编码问题(上)
前言
一旦走上了编程之路,如果你不把编码问题搞清楚,那么它将像幽灵一般纠缠你整个职业生涯,各种灵异事件会接踵而来,挥之不去。只有充分发挥程序员死磕到底的精神你才有可能彻底摆脱编码问题带来的烦恼
——知乎 刘志军
你是否也曾遇到如下问题?
- 控制窗口显示“烫烫烫烫烫烫烫”
- 中文软件显示中文乱码
- 打开文件里面都是???
如果你遇到了,那么恭喜你,遇到了计算机领域里难缠的编码问题,当你遇到这种问题时,总会上网查教程,教程中要么让你在文件前面加 \# -*- coding: utf-8 -*-;要么让你设置编辑器的编码方式,或者使用notepad++转一下编码方式;要么就让你更改windows操作系统的系统时区和语言设置,但你是否真的了解过这些操作到底代表着什么?如果你有摆脱编码困扰的想法,那本文有你想要的答案。
编码的历史
知其然,知其所以然
当计算机要与人进行交互时,显示器这个外设便登入了历史舞台,人们便遇到这样一个问题,确切的说,美国计算机学家遇到了这样的问题——“如何将字符存储在计算机中”,倘若你对计算机有一定了解的话,也一定知道计算机存储的数据以二进制来表示,如100表示数字4,每一个二进制位称为一个比特(bit),100便有3个比特,那么我们只需要设定一个映射,从比特序列映射到特定的字符,便可以实现计算机的数据到显示器字符的转换。比如我设定一个映射条目:100->'A',当计算机取出100的时候,知道应该在显示器上显示A这个字符,这种映射就称之为编码。
ASCII码
美国科学家也是这么想的,于是制定了一套字符编码,称之为ASCII码,用7位比特来映射128(2[^7])个字符,这128个字符中有33个控制字符如换行、回车和删除等,剩下的95个为打印字符。比如用0100000表示空格,1000001表示‘A’。由于计算机内存的最小寻址单元是一个字节,也就是8比特位,这就表明你存放数据最少得存放8比特位,假如说你要求显示器这里应当显示A,于是要将1000001放在特定的位置上,但是计算机最少写入8比特位,少了1比特没办法存怎么办?于是ASCII码规定,剩下的那个高位默认为0,也就是我存A的时候存01000001,完美地解决了该问题。
ASCII码的出现完美地解决了美国人民的需求,可计算机在世界范围得到应用时,各国人民,或者说使用者不同语言的人民都有将自己的文化符号显示在显示器的需求,那可如何是好呢?
编码百花齐放
上一章说到ASCII码中多出来一位,很多国家便打起了这一位的注意,他们于是将10000000-11111111范围内的比特进行编码,映射到自己国家的语言上,这些编码和ASCII码相互兼容,但彼此之间互不兼容。如美国机器上的A,在计算机中为01000001,到了法国,法国用自己的编码解释01000001还是A,于是可以看懂美国人发的文件,但如果法国发送一个编码在10000000-11111111范围内的符号给其他国家,便会造成乱码问题,比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。这便解开了乱码问题的序幕。
值得一提的是,我国在编码百花齐放时代也有自己的编码,下面进行详细的阐述。
中文编码三部曲
注:这里对中文编码只是简单概述,你可能之前听过或见过中文编码中的区位码,国标码、内码等概念,但本文并不涉及,详细信息可见参考资料[2]
-
GB2312
对于有些国家用ASCII码不用的比特来编码自己的符号是够用的,显然我们国家是不够用的,中华文化博大精深,汉字的个数肯定不是一个字节所能编码的了,于是一个字节不行就加一个字节,我国推出了GB2312标准用两个字节对汉字进行编码,这种编码也称之为双字节字符集编码(Double Byte Character Set,DBCS),第一个字节称为“高位字节”(也称区字节),第二个字节称为低位字节(也称位字节),为了和ASCII码不冲突且保持兼容,GB2312规定两个字节的均不能低于10000001(0x81),于是高位字节范围0xA1-0xF7,低位字节范围0xA1-0xFE,可以试想,这样读取字节时,如果字节范围小于0x81,则是ASCII码,如果大于0x81,处于0xA1-0xF7之间,则说明是GB2312码,那么读取下一个字节,两个字节共同编码字符。
有意思的是,GB2312编码中将原来ASCII里面本来就有的数字、标点、字母等符号又进行了重新编码,比如用0xa3e8编码字符h,而ASCII码已经采用0x68对h进行了编码,这不禁让人疑惑“为什么要浪费空间,对一个编码过的字符重新编码?”,这就要引入对全角、半角问题的讨论了。

上图为输入法的界面,第四个框框表示当前输入字符是半角字符还是全角字符,半月形为半角、圆形为全角。
