MySQL聚簇索引和非聚簇索引的对比
首先要清楚:聚簇索引并不是一种单独的索引类型,而是一种存储数据的方式。
聚簇索引在实际中用的很多,Innodb就是聚簇索引,Myisam 是非聚簇索引。
在之前我想插入一段关于innodb和myisam的数据文件的对比:
innodb一张表在硬盘上通过两个文件存储:tablename.frm,tablename.ibd,而myisam有三个文件:tablename.frm,tablename.myi,tablename.myd。
frm是表结构文件,myi是索引文件,myd是数据文件,ibd是数据+索引文件,得出的结论是:innodb的索引和数据存储在一起,而myisam是索引和数据分开存储的。
知道了这一点区别,下面的图片看起来才更加了然于心。
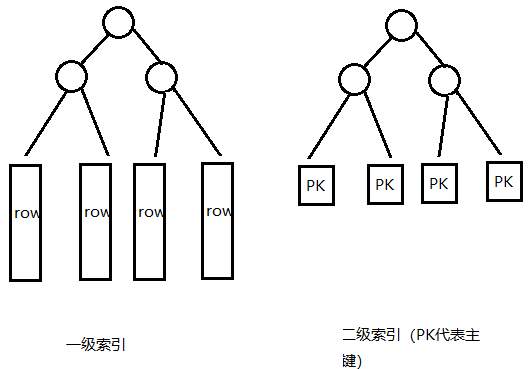
这里要补充一个知识点,什么是一级索引?什么是二级索引?
答:主键id索引叫一级索引,主键以外的索引叫二级索引。
上图中的一级索引就是本文说的聚簇索引,数据和索引绑定在一起叫聚簇(索引的叶子节点直接存储表数据)。
在查询中使用一级索引的时候,直接通过索引的叶子节点找到数据,如果使用二级索引,在内部会被拆分成两次查询,第一次查询到PK(主键id),
在拿主键id去一级索引查找。
下面是非聚簇索引:
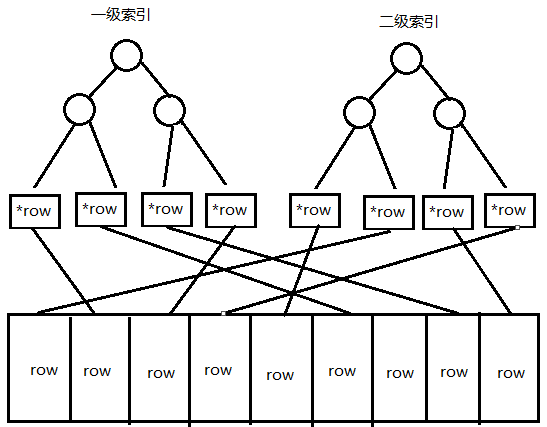
非聚簇索引中,一级索引和二级索引没有任何区别,叶子节点存储的是数据的指针,不是数据本身,这一点和聚簇索引是不一样的。
结论:上面两个图很清楚的反映了聚簇索引和非聚簇索引在存取逻辑上的差别,由于聚簇索引的索引和数据聚集在一起,所以查找的时候理论上要更快,
而非聚簇索引通过索引只能找到数据的地址,最终还要通过地址去找数据,所以理论上更慢一些。
聚簇索引中通常会按照自增id作为主键,这对高并发插入可能会有锁争情况,通过设置 innodb_autoinc_lock_mode来平衡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号