
有了“结构定义良好”的二叉树,我们可以干很多事,我们可以创建具有特殊功能的二叉树,比如提供查找功能的二叉树,而且,对于一棵树,其结点的插入、删除等修改动作的完成是很高效的(但是实现起来未必方便......),二叉查找树就能为我们提供这样的功能,二叉查找树的定义是:如果一棵二叉树中的任意一个结点,该结点的左子树中的结点值总是不超过该结点的值,而其右子树中的任意结点的值都大于该结点的值,那么这可二叉树就是二叉查找树。如下图所示:
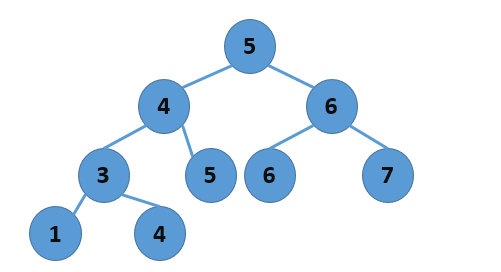
该树就是一棵二叉查找树,既然二叉查找树具有以上性质,那么,要查询一个结点就很方便了,如果该值大于树结点的值,就向右查询,反之,向左查询,这里给出递归查询算法描述:
search(root,value)
1、 if( root == null) return null; //没查找到
2、 if( root.value == value) return root;//查找到了
3、 if( root.value < value) return search(root.left,value); //查找左子树
4、 return search(root.right, value);//查找右子树
对于二叉查找树,它的查询路径是一条从根到目标结点的单一路径,即使使用递归,中间也没有“迂回”的路径,比如,我们要查询上图中的结点1,则其查询路径如下图:
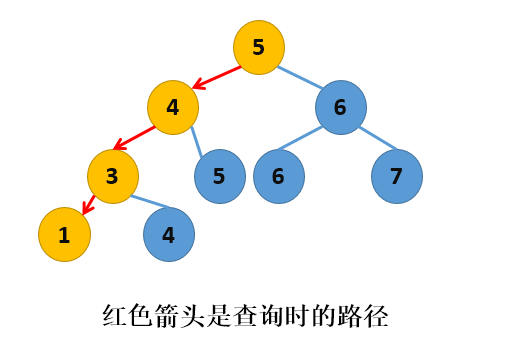
二叉查找树插入结点也很方便,也可以用递归的形式进行结点的插入,插入算法的描述如下:
insertNode(root,value)
1、 if( value>root.value )
2、 if( root.right ==null)
3、 root.right = new node( value);
4、 else insertNode(root.right,value);
5、 else
6、 if( root.left == null)
7、 root.left=new node( value);
8、 else insertNode (root.left, value);
二叉查找树的结点删除操作就不那么简单了,根据删除结点位置的不同,需要考虑以下三种情况,如下图所示:
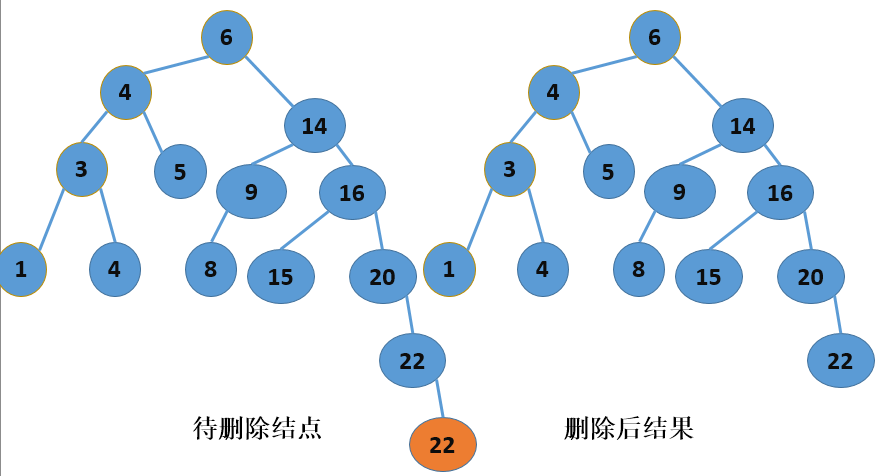
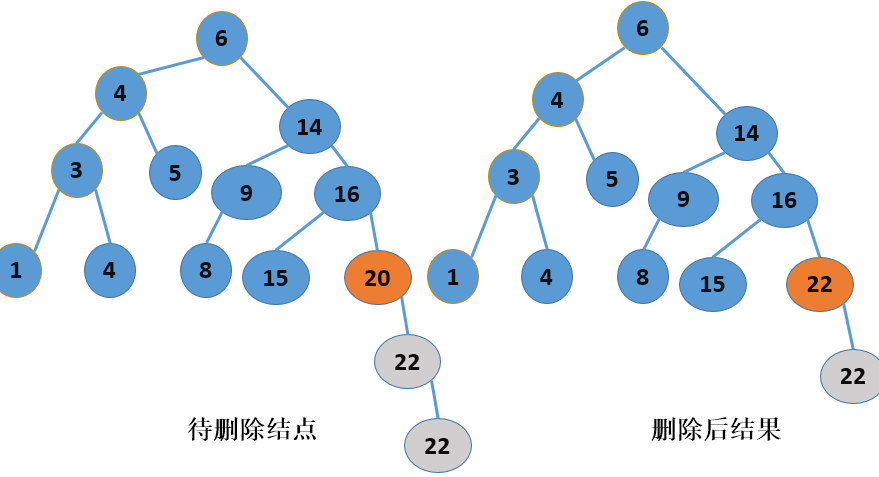
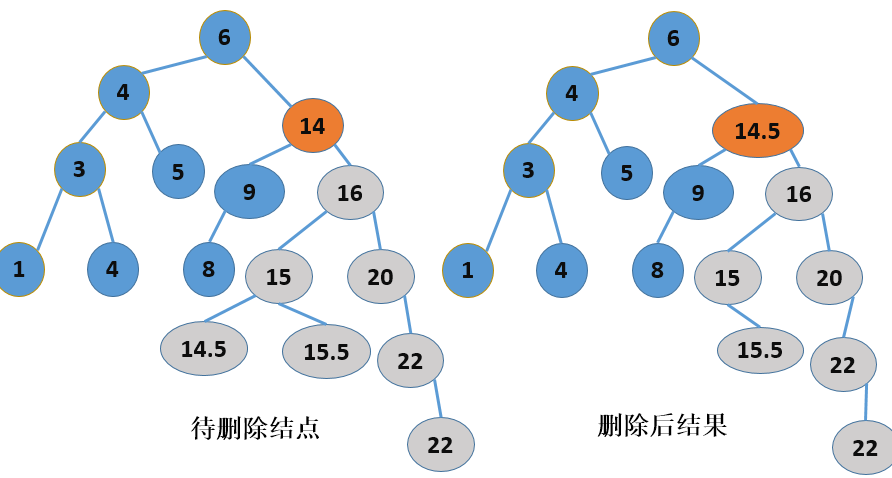
拉萨删除结点时,首先要判断结点所处的位置,这是最重要的,对于叶子结点,可以直接进行删除,而对于非叶子结点,其情况就稍微复杂了一点,但是,如果用语言进行描述的话,还是挺容易理解的,如果要删除一个非叶子结点,那么它的位置将由该结点的右子树中的最小值结点替换(也就是该结点的右子树中的“最左边”结点),而这个“最左边”结点(设为P)的位置将有P的右子树(如果有的话,没有就为空)替换(注意,P已经是最左端结点了,所以P不应该再有左孩子)。所以,删除结点的算法描述如下:
deleteNode(root,node)
1、if( node.left == null && node.right == null) //叶子结点
2、 node=null; //直接删除
3、else
4、 y=succsssor(node);//结点y是node中序遍历的后继,记住,是中序遍历结果的后继!!!也就是node的右子树的最“左边”的结点,该节点可能是非叶结点,但是,该结点一定没有左孩子。
5、 z=y.right; //用z记录y的右子树
6、 node_father=findFather(root,node); //找到node结点的父结点
7、 y_father = findFather(root,y); // 找到y结点的父结点
8、 y_father.left=z; //将y结点的右子树作为y父结点的左孩子
9、 node_father.left == node ? node_father.left = y : father.right = y;//如果node是node父结点的左孩子,则将y作为node父结点的左孩子,反之,将y作为node父结点的右孩子。
10、 y.left=node.left;//将node的左子树作为y的左子树
11、 y.right=node.right; //将node的右子树作为y的右子树
12、 node=null; //删除node结点
根据以上算法描述,可以得出如下实现代码:
class TreeNode{ public int value=-1; public TreeNode(int value){ this.value=value; } public TreeNode left=null; public TreeNode right=null; } public class BST{ public static void main(String[] args){ int[] array={5,3,2,4,5,7,6,32,54,65}; TreeNode root=createBinaryTree(array); System.out.println("先序遍历结果:"); preprint(root); System.out.println("\n先序遍历结果:"); midprint(root); //删除值为7的结点 System.out.println("\n\n删除结点值为7的结点"); root=deleteTreeNode(root,7); System.out.println("先序遍历结果:"); preprint(root); System.out.println(); System.out.println("中序遍历结果:"); midprint(root); } static TreeNode createBinaryTree(int[] array){ TreeNode root=new TreeNode(array[0]); for(int i=1;i<array.length;i++){ addTreeNode(root,array[i]); } return root; } static TreeNode deleteTreeNode(TreeNode root,int value){//删除结点值为value的结点 TreeNode node=findNode(root,value);//首先找到该结点 TreeNode nodeFather=null,leftSubTreeMax=null,rightSubTreeMin=null; TreeNode orignode=node;//待删除的结点 if(node!=null){//该结点存在 nodeFather=findFather(root,node); if(nodeFather==null){//说明该节点是该树的根节点 if(node.right!=null){//待删除的结点具有右子树,则将待删除的结点的右子树中的最小值作为根 rightSubTreeMin=findRightSubTreeMinValue(node.right); TreeNode father_rightSubTreeMin=findFather(root,rightSubTreeMin); if(father_rightSubTreeMin==node){//待删除的结点是根节点 rightSubTreeMin.left=node.left; }else{ father_rightSubTreeMin.left=rightSubTreeMin.right; rightSubTreeMin.left=node.left; rightSubTreeMin.right=node.right; } root=rightSubTreeMin; }else{//待删除的结点没有右子树,则需要将待删除的结点的左子树中的最大值作为根节点 leftSubTreeMax=findLeftSubTreeMaxValue(node.left); TreeNode father_leftSubTreeMax=findFather(root,leftSubTreeMax); leftSubTreeMax.left=node.left; leftSubTreeMax.right=node.right; father_leftSubTreeMax.right=null; root=leftSubTreeMax; } }else{//找到待删除结点的父结点,这里的变化比较复杂 //找到node结点的右子树中的最小值 rightSubTreeMin=findRightSubTreeMinValue(node.right); //rightSubTreeMin.right取代rightSubTreeMin的位置 //找到node结点的右子树中的最小值结点的父结点,并将该结点的右孩子作为该节点的父结点的左孩子 TreeNode father_rightSubTreeMin=findFather(root,rightSubTreeMin); //注意判断,如果被删除结点的右孩子没有左子树,这时候直接用被删除结点的右孩子取代该节点 if(father_rightSubTreeMin==node){ rightSubTreeMin.left=node.left; }else{ father_rightSubTreeMin.left=rightSubTreeMin.right; rightSubTreeMin.right=node.right; rightSubTreeMin.left=node.left; } if(nodeFather.left==node){ nodeFather.left=rightSubTreeMin; }else{ nodeFather.right=rightSubTreeMin; } } } orignode=null; return root; } static TreeNode findLeftSubTreeMaxValue(TreeNode root){//寻找左子树的最右边的叶子结点 if(root.right==null){ return root; }else{//左子树中的最大值肯定是在最“右边” return findLeftSubTreeMaxValue(root.right); } } static TreeNode findRightSubTreeMinValue(TreeNode root){//寻找右子树的最左边的叶子结点 if(root.left==null){ return root; }else{//右子树中的最小值肯定是在最“左边” return findRightSubTreeMinValue(root.left); } } static void addTreeNode(TreeNode root,int value){//添加结点 TreeNode temp=root; while(temp!=null){ if(temp.value<=value){//结点值小于新插入结点值 if(temp.right!=null){//判断是否已到叶子结点 temp=temp.right; }else{//如果已经到了叶子结点,讲该结点插到这个位置,同时停止循环 temp.right=new TreeNode(value); break; } }else{ if(temp.left!=null){ temp=temp.left; }else{ temp.left=new TreeNode(value); break; } } } } static TreeNode findFather(TreeNode root,TreeNode node){//寻找结点的父结点 if(root==node){//根节点,没有父结点,返回空 return null; } if(root.left==node || root.right==node){ return root; }else{ if(root.value<=node.value){ return findFather(root.right,node); }else{ return findFather(root.left,node); } } } static TreeNode findNode(TreeNode root,int value){//寻找值为value的结点,如果有多个,则返回第一个 if(root!=null && root.value==value){//寻找到该点 return root; } if(root==null){//没有找到该节点,返回空 return root; }else{ if(root.value<=value){ return findNode(root.right,value); }else{//这里左孩子的值全部小于等于父结点的值 return findNode(root.left,value); } } } static void preprint(TreeNode root){//先序遍历二叉树 if(root!=null){ System.out.print(root.value+" "); preprint(root.left); preprint(root.right); } } static void midprint(TreeNode root){//中序遍历二叉树 if(root!=null){ midprint(root.left); System.out.print(root.value+" "); midprint(root.right); } } }
地方撒发射点最后输出结果是:
先序遍历结果:
5 3 2 4 5 7 6 32 54 65
先序遍历结果:
2 3 4 5 5 6 7 32 54 65
删除结点值为7的结点
先序遍历结果:
5 3 2 4 5 32 6 54 65
中序遍历结果:
2 3 4 5 5 6 32 54 65
二叉查找树并非是一个最优的查找结构,因为有时候它可能转换成线性的,比如下图所示:
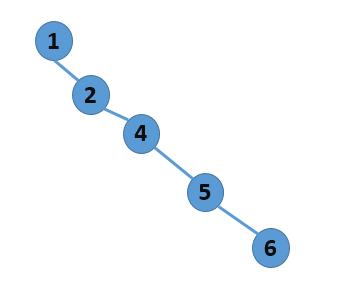
这时候查找就成了线性查找,因为二叉树的查找时间复杂度是O(h),也即和树的高度有关,故而再创建树的时候需要优化,使得树的高度尽可能地矮。红黑树就是一种很好的优化策略,它能保证对一个结点的查找时间为O(lgn) 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号