早期的点阵显示器由于显示像素有限,当显示中文字符时,用显示英文字符的显示宽度(比如8像素的显示宽度)来显示中文字符显示不下,于是采用了更宽的空间(两倍的宽度)来显示中文字符,处于显示美观的考虑,为了令英文字符和中文字符对齐,于是设计了令英文字符、数字和标点等特殊字符在外观视觉上也占用一个汉字的宽度,这种字符采用两个字节进行编码,这些字符也称为全角字符。
总结一下:
- 半角字符就是ASCII码表进行编码的字母、标点和数字,他们在计算机中占一个字节,显示屏幕占据一个显示宽度
- 全角字符就是指ASCII编码表以外的字符、标点和数字,在计算机占据多个字节,显示屏幕占据两个显示宽度(和汉字有相同的显示宽度)[3]。
例:
中文半角:哈哈哈哈hhhh,,,。。。111
中文全角:哈哈哈哈hhhh,,,。。。111
英文半角:hhhh,,,...111
英文全角:hhhh,,,...111
可以很明显的看到半角字符和全角字符在屏幕上占据的空间不一样,全角的英文字符和中文字符占据相同的空间即对齐。
-
GBK
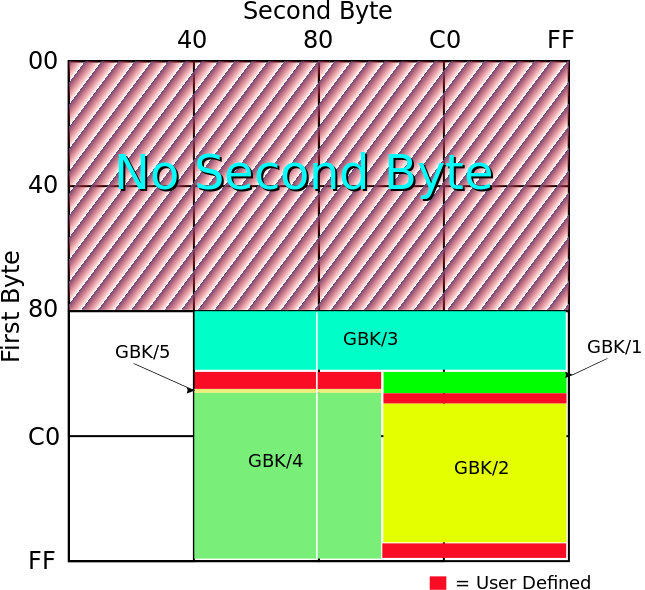
GB2312编码收录的汉字覆盖中国大陆99.75%的使用频率,但对人名、古汉语等方面出现的罕用字却无法处理,比如对我国前总理***中的*就没有进行收录,于是GBK应运而生,规定仍采用两个字节进行编码,但只需要高位字节不小于10000001(0x81)即可,低位字节不做要求,这大大扩展了GBK标准可以编码的范围。于是高位字节的范围扩展到了0x81-0xFE,低位字节范围为0x40-0xFE(不包括0x7F),可见其范围扩大了许多,同时也兼容ASCII编码和GB2312编码。
-
GB18030
GB18030是目前(公元2021年)我国最新的编码标准,与前面两位最大的不同是GB18030是变长编码,每个字可以由1个、2个或者4个字节编码,编码空间庞大,最多可定义161万个字符,且和GBK、GB2312、ASCII码都兼容。
由下表可知,对于在ASCII码表的字符,采用一个字节进行编码,与ASCII码保持兼容,对于在GBK码表的字符,采用两个字节进行编码,与GBK保持兼容,对于GBK低位字节没用到的空间0x30-0x39,GB18030加以利用,编码了更多的字符。
GB 18030 code points Unicode byte 1 (MSB) byte 2 byte 3 byte 4 00–7F128 0000–007F80— invalid 81–FE40–FEexcept7F23940 0080–FFFFexceptD800–DFFF81–8430–3981–FE30–3939420 0080–FFFFexceptD800–DFFF85— (12600) reserved for future character extension 86–8F— (126000) reserved for future ideographic extension unassigned — D800–DFFF90–E330–3981–FE30–391048576 10000–10FFFFE4–FC— (315000) reserved for future standard extension FD–FE— (25200) user-defined FF— invalid Total 1112064
好,到此为止中文编码我们就粗略的讲完了,希望读者不要过多纠缠细节,而是将这三种编码视为黑盒,涉及到的时候需要知道GB2312、GBK为二字节编码,与ASCII码兼容,GB18030为变长编码,且与GBK、GB2312保持兼容即可。因为我们还有更重要的编码需要讨论,即Unicode。
Unicode编码字符集
希望读者注意到,本节标题为Unicode编码字符集而不是Unicode编码,其中的不同,后文会详细叙述。
USC项目和Unicode项目
编码百花齐放对各国是好事,每个国家都可以在计算机上显示自己的语言,但对于全球来说,出现的各种字符集往往互不兼容,导致了乱码问题,为了避免混乱,ISO(国际标准化组织)发起了ISO 10646项目,名为“Universal Multiple Octet Coded Character Set”,简称UCS,希望将世界所有字符进行编码,形成一个统一的字符集,同时期,各大企业和组织成立了Unicode联盟,同样是为了寻求一个统一的字符集。一开始两个字符集并不兼容,但很快双方都意识到这个世界不需要两个互不兼容的字符集,于是友好地决定合并工作,项目各自独立存在,但两者保持兼容,不过由于Unicode这一名字好记,因而它使用更为广泛,成为了事实上的统一编码标准。

Unicode介绍
前面说过,Unicode只是一个字符集,并不是一个编码,这句话是什么意思?
