
77**招聘,**boss 仅供参考,切勿违法犯罪!
写了一份脚本,(*联)可获取链接 自动投递(playwright或者selenium)
仅供学习使用,切勿违法犯罪
效果图:boss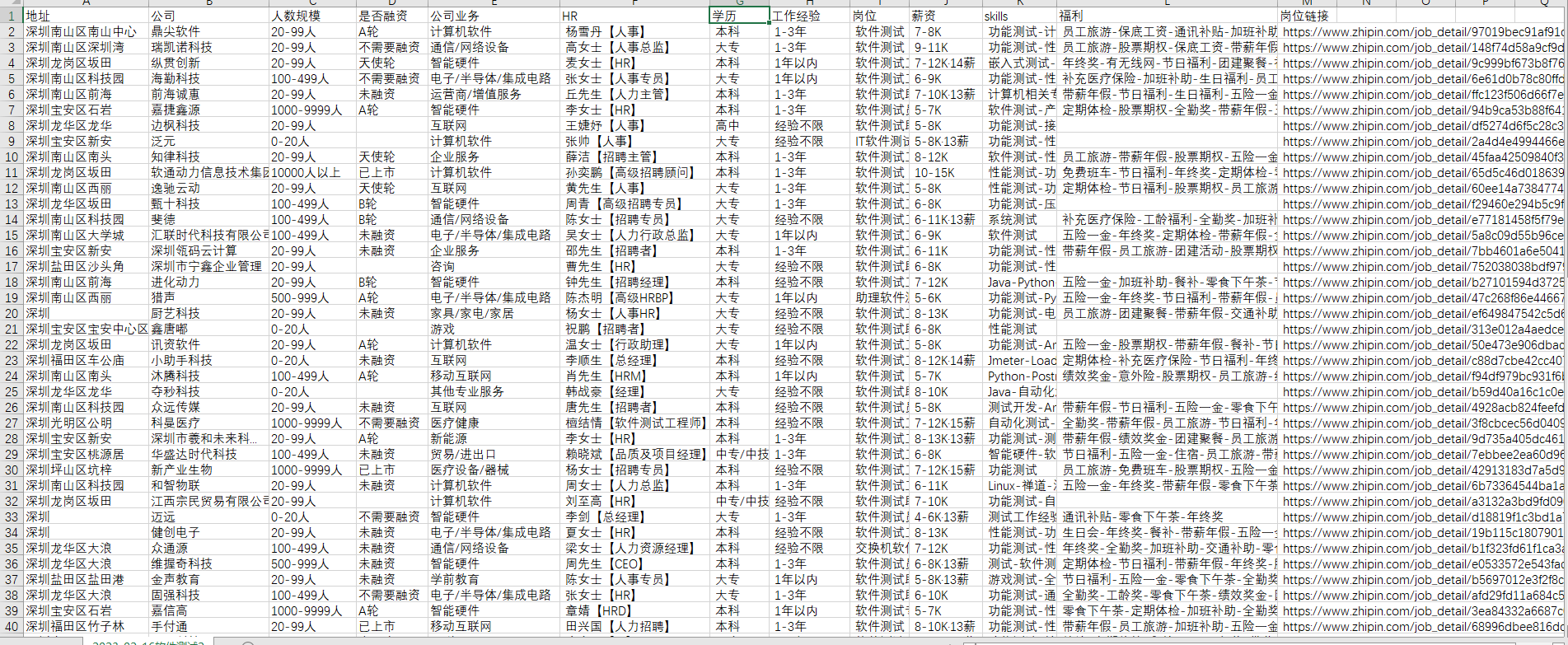
联*
Boss* 1.反爬真的有一手,cookie失效很快,里面还携带其它加密,大概一分钟不到就失效一次
# coding=gbk
# -*- coding:uft-8 -*-
# @Time: 2023/2/15
# @Author: 十架bgm
# @FileName: boss_sc
import random
import datetime
import requests
import re
import os, sys, io
import csv
import json
from time import sleep
os.environ['NO_PROXY'] = 'https://cc-api.sbaliyun.com/v1/completions'
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码
def get_info(url, f, cookie):
for page in range(1, 11):
print(f"正在爬取第{page}页")
headers = {
'cookie': cookie,
'referer': 'https://www.zhipin.com/web/geek/job?query=%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95&city=101280600',
'token': 'IPkgR64CGhBBSxmc',
'traceid': '942EDE43-58A7-4610-B2CF-7AB30BD6EF20',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
'zp_token': 'V1RN4uEuf03VtpVtRvyBscLy6w7j3UxS4~'
}
params = {
'scene': '1',
'query': 'XXXX', # 你需要爬取的岗位
'city': '101280600', # 深圳
'experience': '',
'degree': '',
'industry': '',
'scale': '',
'stage': '',
'position': '',
'jobType': '',
'salary': '',
'multiBusinessDistrict': '',
'multiSubway': '',
'page': str(page),
'pageSize': '30'
}
try:
info = requests.get(url=url, headers=headers, params=params, timeout=10).json()
# if 'brandName' not in info:
# print(f"已爬取最大页数{page - 1}!!")
# break
# print(info['zpData']['jobList'])
datasLs = info['zpData']['jobList']
