
python脚本打包exe程序与请求带session的区别
打包
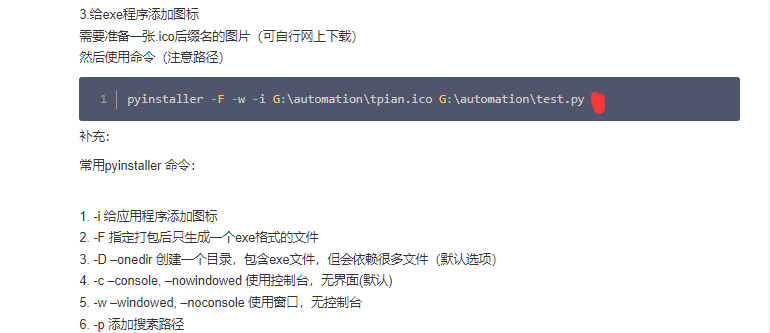
pyinstaller -F -i D:\ico\123.ico XXX.py --key 123456
or:pyinstaller -w -F -i D:\Tools\ico\blbl.ico play.py [无黑窗口]
or:pyinstaller -w -F -i ./blbl.ico play.py [无黑窗口]
or: pyinstaller -w -F -i ./qq.ico ./paimai_gui.py [无黑窗口]
or: pyinstaller -w -F -i ./bitbug_favicon.ico ./only_bizhon_gui.py --key dsadsa123155
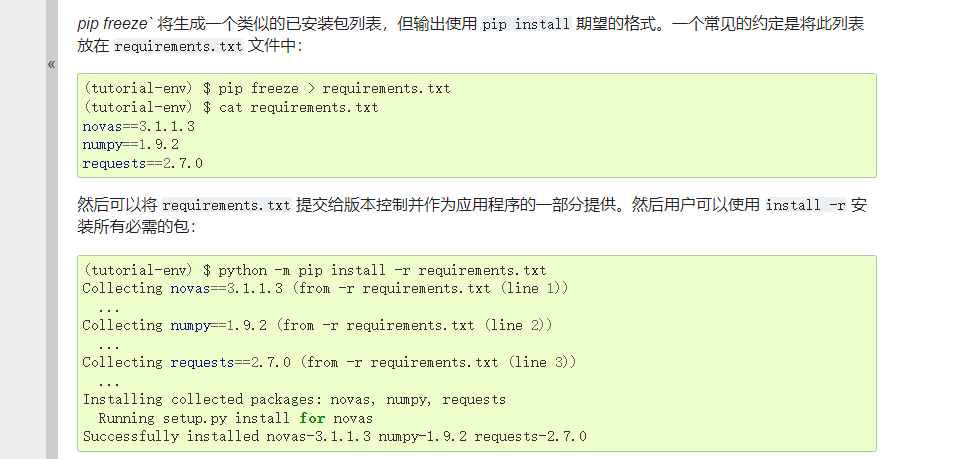
打包或安装虚拟环境库列表:
如何防止exe被反编译呢
只需在打包命令后面加上--key命令即可,例如文章开头的命令可以更换为:
pyinstaller -Fw --icon=h.ico auto_organize_gui.py --add-data="h.ico;/" --key 123456
123456是你用来加密的密钥,可以随意更换。
该加密参数依赖tinyaes,可以通过以下命令安装:
pip install tinyaes
使用session,与不带session对比
import requests
import pandas as pd
import re
from time import sleep
import os
os.environ['NO_PROXY'] = 'www.baidu.com'
def get_info(pages, session=None):
total_list = []
for page in range(1, pages + 1):
print("正在获取%d页" % page)
# for page in pages:
headers = {
'authority': 'go.drugbank.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'cookie': 'cf_clearance=z8jXLY4NjL4.KVOUbgZNPWj6NPBlT_u.x4xmS19uZZE-1682037487-0-250; _ga=GA1.1.1772772602.1682037506; _clck=qmfr9z|1|fay|0; _gcl_au=1.1.154779136.1682037508; ln_or=eyIyNDI4NDg0IjoiZCJ9; cf_chl_rc_i=3; __hstc=49600953.15b5c265b1847afab42a7def948ef734.1682037569169.1682037569169.1682037569169.1; hubspotutk=15b5c265b1847afab42a7def948ef734; __hssrc=1; __hssc=49600953.1.1682037569170; _omx_drug_bank_session=h5rNQehFjtC7SdQpb0HXfv7YA4pMfk2aMTWYUSzMaI7nF0SbDXVfqfqjVPMDQTs2hgXfMvwxMUByy%2BKdrPb40gDq3sAu%2BlSnJlbkcvWaBL7%2FIXcG6c2pOsEpbjbnGW8MV%2FkzX9dBeVriL%2F%2Fu%2FqTFEy3yXHyFPH38kRTSlMsmGlhgEh4CixxpIMBRiVUNeT7y6DeBVsL%2BNsjwWPFsiDVkWI7a3jOWuyeBxRDUZ9wUC8Opi%2FAiuvt2uVIehjQ2v4MNPGh%2FeyHirey%2FXQB34RHcTcb1fSRyNfDm4HEGYVzHI%2FkI%2BwIx8yHe24IlAFsEVVMW08bZrMA4b7Xf8G%2FLYLW2uRIr9qtlwELL7f07%2BoGtFMGnwylLzS97w0dEETEjdhyCogDlU65RZNcfbQMykTItXTWUBUskVMiNqDqDL%2BWU--uvjh%2BEo9E6nxj%2FdW--jEPCVVPyedUcF9oOBkYjpA%3D%3D; _ga_DDLJ7EEV9M=GS1.1.1682037506.1.1.1682037593.0.0.0; _clsk=1mtfaxl|1682037594214|5|1|u.clarity.ms/collect',
'pragma': 'no-cache',
'referer': 'https://go.xxxx',
'sec-ch-ua': '"Chromium";v="112", "Microsoft Edge";v="112", "Not:A-Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48',
}
params = {
'page': str(page),
'query': '*',
'searcher': 'indications'
}
response = session.get('https://go.xxxx',
headers=headers, params=params).text
try:
info1 = re.findall(r'href="/indications/.*?">(.*?)</a', response) # 第一列表
except Exception as e:
print(f"最大限度{page}页")
return
# print(info1)
# print(len(info1))
info2 = re.findall(r'<div class="db-matches"><a (.*?)</a></div>', response)
info2_new = [] # 第二列表
for i in info2:
i = i.replace('href="/drugs/', '').replace('">', ':').replace('</a>', '').replace('<a', '')
# print(i)
info2_new.append(i)
print(len(info1), info1)
print(len(info2_new), info2_new)
# 写入excel中
for yaoming, chenfen in zip(info1, info2_new):
dic = {
"药名": yaoming,
"成分": chenfen
}
total_list.append(dic)
pf = pd.DataFrame(total_list) # 转列表为DataFrame
path = pd.ExcelWriter(f'test.xlsx') # 设置保存路径
pf.to_excel(path, encoding='utf-8', index=False) # 转化为Excel
path.save() # 保存
# -----------
with open('记录.text', 'a', encoding='utf-8') as f:
f.write(f'{len(info1), info1}\n{len(info2_new), info2_new}\n')
sleep(1.5)
def starta():
title = 'Displaying indications开始启动'
width = 140
print('#' * width)
print('##', " " * (width - 6), '##')
print('##', " " * (width - 6), '##')
print('##', title.center(width - len(title) * 2 + 4), '##')
print('##', " " * (width - 6), '##')
print('##', " " * (width - 6), '##')
print('#' * width)
def ends():
print("爬取完成")
def main():
session = requests.Session()
while True:
starta()
yeshu = int(input('一共获取页数:'))
get_info(pages=yeshu, session=session)
ends()
# sleep(3)
# os.system('cls')
if __name__ == '__main__':
main()
场景如下:
session对象和requests两种方法发送的请求的区别:
1、场景
登陆某商城
查询我的订单数据
2、业务代码分析
首先这里涉及到两个接口,一个“登陆接口”,另外一个是“查询订单”的接口。
常规操作是我们 通过调用登陆接口 来获取响应的 cookie信息。
然后拿这个 cookie信息作为下一次请求的参数(cookie带有当前登陆人的信息)来请求 查询订单的接口
常规代码:
# 以下代码纯为了举例,没有效果的伪代码
import requests
# 登陆接口
response1 = requests.get(url_login,params,headers)
# 获取cookies信息
cookies = response.cookies
# 得到的cookies 是一个字典类型
cookie = cookies.get("cookies的key")
# 请求 查询接口
response2 = requests.get(search_url,params,headers,cookies=cookie)
# 查看查询响应的结果
response2.json()
使用session后:
# 以下代码纯为了举例,没有效果的伪代码
import requests
# 获取 session对象
session = requests.Session()
# 登陆接口
response1 = session.get(url_login,params,headers)
# 请求 查询接口
response2 = session.get(search_url,params,headers)
# 查看查询响应的结果
response2.json()
- 通过代码的对比可发现使用session对象效率会更好,不用每次都将cookie信息放到请求内容中了
- session对象能够自动获取到cookie并且可以在下一次请求红自动带上我们所得到的的cookie信息,不用人为的去填写
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17339969.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号