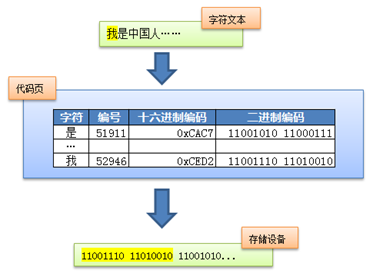
我们回顾一下之前的编码,ASCII、GB2312、GBK等,在Unicode出现之前,所有的字符集都是和具体编码绑定在一起的,即符号对应的二进制数最终就是计算机上存储的数据,比如GBK中用0xced2来编码“我”,那么在计算机存储设备里面对应存储的就是数据0xced2,这样的编码系统通常通过简单的查表,也就是代码页就可以直接将字符映射为存储设备上的字符流了[4],例如下图
但这样做的缺点是,字符和字符流之间的耦合太紧密了,不适于进行字符集扩展。因此Unicode在设计上考虑了这一点,将字符集和字符编码方案分开。
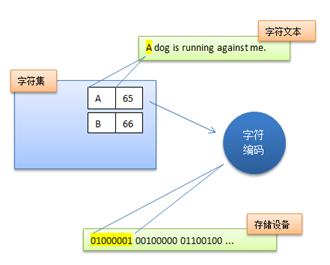
于是,每个字符都在Unicode编码字符集中都能找到唯一的编码(称之为码点),但最终在存储设备上的却是具体的编码,如对Unicode字符“A”进行编码,Unicode中A的值为U+0041,UTF-8编码为0x41,而UTF-16(大端模式)编码的是0x0041。为此我们引入两个概念:编码字符集(Coded Character Set,CCS)和字符编码表(Character Encoding Form,CEF)[5]:
- Coded Character Set(CCS): 即编码字符集,给字符表里的抽象字符编上一个数字,也就是字符集合到一个整数集合的映射。这种映射称为编码字符集,Unicode 字符集就是属于这一层的概念;
- Character Encoding Form (CEF) :即字符编码表,根据一定的算法,将编码字符集(CCS) 中字符对应的码点转换成一定长度的二进制序列,以便于计算机处理,这个对应关系被称为字符编码表,UTF-8、 UTF-16 属于这层概念;
因此可见之前的编码既属于CCS也属于CEF,而Unicode只属于CCS的范畴,下文我们不再称呼Unicode编码字符集,而是直接简写为Unicode,但希望读者不要混淆概念,牢记Unicode只是一个字符集,并不对应于存储设备上的编码,这一工作交给了UTF三兄弟去做。
Unicode为每一个字符分配一个唯一的字符编号即码点(Code Point),用U+紧跟着16进制数表示,如U+597D表示中文“好”,所有字符按照使用上的频繁度划分为17个平面(编号为0-16),每一个平面有2[^16] = 65536个字符,第一个平面称为*本平面(Basic Multilingual Plane,BMP),收集了使用最广泛的字符,码点范围从U+0000到U+FFFF,剩余的16个平面成为辅助平面(SMP),码点范围从U+010000到U+10FFFF。
Unicode编码三兄弟
前面说了Unicode完成了字符集合到整数(码点)集合的映射,下面需要实现字符对应的码点到二进制序列的映射,这种编码方式有很多如UTF-8、UTF-16、UTF-32等,这里的UTF是Unicode Transformation format的简写,下面来对这三个编码方式进行详细介绍。
UTF-32
虽然UTF-16是最早的Unicode字符集编码方式,但笔者认为从UTF-32介绍更符合我们的直觉。
既然Unicode有17个平面,码点范围从U+000000到U+10FFFF,那我们直接采用4字节来表示岂不美哉,多余的一字节直接补0,例如用0x0000 0000表示U+0000,0x0010 FFFF表示U+10FFFF,这样转换简单直观,但有个比较大的问题,就是太浪费空间了,大家经常用的都是英文字符,一个字节就足以表示,即使使用中文,在Unicode编码两个字节也足够了,UTF-32采用一刀切策略,使得原本很小的文件直接扩大了2倍-4倍,这是无法容忍的,因此我们需要一个更好的、更节省空间的编码方式。
UTF-16
UTF-16避开了UTF-32的缺点,采用”分治“的策略,对*本平面的码点用2字节表示,对辅助平面的码点用4字节表示。
对于*本平面的码点,UTF-16编码的结果和*本平面的码点一致,如0x0041表示U+0041,但对于辅助平面的我们不能直接补零,因为这样会造成一个问题:对于UTF-16编码的文件,当你读取两个字节的时候,你怎么知道这两个字节属于*本平面编码还是辅助平面编码?如果是*本平面的话,那太好了,这两个字节直接查Unicode表就可以知道对应字符了,如果是辅助平面那么就得再读取两个字节才能查Unicode表。所以直接编码的话会给我们判断*本平面编码还是辅助平面编码带来问题。因此我们采用下面方式编码:
在Unicode*本平面中U+D800到U+DFFF是空段,并没有用来编码字符,因此这个空段可以用来对辅助平面进行映射。辅助平面共16个,每个平面大小为65536,因此总空间为2[^20],我们需要20位来表示这么多字符,我们将20位分为两个部分,前面两个字节提供10位,后面两个字节提供10位,因此前面两个字节用0xD800-0xDBFF(10位)的空间编码,后两个字节用0xDC00-0xDFFF(10位)的空间进行编码,这就表明,当读取到两个字节时,如果在0xD800-0xDBFF范围内,则表明为辅助平面内的字符,再读取两个字节,这两个字节的范围一定在0xDC00-0xDFFF之间,然后通过解码规则还原码点,再根据Unicode表就可以找到对应字符了;如果字节范围不在0xD800-0xDBFF之间,则表明为*本空间内的字符,直接用读取的两个字节值根据Unicode表找到对应字符即可。
具体编码规则如下:
-
*本平面字符
直接转换
-
辅助平面字符[6]
- 第一步,Unicode码点值减去0x10000,结果在0x00000-0xFFFFF之间
- 前16比特加上0xD800,为高两个字节的值
- 后16比特加上0xDC00,为低两个字节的值
资料[7]中有具体的编码例子,读者可以前往查看,帮助理解。
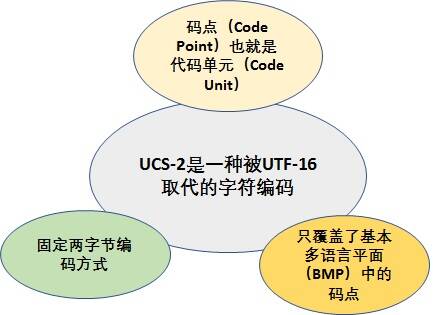
说到了UTF-16,不得不提一嘴UCS-2,USC项目和Unicode项目章节提到过这两个组织同时期建立,目标相同,最后决定合并字符集。但UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是*本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即*本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2[7]。
USC-2编码方式:
UTF-8
UTF-8相比于UTF-16来说,空间利用率更高,也是互联网上使用最广的编码方式。它可以使用1-4个字节来编码一个符号。其编码规则如下图所示:
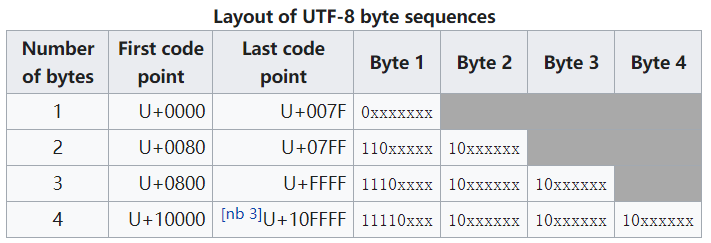
- 对于U+0000-U+007F的内容,用一个字节编码,字节最高位置为0,其余位和Unicode相同(可以发现,这样编码和ASCII码兼容)
- 对于U+007F以上的内容,第一个字节的前n位置为1,然后紧跟一个0,其余字节的高两位置为10,剩下的位用Unicode码点进行填充。(n为编码字节数)
同样是变长编码,UTF-8不像UTF-16一样有类似的问题:当读取字节时,如何知道当前字节是否已经可以编码一个字符了,是否需要继续读取字节?因为UTF-8的第一个字节的高位1的个数已经告知了我们几个字节编码一个字符,因此当我们读取第一个字节后,就可以知道还需要读取几个字节,比如若第一个字节最高位为0,则不用读取字节,直接查Unicode表转换为字符;若高位字节为11110xxx,则还需要读取三个字节,然后才能查Unicode表转换字符。因此我们说UTF-8是面向字节流的,每次读取utf-8文件需要一个字节一个字节地读取,这对我们等会理解UTF-8不需要BOM很有帮助。
编码的确定
介绍完了编码的历史,不知道大家会不会有这样的疑问:“对于一个文件,我怎么知道他的编码方式是什么,如果我不知道他的编码方式,那么我如何解码呢?”,这个问题确实存在,因为我们打开一个文件,确实是无法提前得知文件的编码方式的,要知道,操作系统存储的有关文件的信息中并不包含“编码方式”这一个条目。
UTF编码内部确定
为了解决该问题,Unicode规定在文件头部需要出现BOM(Byte Order Mark,字节顺序标记)来标识文件编码和大小端存储方式。
- UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 “零宽无间断间隔” 的 UTF-8 编码是 EF BB BF,如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8 编码了。
