此时进程2为就绪态,执行到这里
flag=1;
continue;
}
}
if (flag) {
if (options & WNOHANG)
return 0;
current->state=TASK_INTERRUPTIBLE; //将进程1设置为可中断等待状态
schedule(); //执行进程2
if (!(current->signal &= ~(1<<(SIGCHLD-1))))
goto repeat;
else
return -EINTR;
}
return -ECHILD;
}
轮转到进程2执行,进程2关闭文件后打开文件/etc/rc
if (!(pid=fork())) {
close(0);
if (open("/etc/rc",O_RDONLY,0))
_exit(1);
execve("/bin/sh",argv_rc,envp_rc);
_exit(2);
}
之后执行execve函数,进入内核对应_sys_execve函数
_sys_execve:
lea EIP(%esp),%eax
pushl %eax
call _do_execve
addl $4,%esp
ret
#define MAX_ARG_PAGES 32
/*
* 'do_execve()' executes a new program.
*/
int do_execve(unsigned long * eip,long tmp,char * filename,
char ** argv, char ** envp)
{
struct m_inode * inode;
struct buffer_head * bh;
struct exec ex;
unsigned long page[MAX_ARG_PAGES];
int i,argc,envc;
int e_uid, e_gid;
int retval;
int sh_bang = 0;
unsigned long p=PAGE_SIZE*MAX_ARG_PAGES-4;
if ((0xffff & eip[1]) != 0x000f)
panic("execve called from supervisor mode");
for (i=0 ; i<MAX_ARG_PAGES ; i++) /* clear page-table */
page[i]=0;
if (!(inode=namei(filename))) /* get executables inode */
return -ENOENT;
argc = count(argv);
envc = count(envp);
restart_interp:
if (!S_ISREG(inode->i_mode)) { /* must be regular file */
retval = -EACCES;
goto exec_error2;
}
i = inode->i_mode; //文件uid、gid暂时还看不懂
e_uid = (i & S_ISUID) ? inode->i_uid : current->euid;
e_gid = (i & S_ISGID) ? inode->i_gid : current->egid;
if (current->euid == inode->i_uid)
i >>= 6;
else if (current->egid == inode->i_gid)
i >>= 3;
if (!(i & 1) &&
!((inode->i_mode & 0111) && suser())) {
retval = -ENOEXEC;
goto exec_error2;
}
if (!(bh = bread(inode->i_dev,inode->i_zone[0]))) {
retval = -EACCES;
goto exec_error2;
}
ex = *((struct exec *) bh->b_data); /* read exec-header */
if ((bh->b_data[0] == '#') && (bh->b_data[1] == '!') && (!sh_bang)) {
/*
* This section does the #! interpretation.
* Sorta complicated, but hopefully it will work. -TYT
*/
char buf[1023], *cp, *interp, *i_name, *i_arg;
unsigned long old_fs;
strncpy(buf, bh->b_data+2, 1022);
brelse(bh);
iput(inode);
buf[1022] = '\0';
if (cp = strchr(buf, '\n')) {
*cp = '\0';
for (cp = buf; (*cp == ' ') || (*cp == '\t'); cp++);
}
if (!cp || *cp == '\0') {
retval = -ENOEXEC; /* No interpreter name found */
goto exec_error1;
}
interp = i_name = cp;
i_arg = 0;
for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++) {
if (*cp == '/')
i_name = cp+1;
}
if (*cp) {
*cp++ = '\0';
i_arg = cp;
}
/*
* OK, we've parsed out the interpreter name and
* (optional) argument.
*/
if (sh_bang++ == 0) {
p = copy_strings(envc, envp, page, p, 0);
p = copy_strings(--argc, argv+1, page, p, 0);
}
/*
* Splice in (1) the interpreter's name for argv[0]
* (2) (optional) argument to interpreter
* (3) filename of shell script
*
* This is done in reverse order, because of how the
* user environment and arguments are stored.
*/
p = copy_strings(1, &filename, page, p, 1);
argc++;
if (i_arg) {
p = copy_strings(1, &i_arg, page, p, 2);
argc++;
}
p = copy_strings(1, &i_name, page, p, 2);
argc++;
if (!p) {
retval = -ENOMEM;
goto exec_error1;
}
/*
* OK, now restart the process with the interpreter's inode.
