(8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html
在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能在经过数据筛选,然后异步的使用文件下载类来达到目的,Scrapy框架中本身已经实现了文件及图片下载的文件,相当的方便,只要几行代码,就可以轻松的搞定下载。下面我将演示如何使用scrapy下载豆瓣的相册首页内容。
优点介绍:
1)自动去重
2)异步操作,不会阻塞
3)可以生成指定尺寸的缩略图
4)计算过期时间
5)格式转化
编码过程:
一,定义Item
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy import Item,Field class DoubanImgsItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_urls = Field() images = Field() image_paths = Field() pass
二,定义spider
#coding=utf-8 from scrapy.spiders import Spider import re from douban_imgs.items import DoubanImgsItem from scrapy.http.request import Request # please pay attention to the encoding of info,otherwise raise error import sys reload(sys) sys.setdefaultencoding('utf8') class download_douban(Spider): name = 'download_douban' def __init__(self, url='152686895', *args, **kwargs): self.allowed_domains = ['douban.com'] self.start_urls = [ 'http://www.douban.com/photos/album/%s/' %(url) ] #call the father base function self.url = url super(download_douban, self).__init__(*args, **kwargs) def parse(self, response): """ :type response: response infomation """ list_imgs = response.xpath('//div[@class="photolst clearfix"]//img/@src').extract() if list_imgs: item = DoubanImgsItem() item['image_urls'] = list_imgs yield item
三,定义piepline
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem from scrapy import Request from scrapy import log class DoubanImgsPipeline(object): def process_item(self, item, spider): return item class DoubanImgDownloadPieline(ImagesPipeline): def get_media_requests(self,item,info): for image_url in item['image_urls']: yield Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") item['image_paths'] = image_paths return item
四,定义setting.py,启用item处理器
# Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'douban_imgs.pipelines.DoubanImgDownloadPieline': 300, } IMAGES_STORE='C:\\doubanimgs' IMAGES_EXPIRES = 90
运行效果:
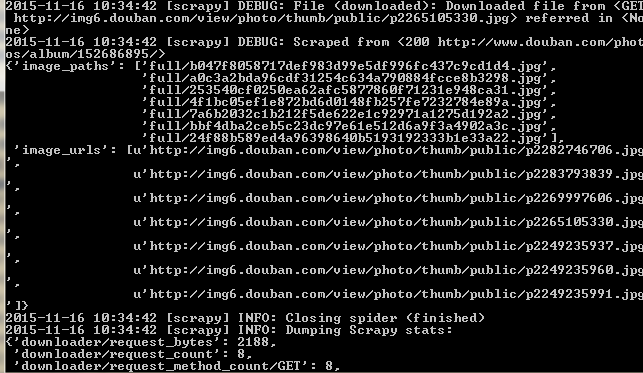
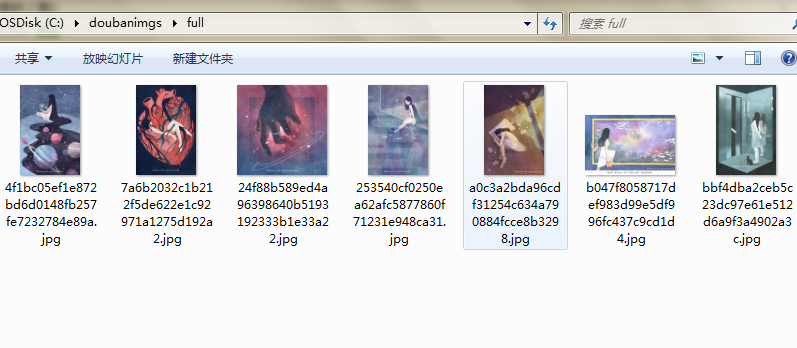
github地址:https://github.com/BruceDone/scrapy_demo
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html
如果scrapy或者爬虫系列对你有帮助,请推荐一下,我后续会更新更多的爬虫系列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号