- Big-Endian(BE)即大端序,UTF-16(BE)以 FEFF 作为开头字节,UTF-32(BE)以 00 00 FE FF 作为开头字节;
- Little-Endian(LE)即小端序,UTF-16(LE)以 FFFE 作为开头字节,UTF-32(LE)以 FF FE 00 00 作为开头字节[5]
关于大小端,很多文章均有说明,此处不予阐述。
这里值得探讨的是为什么UTF-8不需要BOM来表示字节顺序,而UTF-16和UTF-32均需要?UTF-32就不用说了,四个字节四个字节地存储,肯定会有大端小端问题,因此需要BOM来表示字节顺序;UTF-16也是需要两个字节两个字节地存储和读取,如字符𐐷的Unicode码点是U+10437,其UTF-16编码为0xD801 DC37,那么大端就是D8 01 DC 37,小端就是01 D8 37 DC,可以看到其字节顺序的变化是以两个字节为单位的,颠倒的是两个字节内的顺序;而UTF-8是面向字节流的,无大端小端之分,一开始很疑惑,认为他既然不是一个字节的数据,而是1-4个字节的数据,对于大于1字节的数据,当存放到存储设备上时,肯定有大端小端之分呀,比如一个一个“严”的utf-8编码为0xE4B8A5,存放在内存上的时候应该是
0000----------------------------------------------->FFFF(内存地址)
E4 B8 A5
大端👆
还是下面
0000----------------------------------------------->FFFF(内存地址)
A5 B8 E4
小端👆
所以当时我认为只有知道大端小端序才能知道怎么解析数据,后来明白虽然事实上看起来utf-8存放的方式总是”大端法“,但是其实是因为utf-8的第一个字节必须放在最前面(内存最低处),因为该字节告诉了数据的字节数量,所以解析utf-8编码时要一个字节一个字节的读取,并不是类似于int、long类型的数据,需要四个字节八个字节的读取,只有这样当读到数据的第一个字节,根据1的个数才能知道还需要读取几个字节,所以说他是面向字节流的,也不需要大小端存储,必然是第一个带有指示信息的数据放在前面,第一个读取。
不同编码确定
对于不同的UTF编码,我们可以根据其文件开头的BOM来确定其编码方式和大小端存储方式,那么对于不带BOM的utf编码如何确定呢,以及如何确定这个编码是utf编码还是GBK等编码呢?很遗憾,只能靠猜。当然实际情况不像我说的那么不堪,而是按照大量的编码进行分析,就是先读取一些字节,然后分析字节流,根据编码方式的相似程度从而决定该文件采用哪个编码方式进行解码。这时你可能会问:“猜的准确度应该还挺高的吧,为什么我经常碰见打开文件乱码问题?”,答案是只有少部分编辑软件这么智能,大多数的软件都采用默认的解码方式打开文件,待会你看到的windows中记事本的ANSI编码便是典型的例子。
实践
实践是检验真理的唯一标准
工欲善其事必先利其器
-
notepad++
强大的文本编辑器。
-
notepad++中的插件hex-editor
方便我们查看文件的16进制内容,也就是文件在磁盘上的字节流。
当我们开始实践时,碰到了notepad++中的ANSI编码,啊这是什么东西,之前怎么从来没有听说过。
经过查阅资料可知
ANSI 编码 :各个国家和地区独立制定的既兼容 ASCII 编码又彼此之间不兼容的字符编码,微软统称为 ANSI 编码。在 Windows 系统中,ANSI 编码一般代表系统默认的编码方式,并且不是确定的某一种特定编码方式,比如在英文 Windows 操作系统中,ANSI 指的是 ISO-8859-1;简体中文操作系统中 ANSI 编码默认指的是 GB 系列编码(GB2312、GBK、GB18030)等;在繁体中文操作系统中 ANSI 编码默认指的是 BIG5;在日文操作系统中 ANSI 编码默认指的是 Shift JIS 等等,并且默认的 ANSI 编码可以通过设置系统 Locale 更改[8]
由于我的windows版本为简体中文,所以ANSI编码默认为GBK(在命令行下执行chcp命令可以查看当前code page的值,我的code page是936,表示GBK编码),你可能会问,如何更改系统默认编码呢?