for data in datasLs:
loc = data['cityName'] + data['areaDistrict'] + data['businessDistrict'] # 位置
compans = data['brandName'] # 公司名称
ren_shu = data['brandScaleName'] # 公司人数
yn_rongzi = data['brandStageName'] # 是否融资
ye_wu = data['brandIndustry'] # 公司做什么的 业务
name = f"{data['bossName']}【{data['bossTitle']}】" # hr名字和职位
xue_li = data['jobDegree'] # 学历
jin_yan = data['jobExperience'] # 工作经验
gang_wei = data['jobName'] # 岗位
salary = data['salaryDesc'] # 薪资
skill = '-'.join(data['skills']) # 主要做什么的 # 保存csv切勿以逗号拼接
welfare = '-'.join(data['welfareList']) # 公司福利
urll = f'https://www.zhipin.com/job_detail/{data["encryptJobId"]}.html?lid={data["lid"]}&securityId={data["securityId"]}&sessionId=' # 岗位url
print(loc, compans, ren_shu, yn_rongzi, ye_wu, name, xue_li, jin_yan, gang_wei, salary, skill, welfare, urll)
f.write(f"{loc},{compans},{ren_shu},{yn_rongzi},{ye_wu}, {name}, {xue_li}, {jin_yan}, {gang_wei}, {salary}, {skill}, {welfare}, {urll}\n")
sleep(random.randint(3, 5))
except Exception:
print('cookie失效!!!')
def main():
today = str(datetime.datetime.today()).split(' ')[0]
with open(f'{today}软件测试1.csv', 'a', encoding='ANSI', newline='') as f:
header = ['地址', '公司', '人数规模', '是否融资', '公司业务', 'HR', '学历', '工作经验', '岗位', '薪资',
'skills', '福利', '岗位链接'] # 列头名字
writer = csv.writer(f)
writer.writerow(header) # 设置列头名字
url = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json??'
