
yolov5 推理,获取 对象坐标 等数据
demo
import torch
import cv2
from PIL import Image
# pt_path = r'E:\Code\Python\YoLov5\yolov5\yolov5s.pt'
pt_path = r'E:\Code\Python\yolov5py38\yolov5\best.pt'
# Model
model = torch.hub.load(r"E:\Code\Python\YoLov5\yolov5",'custom', path=pt_path, source='local') # or yolov5n - yolov5x6, custom
# Images
img_path = r"E:\Code\Python\yolov5py38\dataset\dog_and_cat\images\val\119.jpg" # or file, Path, PIL, OpenCV, numpy, list
img_obj = Image.open(img_path)
# print(type(img_obj))
# Inference
results = model(img_obj)
# Results
# results.print()
s = results.crop(save=False) # or .show(), .save(), .crop(), .pandas(), etc.
for item in s:
# print(item)
im = item['im']
a = cv2.imencode(".jpg", im)
success, enc_img = cv2.imencode(".jpg", im)
print(success, enc_img)
print(type(success), type(enc_img))
img_data = enc_img.tobytes()
with open('output1.jpg', 'wb') as f:
f.write(img_data)
car_img = s[0]['im']
cv2.imshow('win', car_img)
# cv2.imwrite('output.jpg', car_img) # 保存图片
cv2.waitKey(0)
cv2.destroyAllWindows()
输出的s解释
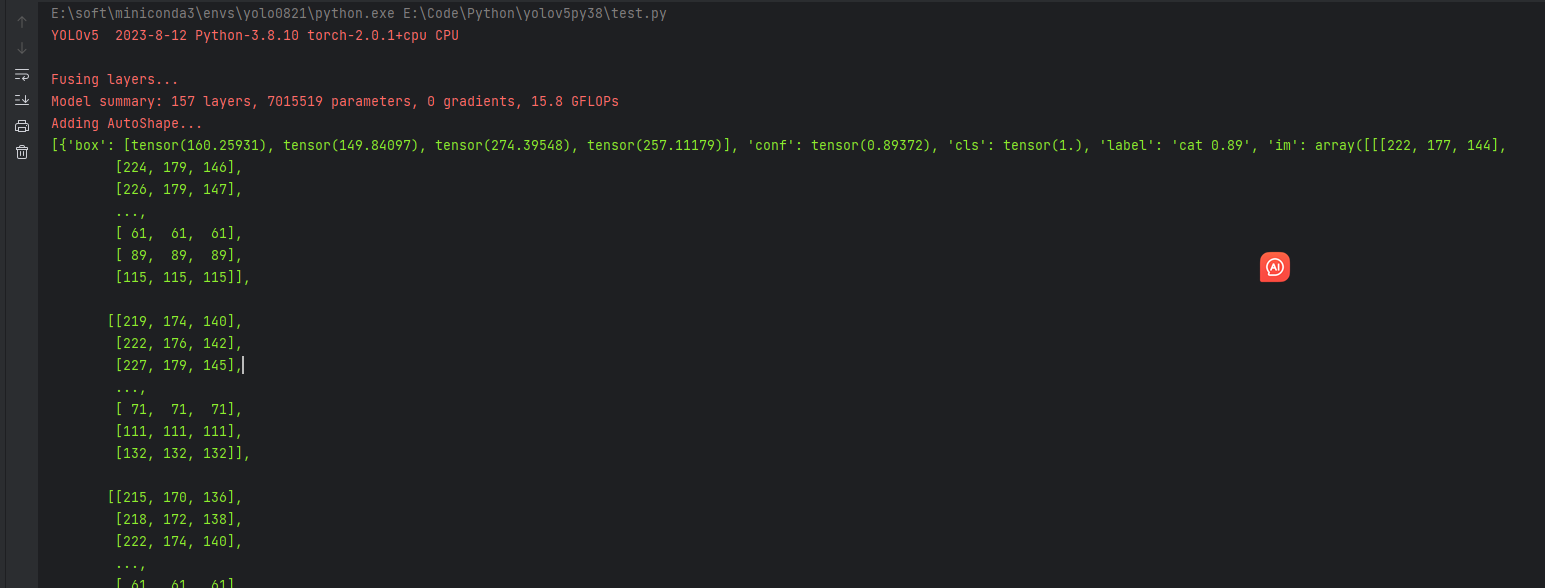
box: 这是一个表示检测到的目标边界框的信息。通常以坐标形式给出,表示目标在图像中的位置和大小。在你的例子中,这个目标边界框的左上角坐标为 (160.25931, 149.84097),右下角坐标为 (274.39548, 257.11179),这定义了一个矩形框出了检测到的目标。conf: 这是置信度或置信分数,表示模型对于这个检测结果的自信程度。在你的例子中,置信度为 0.89372,表示模型相当自信这个检测结果是正确的。cls: 这表示类别,通常是一个数字标识。在你的例子中,类别为 1.0。label: 这是目标的标签或类别的人类可读描述。在你的例子中,标签为 'cat 0.89',表示检测到的目标是猫,置信度为 0.89。im: 这个部分是一个图像数组,代表了检测结果所基于的原始图像。通常情况下,目标检测的结果会基于输入图像来定位和标识目标。
这段信息描述了模型在图像中检测到一只置信度为 0.89 的猫,并给出了该猫的边界框坐标以及其他相关信息
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17648876.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号