Windows下code page是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置...”):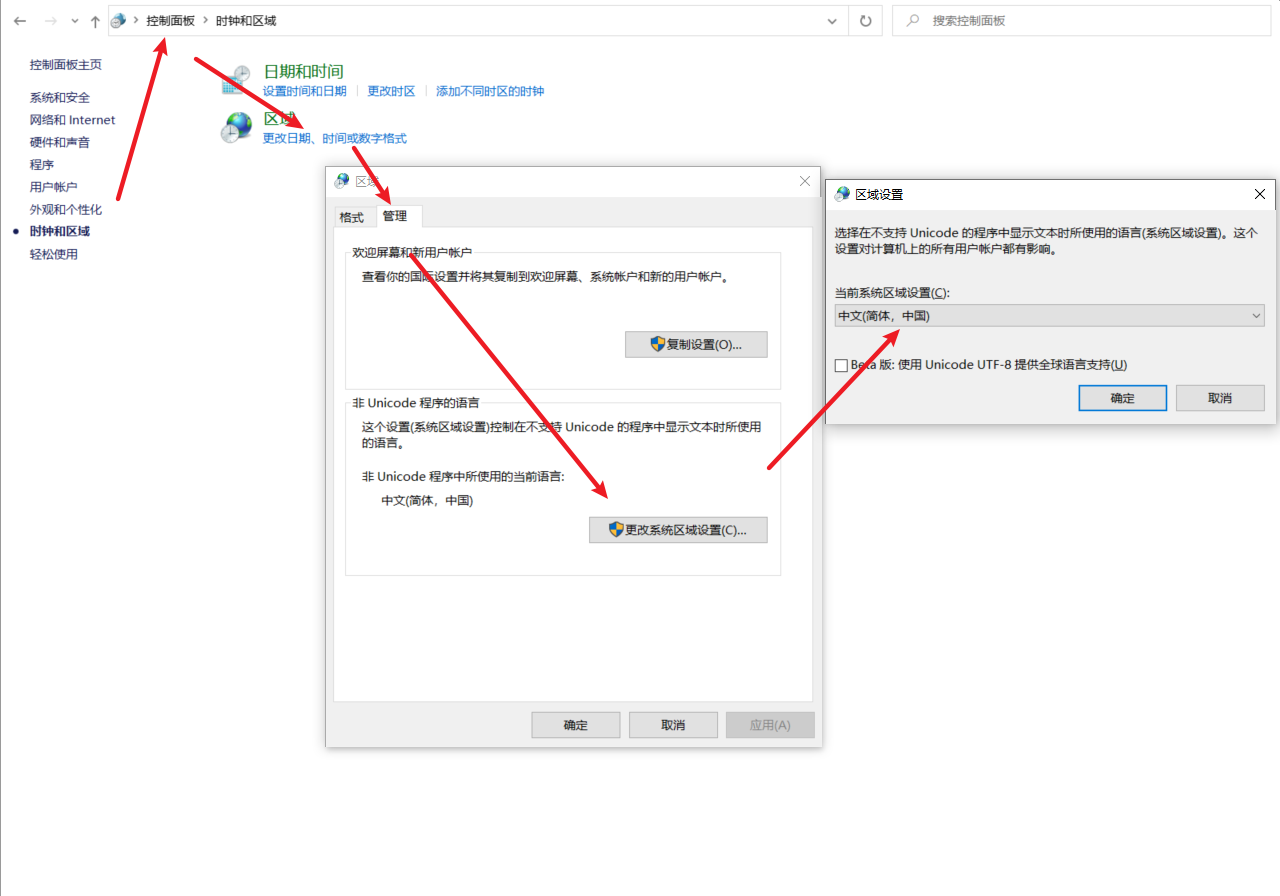
-
“严”的utf-8编码

-
“严”的utf-8 bom编码,可见前面多了ef bb bf三个字节。

-
“严”的usc-2 little endian,由于是小端,故BOM为ff fe

-
“严”的usc-2 big endian,由于是大端,故BOM为ff fe

-
“严”的ANSI编码(GBK编码)

观察“严”的各种编码方式均符合预期,经过实验得到notepad++中使用xxx编码和转为xxx编码的区别:
-
使用xxx编码
-
对于新输入的字符,采用xxx编码
-
对于原本存在的字符,不更改其存储设备的字节值,显示时解码方式变为xxx编码,比如“严”在utf-8编码中的值为0xe4 b8 a5,点击使用ANSI编码时,其显示变为下图“涓xA5”,因为0xe4 b8用GBK解码后为“涓”,还有一个字节无法解码(GBK解码单位为两字节),因此显示“xA5”。

需要注意的是,当使用xxx带BOM的编码时,此时也会更改存储设备的值,因为要在文件头加上BOM标记,但是不更改字符对应的存储设备上的字节值,只是在前面增加BOM罢了。
-
-
转为xxx编码
转为xxx编码会更改存储设备上的值,将字符编码为xxx编码对应的字节序列。比如“严”在utf-8编码中的值为0xe4 b8 a5,点击转为ANSI编码时,其显示仍为“严”

当用hex-editor查看时,发现其字节序列发生变化,变为了严的GBK编码值“0xd1 cf"。

因此当我们遇到乱码,转换编码时应使用notepad++的转为xxx编码。
乱码产生原因概述[8]
讨论完了各种编码,现在我们要来用理论分析问题,看看乱码到底怎么回事。
编码引起的乱码、解码引起的乱码以及缺少某种字体库引起的乱码(这种情况需要用户安装对应的字体库),其中大部分乱码问题是由不合适的解码方式造成的。
下面通过几个常见例子,从普通用户角度分别阐述这几种原因导致的乱码表象和解决办法。
编码引起的乱码表象分析
在英文版 windows 系统(实验使用的是 win7 64 位专业版),新建一个 txt 文件,写上”你好”保存。然后再双击打开,将会看到保存的内容变成了”??”,如下图所示
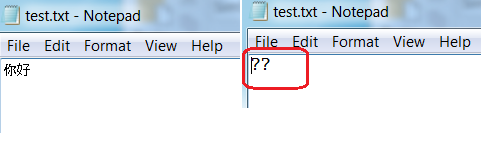