ck = 'lastCity=101210100; wd_guid=32a125c4-3d2c-4a4e-b797-4593ee0d969c; historyState=state; _bl_uid=p7l9Rb79hk4obpx3LcLqwRFossLt; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1675484628,1675735399,1675938894,1676160836; wt2=DO8hIFBPJt_uK3rGpRvQFAaCwibP3yUyf6N7wmC8fFlMdihC0foHQ2bxGCpJUb4DjsLUKVXLSIsDfxuBf0dbqwA~~; wbg=0; collection_pop_window=1; __zp_seo_uuid__=53ade091-c01b-46bb-999a-fce2b82c2484; __g=-; __zp_stoken__=9d52eEDNHPFJAf1Q8cARVFmcxMEpeKVdrenxsXh1mfzd4MzATfmpedwYAZTkeYhc1AntSFk0vN0RmVzoAFwYnIAlkPiRcexY6eAsWTzJoDS42HAIiO1BdH3JzUzAjMCtqQEJgdz9bXU1aTT4%3D; __c=1676462610; __l=r=https%3A%2F%2Fwww.google.com%2F&l=%2Fwww.zhipin.com%2Fweb%2Fgeek%2Fjob%3Fquery%3D%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD%26city%3D101280600%26page%3D10&s=3&friend_source=0&s=3&friend_source=0; __a=47561692.1670661809.1676259245.1676462610.66.13.20.31; geek_zp_token=V1RN4uEuf03VtpVtRvyBscLiu57jLTzC8~'
get_info(url, f, cookie=ck)
print('爬取完成!')
# 'href="/job_detail/97019bec91af91d31XJ929m-FFBR.html?lid=24WJNiYGcV2.search.1&securityId=ea_Sw5Y5IEeKd-i1qj8gC2frUPVEM0KtcVHlcZNGSn3YxDHLWEOJbO0m-SWlMK7_Wsir-aP6XwWztMzOoDcjiDUGHcR-u_EvX0K5JpBNerNwuIWE0THwIWf_I3lwoivmpJ3JAj3T_XA~&sessionId='
if __name__ == '__main__':
main()
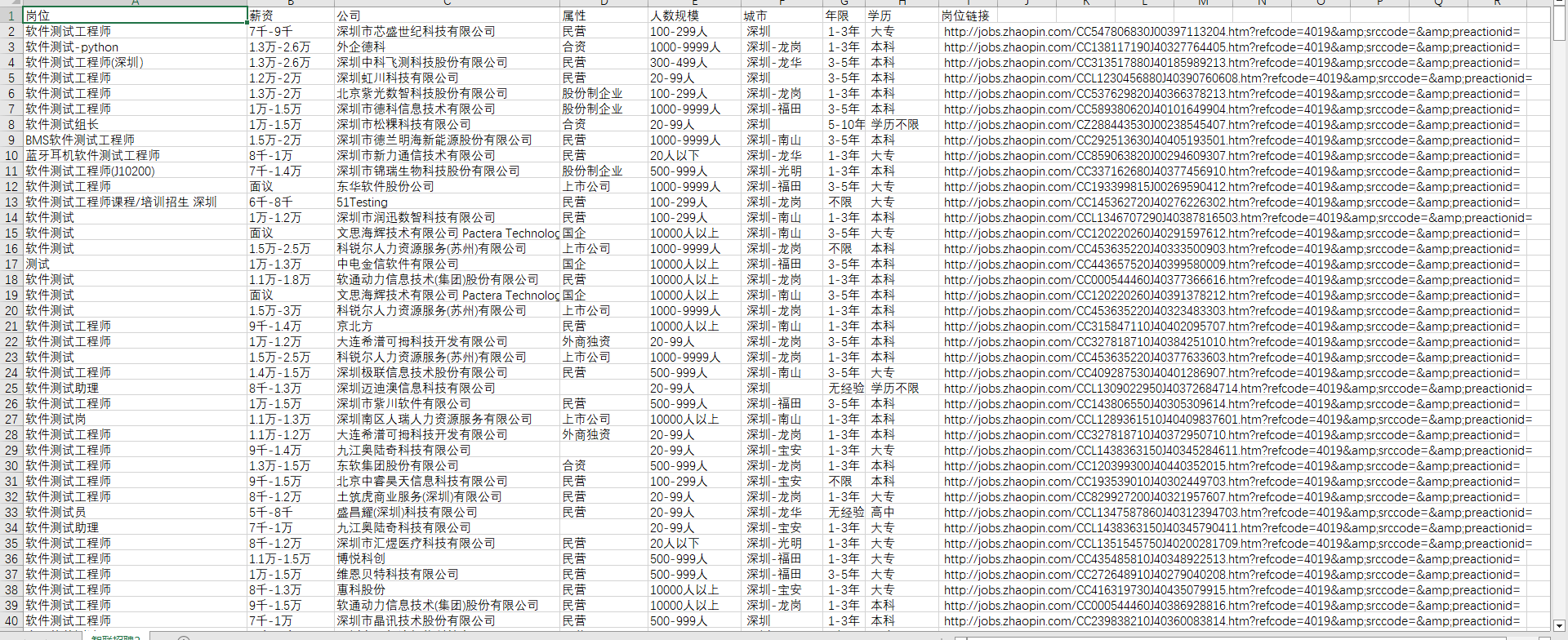
智联招聘
# coding=gbk
# -*- coding:uft-8 -*-
# @Time: 2023/2/15
# @Author: 十架bgm
# @FileName: testzl
import random
import datetime
import requests
import re
import os,sys,io
import csv
import json
from time import sleep
os.environ['NO_PROXY'] = 'https://cc-api.sbaliyun.com/v1/completions'
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码
def get_info(url, f):
for page in range(1, 100):
# for page in range(1, 2):
print(f"正在打印第{page}页")