*/
old_fs = get_fs();
set_fs(get_ds());
if (!(inode=namei(interp))) { /* get executables inode */
set_fs(old_fs);
retval = -ENOENT;
goto exec_error1;
}
set_fs(old_fs);
goto restart_interp;
}
brelse(bh); //检测可执行文件是否可执行
if (N_MAGIC(ex) != ZMAGIC || ex.a_trsize || ex.a_drsize ||
ex.a_text+ex.a_data+ex.a_bss>0x3000000 ||
inode->i_size < ex.a_text+ex.a_data+ex.a_syms+N_TXTOFF(ex)) {
retval = -ENOEXEC;
goto exec_error2;
}
if (N_TXTOFF(ex) != BLOCK_SIZE) {
printk("%s: N_TXTOFF != BLOCK_SIZE. See a.out.h.", filename);
retval = -ENOEXEC;
goto exec_error2;
}
if (!sh_bang) {
p = copy_strings(envc,envp,page,p,0); //分配页面,将环境变量和参数拷贝到新分配的页面中
p = copy_strings(argc,argv,page,p,0); //page数组存放的分配页面的物理地址
if (!p) {
retval = -ENOMEM;
goto exec_error2;
}
}
/* OK, This is the point of no return */
if (current->executable)
iput(current->executable); //减少inode的引用数,由于进程2复制进程1的执行文件是0,所以不会执行
current->executable = inode;
for (i=0 ; i<32 ; i++)
current->sigaction[i].sa_handler = NULL;
for (i=0 ; i<NR_OPEN ; i++)
if ((current->close_on_exec>>i)&1) //遍历close_on_exec,关闭需要关闭的文件
sys_close(i);
current->close_on_exec = 0;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f)); //非常关键,并不直接将可执行文件读进内存然后设置页表来映射,需要触发缺页中断开始执行
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
if (last_task_used_math == current)
last_task_used_math = NULL;
current->used_math = 0;
p += change_ldt(ex.a_text,page)-MAX_ARG_PAGES*PAGE_SIZE; //修改数据段的data limit为data_limit = 0x4000000;最高地址准备存放环境变量和参数
p = (unsigned long) create_tables((char *)p,argc,envc); //设置环境变量parses the env- and arg-strings in new user memory and creates the pointer tables from them, and puts their addresses on the "stack", returning the new stack pointer value.
current->brk = ex.a_bss +
(current->end_data = ex.a_data +
(current->end_code = ex.a_text));
current->start_stack = p & 0xfffff000; //
current->euid = e_uid;
current->egid = e_gid;
i = ex.a_text+ex.a_data;
while (i&0xfff)
put_fs_byte(0,(char *) (i++));
eip[0] = ex.a_entry; /* eip, magic happens :-) */ //改变栈上的内容
eip[3] = p; /* stack pointer */ //设置eip和esp
return 0;
exec_error2:
iput(inode);
exec_error1:
for (i=0 ; i<MAX_ARG_PAGES ; i++)
free_page(page[i]);
return(retval);
}
shell程序开始执行时,其线性地址空间对应的程序内容并未加载,也就不存在相应的页面,因此会产生一个“页异常”中断,此中断会进一步调用“缺页中断”处理程序来分配该页面,并加载一页shell程序。
//代码路径:mm/page.s
.globl _page_fault
_page_fault:
xchgl %eax,(%esp) //error code
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10,%edx
mov %dx,%ds
mov %dx,%es
mov %dx,%fs
movl %cr2,%edx //address
pushl %edx //addr
pushl %eax //error code
testl $1,%eax //p bits
jne 1f //p != 0
call _do_no_page //p = 0 means no page
jmp 2f
1: call _do_wp_page
2: addl $8,%esp
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret
通过检测error code后调用do_no_page()函数,先确定缺页的原因。加入是由于需要加载程序才却页。会尝试与其他进程共享shell(显然此前没有进程加载过shell,无法共享),于是申请一个页面,调用bread_page()函数,从虚拟盘上读取4块(4KB,一页)shell程序内容,载入内存页面。