原因分析: Windows 默认选用 ANSI 编码,英文版 Windows7 默认的系统 Locale 是 English(United States),对应的 codepage 为 437 即编码方式为 ISO-8859-1。我们用十六进制查看器可以看到”你好”对应的的十六进制数为”3F3F”,这是因为中文和中文符号经过不支持中文的 ISO-8859-1 编码时,将不在字符集范围内的字符统一用 3F 表示,3F 对应的字符为问号”?”,如下图所示。

解决办法: 这种情况下形成的乱码是不可逆的,也就是说无论用什么解码方式都不能正确显示字符。我们在保存双字节字符的文档时,选择正确的编码方式,比如简中可以选择 GB2312 或者 UTF-8;繁中字符可以选择 BIG5 或者 UTF-8 等;如果安装的是英文操作系统,对于中文用户,可以将系统 Locale 更改为 Chinese(Simplified, PRC)。
解码引起的乱码表象分析
在中文版 Windows 系统创建一个 txt 文件,写上”你好,中国”然后保存,再将这个 txt 文件复制到英文版 Windows 系统,双击打开,将会看到保存的内容变成”ÄãºÃ£¬Öйú”。
原因分析: 中文版 Windows 系统创建的 txt 文件以默认的 ANSI 编码即 GB2312,当复制到英文版 Windows 系统时,Notepad 默认的解码方式为 ISO-8859-1,如下图所示的表象分析。这种情况下产生的乱码是可逆的,只要使用正确的解码方式,就可以正确显示文件中的字符。
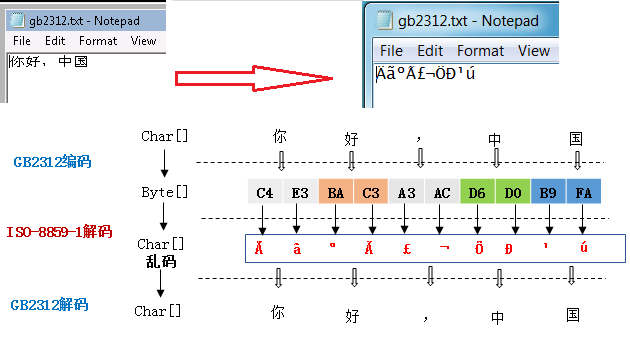
解决办法: 遇到类似解码问题引起的乱码,可以换一个编辑器打开,同时选择正确的解码方式。
下面的例子是在英文版 Windows 系统上打开中文版 uedit32.exe 后菜单项全为乱码的现象,如下图所示。
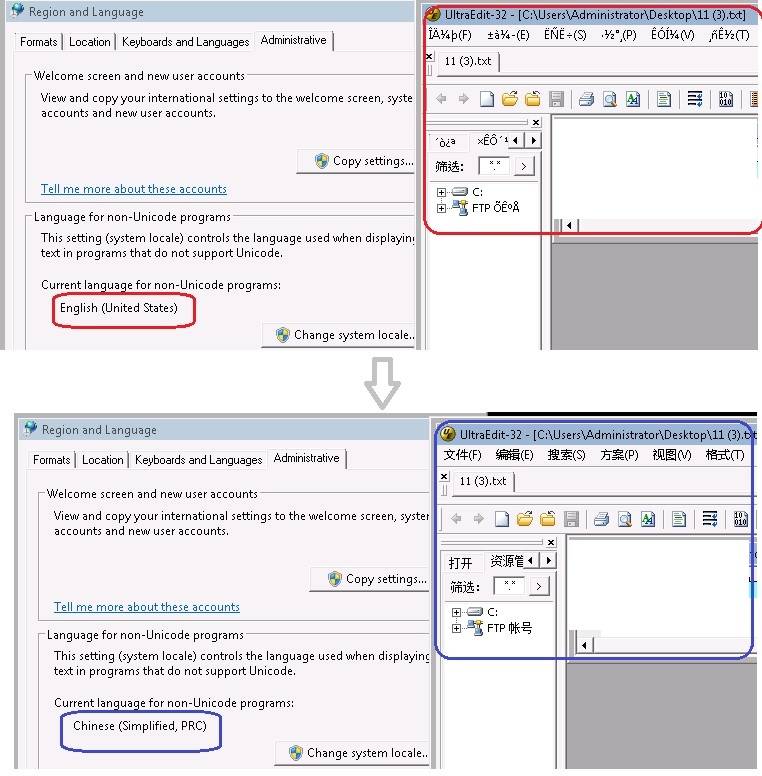
原因分析: 对于支持 Unicode 的应用程序,Windows 会默认使用 Unicode 编码。对于不支持 Unicode 的应用程序 Windows 会采用 ANSI 编码 (也就是各个国家自己制定的标准编码方式,如对于西欧文字有 ISO/IEC 8859 编码,对于简体中文有 GB2312,对于繁体中文有 BIG-5 等。Uedit32 是不支持 Unicode 的,然后当前实验使用的英文版 Windows 7 默认的 locale 为英语(美国),其默认字符集是 ISO-8859-1,而中文版 uedit32 程序使用的是中文编码方式,使用 ISO-8859-1 解码时肯定出现乱码情况。这个例子的乱码根本原因也是不正确的解码方式造成的。
