
python爬取腾讯视频评论
使用python selenium爬取腾讯视频评论
代码速递:
from lxml import etree
from selenium import webdriver
import json
# cursor url_1 url_2 page 用来组合成最终的url,由于不同评论页参数不同,所以将其单独拿出来
cursor=0
url_1 ="https://coral.qq.com/article/7020779138/comment/v2?callback=_article7020779138commentv2&orinum=10&oriorder=o&pageflag=1&cursor="
url_2 = "&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&_="
page = 1626362497912
# 用于xpath定位元素
text_xpath = '/html/body/pre/text()'
# webdriver配置
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
driver = webdriver.Chrome('chromedriver.exe',options=options)
# 在项目下新建一个res.txt文件用于存储结果
file_handle=open('res.txt',mode='w',encoding='utf-8')
i = 0
# 爬取100页评论
for t in range(100):
print(url_1+str(cursor)+url_2+str(page+t))
# url_1+str(cursor)+url_2+str(page+t)是最终路径
driver.get(url_1+str(cursor)+url_2+str(page+t))
# 获取源代码,并解析
html = etree.HTML(driver.page_source)
text = html.xpath(text_xpath)
print(text[0][28:-1])
# 转换成json对象
res = json.loads(text[0][28:-1])
print(res['data'])
# 修改cursor参数,用于下一页请求
cursor = res['data']['last']
print(cursor)
# 打印评论,并将评论写入文件
for comment in res['data']['oriCommList']:
print('评论'+str(i)+':'+comment['content'])