void do_no_page(unsigned long error_code,unsigned long address)
{
int nr[4];
unsigned long tmp;
unsigned long page;
int block,i;
address &= 0xfffff000;
tmp = address - current->start_code;
if (!current->executable || tmp >= current->end_data) {
get_empty_page(address);
return;
}
if (share_page(tmp))
return;
if (!(page = get_free_page()))
oom();
/* remember that 1 block is used for header */
block = 1 + tmp/BLOCK_SIZE;
for (i=0 ; i<4 ; block++,i++)
nr[i] = bmap(current->executable,block);
bread_page(page,current->executable->i_dev,nr); //读取四个逻辑块(1页)的shell程序内容进内存页面
i = tmp + 4096 - current->end_data;
tmp = page + 4096;
while (i-- > 0) {
tmp--;
*(char *)tmp = 0;
}
if (put_page(page,address)) //修改页表,建立映射
return;
free_page(page);
oom();
}
载入一页的shell程序后,内核会将该页内容映射到shell进程的线性地址空间内,建立页目录表->页表->页面的三级映射管理关系。
进程3 update
之后进程2读取rc文件上的信息,fork出了update进程,这个新进程的进程号为3。update进程有一项很重要的任务:将缓冲区中的数据同步到外色号(软盘、硬盘)上。由于主机与外设的数据交换速度远低于主机内部的数据处理速度,因此,当内核需要往外设上写数据的时候,为了提高系统的整体执行效率,并不把数据直接写入到外设上,而是先写入缓冲区,之后根据实际情况,再将数据从缓冲区同步到外设。
每隔一段时间,update进程就会被唤醒,把数据往外设上同步一次,之后这个进程会被挂起,即被设置为可中断等待状态,等待着下一次被唤醒后继续执行,如此周而复始。
update进程执行后,没有同步任务,于是该进程被挂起,系统执行进程调度,最终切换到shell进程继续执行。
完成工作后调用exit()函数,对应的系统调用函数为sys_exit(),执行代码如下
int sys_exit(int error_code)
{
return do_exit((error_code&0xff)<<8);
}
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
for (i=0 ; i<NR_TASKS ; i++)
if (task[i] && task[i]->father == current->pid) { //寻找子进程
task[i]->father = 1; //将子进程父进程设置为1
if (task[i]->state == TASK_ZOMBIE)
/* assumption task[1] is always init */
(void) send_sig(SIGCHLD, task[1], 1); //如果子进程为zombie,即已经调用了exit函数,给进程1发送信号。
}
for (i=0 ; i<NR_OPEN ; i++)
if (current->filp[i])
sys_close(i);
iput(current->pwd);
current->pwd=NULL;
iput(current->root);
current->root=NULL;
iput(current->executable);
current->executable=NULL;
if (current->leader && current->tty >= 0)
tty_table[current->tty].pgrp = 0;
if (last_task_used_math == current)
last_task_used_math = NULL;
if (current->leader)
kill_session();
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}
值得注意的是tell_father()和schedule()函数的执行,tell_father向父进程发送SIGCHLD信号
static void tell_father(int pid)
{
int i;
if (pid)
for (i=0;i<NR_TASKS;i++) {
if (!task[i])
continue;
if (task[i]->pid != pid)
continue;
task[i]->signal |= (1<<(SIGCHLD-1));
return;
}
/* if we don't find any fathers, we just release ourselves */
/* This is not really OK. Must change it to make father 1 */
printk("BAD BAD - no father found\n\r");
release(current);
}
tell_father()函数执行完毕后,调用schedule()函数准备进程切换。此次schedule()函数中对信号的检测,影响了进程切换
/*
* 'schedule()' is the scheduler function. This is GOOD CODE! There
* probably won't be any reason to change this, as it should work well
* in all circumstances (ie gives IO-bound processes good response etc).
* The one thing you might take a look at is the signal-handler code here.