解决办法 :进入系统的控制面板,找到 Regional and Language Options 语言设置项,打开进入对应的页面,将标准与格式中的语言设置为简体中文;同时在 Advanced 标签页中将系统支持的非 Unicode 语言也设置为简体中文,从而在解码的时候就会使用中文自己的 ANSI 编码(实验环境为 GB1832)。
缺少字体引起的乱码表象分析
在英文 Windows 系统打开一个文件发现里面的内容有些显示为方框,如下图所示。

原因分析: 这个例子中显示为方框的都是中文字符。我们看到屏幕上的字符实际上经历了三种不同形态,从 二进制字节序列 转换成对应字符集中的 码点 ,然后码点通过查找字体库找到对应的 字符 ,最后通过点阵的方式显示在屏幕上。这里的方框是因为所查找的字体库缺少该码点对应的字符,或者根本没有安装该字体库,从而字符库中找不到的字符都以方框代替。
解决办法: 安装对应的字体库,比如 Windows 系统在 C:\Windows\Fonts 目录下会有安装好的字体库列表。安装字体库比较简单,下载后解压,然后复制到对应系统的 Fonts 目录下。这里有个问题就是如何知道缺少何种字体?有些阅读器比如 Adobe 在打开文档时会提示缺少什么字体,但是很多编辑器或者阅读器是不提示的,这个时候可能需要根据经验来判断。
从编程角度看乱码问题
怕什么真理无穷,进一寸有一寸的欢喜
走到这里,其实已经接近了文章尾声,但不得不给读者浇盆冷水,现实世界过于复杂,比如Python的乱码问题就值得再写一篇万字文章才可以说清,我们现在学到的编码只是不过是看懂乱码问题解决方案的敲门砖罢了,但还好下次阅读这些技术博客我们有了思考和辨别真伪的能力,也可以直接从博客中间开始阅读,省去了阅读前面阐述编码*础知识的时间😃。
经思考,笔者在写这一节时发现编程中出现的乱码问题极其复杂,真的值得好好说一说,但本文已接近万字,故决定另起一篇博客,敬请期待!
参考资料
[1] 阮一峰:《字符编码笔记:ASCII,Unicode 和 UTF-8》
[2] 简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系
[4] 关于字符编码,你所要知道的
[6] Wiki UTF-16
[7] 阮一峰:《Unicode与JavaScript详解》
[9] 博客园:ANSI是什么编码
[10] 百度百科ISO-8859-1
[11] 知乎问题:Python编码为什么那么蛋疼
[12] Wiki:现代编码模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号