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'cookie': 'x-zp-client-id=b6b4a694-02ff-4306-be56-ed11ce2baa2b; sts_deviceid=185295afff2b0d-06ad5dc752ae9f-26021151-2073600-185295afff3deb; FSSBBIl1UgzbN7NO=54r0T34xUfl7SO2Wwzz2fW9jfRfagTseIsjpbz5vGSeJ_GQuxMjXHk8921ftnUjFlpfWj3kBwenzwkIVEcR8Gqa; locationInfo_search={%22code%22:%22765%22%2C%22name%22:%22%E6%B7%B1%E5%9C%B3%22%2C%22message%22:%22%E5%8C%B9%E9%85%8D%E5%88%B0%E5%B8%82%E7%BA%A7%E7%BC%96%E7%A0%81%22}; _uab_collina=167566362427234695317277; SHOW_ATTACHMENT_RESUME_TIP=true; x-zp-device-id=de49e8b517bb27928d5be0fc024db43f; at=9a8c3ea443c9444b85b01885c7fb3e7c; rt=c0e0131e58364c2388c3c79fc8523fef; c=Jl8vEW52-1675939020065-0d7c462187b931302178198; _fmdata=2Djl%2BizdMVqq2omJFIu9rgsIkwjvszOzGM9Es7ipvqfBVU%2FWJyKSl4P%2FsZ%2Fj8lHjgpwm%2BxAuR6N%2FafX2wC8SHg%3D%3D; _xid=gakJH2UYkju0RK7GmceGEcicctW8a%2FCtsvlGFQLgilg%3D; ZP_OLD_FLAG=false; selectCity_search=765; Hm_lvt_38ba284938d5eddca645bb5e02a02006=1675663624,1675735581,1675939035,1676286087; IMDate=20230215; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221141887912%22%2C%22first_id%22%3A%22185295aa376d6b-0402bd354e97484-26021151-2073600-185295aa377c5e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg1Mjk1YWEzNzZkNmItMDQwMmJkMzU0ZTk3NDg0LTI2MDIxMTUxLTIwNzM2MDAtMTg1Mjk1YWEzNzdjNWUiLCIkaWRlbnRpdHlfbG9naW5faWQiOiIxMTQxODg3OTEyIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%221141887912%22%7D%2C%22%24device_id%22%3A%22185295aa376d6b-0402bd354e97484-26021151-2073600-185295aa377c5e%22%7D; acw_tc=276077d816764427206611767ebd5203c606dd6111929a887ae5c5d5ad4487; ssxmod_itna=YqAxuDyDgDcGG=G7KDXYr8lxomxD5px65fxIQD/+ixnqD=GFDK40of7+ND7QyNyZxr3KMQmrnUaxaKoO3PNWmbONQDU4i8DCuiP4WDeW=D5xGoDPxDeDADYE6DAqiOD7qDdfhTXtkDbxi3fxDbDim8mxGCDeKD0ZbFDQKDuE9qKjw8PIa+uPOCKW7erAKD9=oDs2DfO97fLUTzPKSADI4ODlKUDCF1uEyFr4Gd66v1D84xEWDPFa4qL7iehiGrNDKdQlxq370cODRD=QGe5hha=qDWQkpDD=; ssxmod_itna2=YqAxuDyDgDcGG=G7KDXYr8lxomxD5px65fxKG9ixsDBMqxDKGaKW/fVCwIoIwSn+yGz4vOAFew/+0AP25VilCFW=6ifi3aLUA2C3bKkErlSy6liKgTd8ltVMvHgrI/zUM85oA5tZcUL5Rt3NlWDPDKdIFD7=DedKxD==; ZL_REPORT_GLOBAL={%22jobs%22:{%22funczoneShare%22:%22dtl_best_for_you%22%2C%22recommandActionidShare%22:%22c2d2dd98-84e9-448f-987e-330d704ae5f7-job%22}}; FSSBBIl1UgzbN7NP=535S5gbH7IXWqqqDDVeIWxawAFA95JoczwV2CbmYcpUSTmBj.lWx6Fw1s_aLX_DscBchpjg7iP06TJDwshIimYQWH38NgCP7OmJPsNYm3HBkaBsu81t72jrbDM4L.PQXj10cfV98tg86..J4CnVQDaxehlmbrcJZU6y8.bGzQgSJyDCFYJd6.gNuZ6ZQWNb4EhD7oF91Bu21_KXU5Kcpl9uthhnKyEa25Um4WoVPkX1Bg_V54n36XOCZWJbbsZC.6T4Sc58euSbu_uG_cRXkSNyLKpRlNpvhkiurpllcNb_fA',