*
* NOTE!! Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING; //将进程1设置为task_running
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(next);
}
将进程1设置为task_running后,后面调度到进程1执行,此时task1还在schedule函数中,执行完毕后继续执行sys_waitpid()函数
int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
{
int flag, code;
struct task_struct ** p;
verify_area(stat_addr,4);
repeat:
flag=0;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
if (!*p || *p == current)
continue;
if ((*p)->father != current->pid)
continue;
if (pid>0) {
if ((*p)->pid != pid)
continue;
} else if (!pid) {
if ((*p)->pgrp != current->pgrp)
continue;
} else if (pid != -1) {
if ((*p)->pgrp != -pid)
continue;
}
switch ((*p)->state) {
case TASK_STOPPED:
if (!(options & WUNTRACED))
continue;
put_fs_long(0x7f,stat_addr);
return (*p)->pid;
case TASK_ZOMBIE: //找到子进程的状态为task_zombie
current->cutime += (*p)->utime;
current->cstime += (*p)->stime;
flag = (*p)->pid; //记录进程2的pid
code = (*p)->exit_code;
release(*p); //释放他的task_struct页面
put_fs_long(code,stat_addr);
return flag;
default:
flag=1;
continue;
}
}
if (flag) {
if (options & WNOHANG)
return 0;
current->state=TASK_INTERRUPTIBLE;
schedule();
if (!(current->signal &= ~(1<<(SIGCHLD-1)))) //执行到这里,检测到SIGCHLD,确定有子进程要退出,if条件成立,repeat
goto repeat;
else
return -EINTR;
}
return -ECHILD;
}
sys_waitpid()函数执行完毕后,会回到wait()函数,最后返回到init()函数中,进程1继续执行。
void init(void)
{
int pid,i;
setup((void *) &drive_info);
(void) open("/dev/tty0",O_RDWR,0);
(void) dup(0);
(void) dup(0);
printf("%d buffers = %d bytes buffer space\n\r",NR_BUFFERS,
NR_BUFFERS*BLOCK_SIZE);
printf("Free mem: %d bytes\n\r",memory_end-main_memory_start);
if (!(pid=fork())) {
close(0);
if (open("/etc/rc",O_RDONLY,0))
_exit(1);
execve("/bin/sh",argv_rc,envp_rc);
_exit(2); //不会执行到这句话
}
if (pid>0)
while (pid != wait(&i)) //此时wait的返回值为2,while条件为假,退出
/* nothing */;
while (1) {
if ((pid=fork())<0) { //fork进程
printf("Fork failed in init\r\n");
continue;
}
if (!pid) { //此时进程号为4,虽然在task数组中索引为2(因为之前shell进程还fork出了一个update进程,该进程pid为3
close(0);close(1);close(2);
setsid();
(void) open("/dev/tty0",O_RDWR,0); //
(void) dup(0);
(void) dup(0);
_exit(execve("/bin/sh",argv,envp));
}
while (1)
if (pid == wait(&i)) //因为进程1是所有孤儿进程的父进程,因此要一直wait,从而release子进程
break;
printf("\n\rchild %d died with code %04x\n\r",pid,i);
sync();
}
_exit(0); /* NOTE! _exit, not exit() */
}
进程4 shell
这次shell打开的是标准输入设备文件tty0而不是rc,这使得shell开始执行后,不再退出。进入rw_char()函数后,shell进程将被设置为可中断等待状态,这样所有的进程都处于可中断等待状态,再次切换到进程0去执行,系统实现怠速。
怠速以后,操作系统用户将通过shell进程提供的平台与计算机进行交互,shell进程处理用户指令的工作原理如下:用户通过键盘输入信息,存储在指定的字符缓冲队列上。该缓冲队列上的内容,就是tty0文件的内容,shell进程会不断读取缓冲队列上的数据信息。如果用户没有下达指令,缓冲队列就不会有数据,shell进程将会被设置为可终端等待状态,即被挂起。如果用户通过键盘下达指令,将产生键盘中断,中断程序会将字符信息存储在缓冲队列上,并给shell进程发信号,信号将导致shell进程被设置为就绪状态,即被唤醒,唤醒后的shell继续从缓冲队列中读取数据信息并处理,完毕后,shell进程将再次被挂起,等待下一次键盘中断被唤醒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号