file_handle.write(str(i)+':'+comment['content']+'\n')
i=i+1
所需依赖
- webdriver:用于模拟浏览器请求网页,需要安装chrome和对应的chromedriver.exe,两个版本需要一致,chromedriver.exe需要与上面的py程序放在同一个文件夹下
- xpath:用于解析和定位元素
- json:用于将字符串解析成json对象,便于查找元素的属性值
示例说明
爬取思路
腾讯视频的评论使用的是ajax异步请求获取评论,所以直接爬取url下的源代码无法获得评论,即便有,也只有部分评论
在查询几篇前人的总结后,决定使用Fiddler抓取https请求
通过fiddler发现video.coral.qq.com下的https请求存在我们所需要找的评论信息
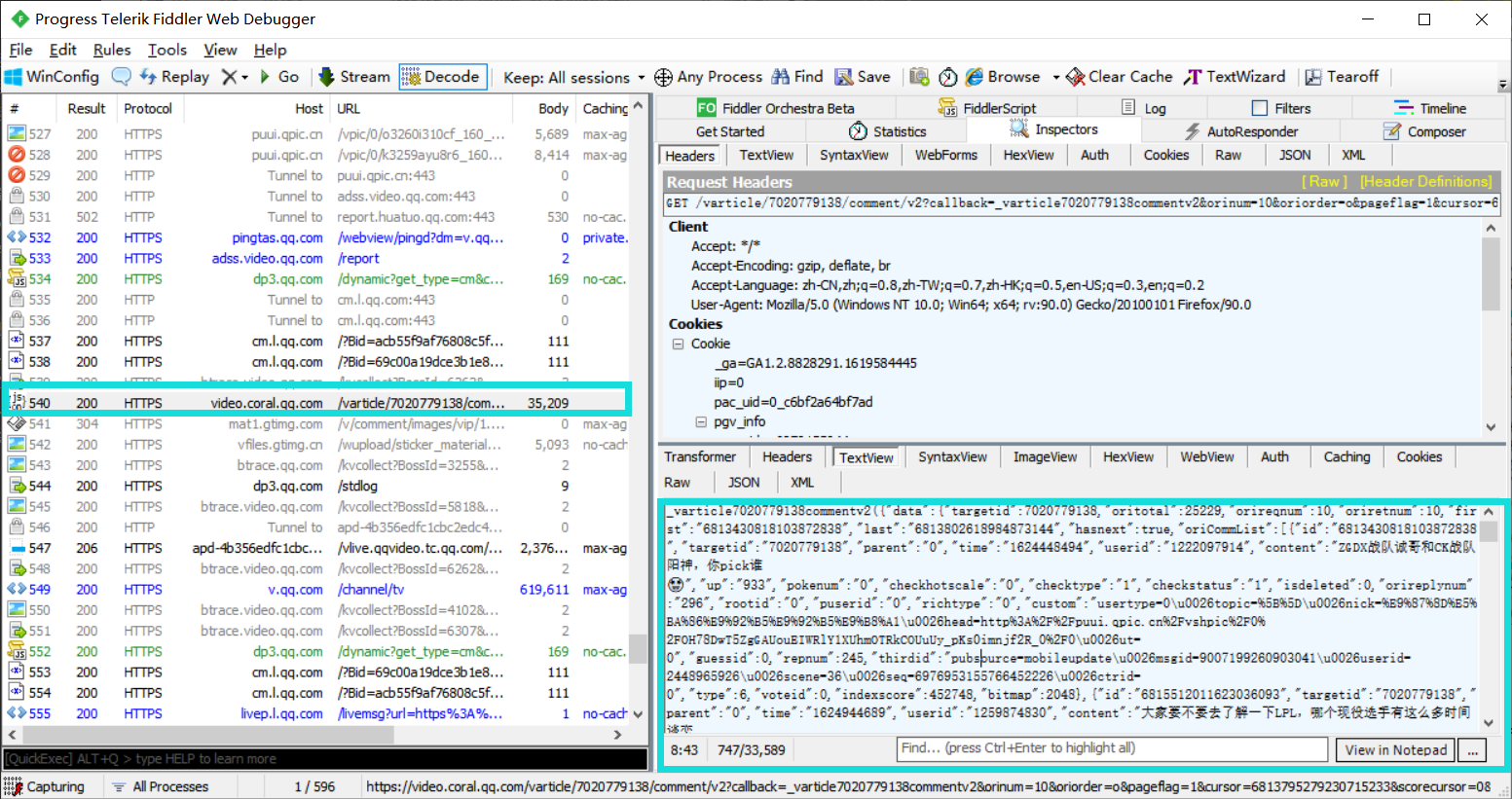
查找几个类似请求,观察其路径规则
- 1、https://video.coral.qq.com/varticle/7020779138/comment/v2?callback=varticle7020779138commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6813795279230715233&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&=1626414041931
- 2、https://video.coral.qq.com/varticle/7020779138/comment/v2?callback=varticle7020779138commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6813802618984873144&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&=1626414041932
观察后发现,两次请求cusor参数发生了变化,_参数后一个请求是前一个请求基础上再加1
通过解析请求中的数据后发现,后一个请求的cusor参数存储在前一个请求的last属性内
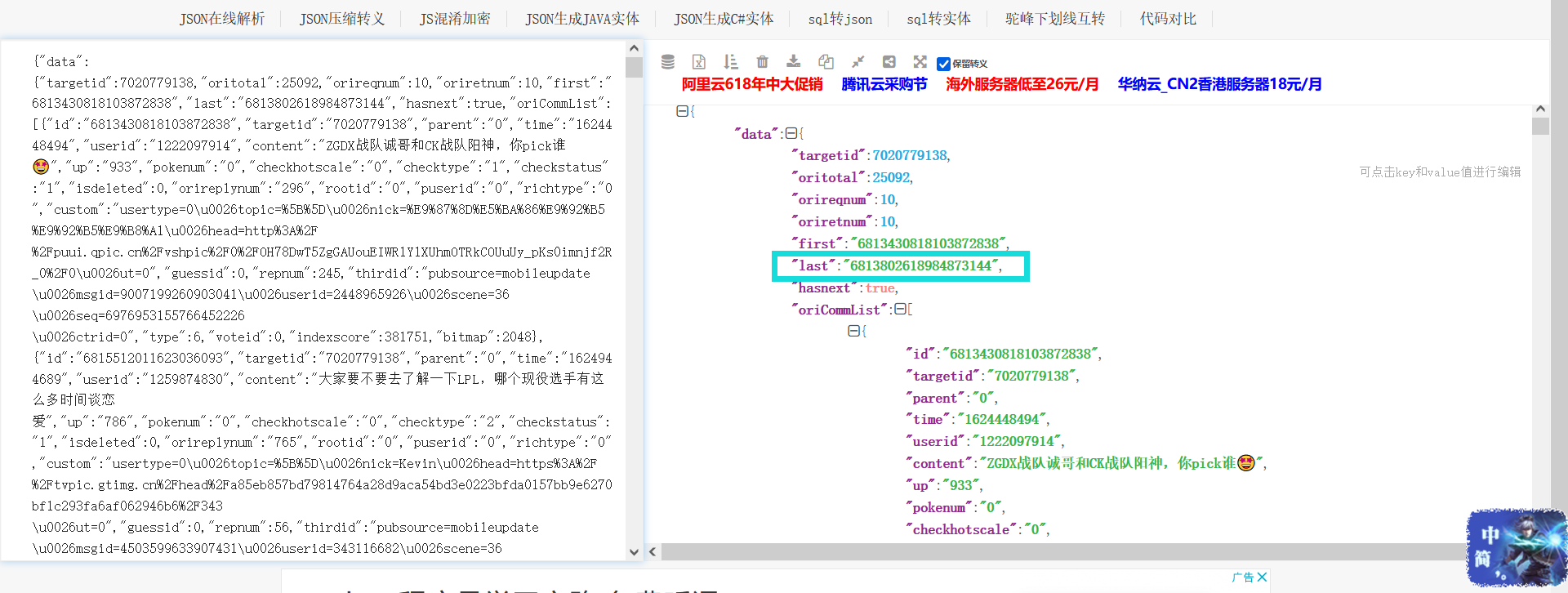
总结好规律后便可以开始编写代码,除第一次请求外,每次请求都需要获得last和content属性,last用于指向下一页评论地址,content内存储着用户评论,详细可见文章头部代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号