'referer': 'https://www.zhaopin.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
params = {
'jl': '765', # 765是深圳
'kw': '机械设计',
'p': str(page)
}
info = requests.get(url=url, headers=headers, params=params, timeout=10).text
if 'compname__name' not in info:
print(f"已爬取最大页数{page - 1}!!")
break
gangwei = re.findall(r'<div class="iteminfo.*?"><span title="(.*?)" class="iteminfo__line1__jobname__name">', info) # 岗位
salary = re.findall(r'"salary60":"(.*?)"', info) # 薪水
conpanyLs = re.findall(r'compname__name">(.*?)</span>', info) # 公司
rs= re.findall(r'compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>', info) # 规模
yaoqiu = re.findall('demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>', info)
urlLs = re.findall('item clearfix"><a href="(.*?)" target', info)
mLs, guimo = [], []
for m,r in rs:
# print(m, r)
mLs.append(m)
guimo.append(r)
citys, nian_xian, xueli = [], [] , []
for city, nx, xl in yaoqiu:
citys.append(city)
nian_xian.append(nx)
xueli.append(xl)
for g,s,gsi, m,r,ci,nx1,xl1, urlll in zip(gangwei,salary,conpanyLs,mLs, guimo, citys, nian_xian, xueli, urlLs):
print(g,s,gsi,m,r, ci, nx1, xl1, urlll)
f.write(f"{g},{s},{gsi},{m},{r}, {ci}, {nx1}, {xl1}, {urlll}\n")
sleep(random.randint(3, 5))
def main():
today = str(datetime.datetime.today()).split(' ')[0]
with open(f'{today}机械设计.csv', 'a', encoding='ANSI', newline='') as f:
header = ['岗位', '薪资', '公司', '属性', '人数规模', '城市', '年限', '学历', '岗位链接'] # 列头名字
writer = csv.writer(f)
writer.writerow(header) # 设置列头名字
url = 'https://sou.zhaopin.com/?'
get_info(url, f)
print('打印完成!')
if __name__ == '__main__':
main()
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17125015.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号