mysql索引测试——重复数据字段不宜作为索引字段
因为工作的项目涉及千万级数据的单表内容的统计查询。所以对于此sql的效率做了一个测试比较,并在测试过程中发现了索引相关的问题:
情况说明:
原始表单(记A表)为业务接口调用记录表,每个用户的每次调用接口都会产生一条记录。一天产生一张表,单表规模可能达到千万。
记录的信息包括用户(uuid),调用的接口(method),接口耗时时间(time_cost)等…,
要求:
统计出一天内(A表一天生成一张)A表中每个用户(uuid)的每个接口(method)对应的调用的次数及最大和最小消耗时间(max_cost,min_cost)。
另A表建有一个method列的简单索引
在未访问A表之前,只知道总共有哪些接口(接口总共10个左右),不知道存在哪些用户
思路:
1、 将uuid和function分组排列,一步到位直接出结果
2、 单独对每个接口只按uuid排列,总共多少接口统计多少次
单表数据:单表600w数据,1w个uuid随机,method 6个随机,time_cost 0~1000内随机
1、将uuid和function分组排列,一步到位直接出结果
select uuid, method, count(1) call_times,min(time_cost) min_cost,max(time_cost) max_cost from A_yyyymmdd group by uuid, method into outfile '/var/lib/mysql-files/a1.txt';

sql语句执行花费:11.51s
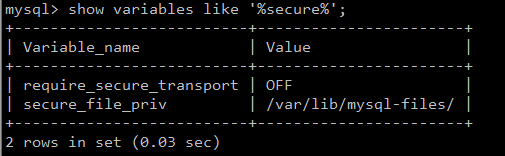
语句后面的 into outfile ‘/var/lib/mysql-files/a.txt’表示将语句执行结果导出到文件,具体导出的目录权限可通过mysql安全控制变量secure_file_priv查看
通过show variables like '%secure%'可查看:
2、单独对每个接口只按uuid排列,总共多少接口统计多少次
select uuid, count(1) call_times,min(time_cost) min_cost,max(time_cost) max_cost from A_yyyymmdd where method= ‘useradd’ group by uuid into outfile '/var/lib/mysql-files/a1.txt';

统计单个接口的花费:48.61s
对于此结果有点诧异,按照道理,group by 单列应该比group by 组合列效率更高
3、考虑是否where产生的影响,那么把where去掉看下,只观察语句执行效率。
select uuid, count(1) call_times,min(time_cost) min_cost,max(time_cost) max_cost from A_yyyymmdd group by uuid into outfile '/var/lib/mysql-files/a1.txt';

花费:5.20s
group by只消耗了5.20s,但总的却是21.09左右,也就是说在where子句的时候花费更多的事件。
4、留where子句,去掉group by观察语句执行效率:
select uuid from A_yyyymmdd where method= ‘useradd‘ into outfile '/var/lib/mysql-files/a1.txt';

耗时:45.5s
果然where子句消耗的时间太高。
5、查看where子句执行计划,看索引是否生效
explain select uuid from A_yyyymmdd where method= 'useradd' into outfile '/var/lib/mysql-files/a7.txt';

发现已经有用上索引,用上索引花费45s,有点疑惑,查看group by uuid的语句(花费5.2s)是否用上索引
explain select uuid, count(1) call_times,min(time_cost) min_cost,max(time_cost) max_cost from A_yyyymmdd group by uuid into outfile '/var/lib/mysql-files/a1.txt';

发现group by uuid的语句是全表扫描,没有使用索引,反而只需要花费5.2s。
用到索引的却要花费45.5s。
6、对where语句忽略索引,执行看看执行花费:
explain select uuid from A_yyyymmdd ignore index(aaa_method_call_times_record_method_IDX) where method= ‘useradd’ into outfile '/var/lib/mysql-files/a1.txt';

where语句不使用索引,全表扫描,执行语句:
select uuid from A_yyyymmdd ignore index(aaa_method_call_times_record_method_IDX) where method= 'useradd' into outfile '/var/lib/mysql-files/a1.txt';

耗时:3.69s
同样一个where语句 使用索引的45.5s,忽略索引的3.69s。
7、通过网上了解到这样结果是因为索引建立的不合适,涉及到数据库引擎的索引原理:
A表索引是建立在method上的,在此场景中,表中method数据存在大量重复的。
我默认数据库引擎是InnoDB
数据库中聚集索引只有一个,默认主键。其他用户创建的索引都是非聚集索引(二级索引)。非聚集索引存储了对主键的引用,即通过索引确定叶子节点之后,还需要再次根据主键去查询数据。(所以会查询两次)。如果非聚集索引重复率高(即一个同样的值有多个主键),那么条件会确定近乎一半或1/3,或1/5的主键值,然后在一个一个去聚集索引查询。这样开销会大,
如本次场景中数据:method 为6个随机,总共600w数据。
当method为索引时,每个method值对应约100w主键,
索引查询过程首先查询非聚集索引,从中查到约100w的主键引用,然后根据主键一个一个去聚集索引中查询数据,即查询聚集索引要查询约100w次。而全表扫描,只需一次扫描全部即可得出结果。此场景中索引的开销已经远远大于全表扫描的开销了。
如果索引后开销低于全表扫描,那么使用索引。如果索引导致了比全表扫描更糟糕的结果,那么还不如全表扫描。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号