
75接口采集学习网址信息,顺便清理一个存入csv的坑
对一个学习网址进行外页爬取
# coding=gbk
# -*- coding:uft-8 -*-
# @Time: 2023/2/13
# @Author: 十架bgm
# @FileName: ca213
import csv
import requests
import re
import os
os.environ['NO_PROXY'] = 'https://cc-api.sbaliyun.com/v1/completions'
def one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
res = requests.get(url, headers)
return res.text if res.status_code == 200 else None
def parse_one_page(html):
pattern = re.compile(r'<a.*?>(.*?)</a></p>')
titles = re.findall(pattern, html)
# print(titles)
totals = re.findall(r'picture_list_detail_intro">(.*?)</p>', html)
# print(totals)
teacher = re.findall(r'picture_list_detail_teacher">(.*?)</p>', html)
with open("学习平台.csv", 'a', encoding='ANSI', newline='') as f:
headers = ['课程名', '学习人数', 'teacher']
writer = csv.writer(f)
writer.writerow(headers)
for title, total, te in zip(titles, totals, teacher):
print(f"{title}----{total}----{te}")
f.write(f'{title.replace(",","")}, {total}, {te}\n') # 这里存入csv时候,title里面的逗号默认被分割,要替换中文逗号或者空白
# exit()
def mian(offset):
url = f'https://www.youdongla.com/course/1_{str(offset)}'
html = one_page(url)
parse_one_page(html)
if __name__ == '__main__':
for offset in range(1, 4):
mian(offset)
存入到csv问题:title以","分割了
如图
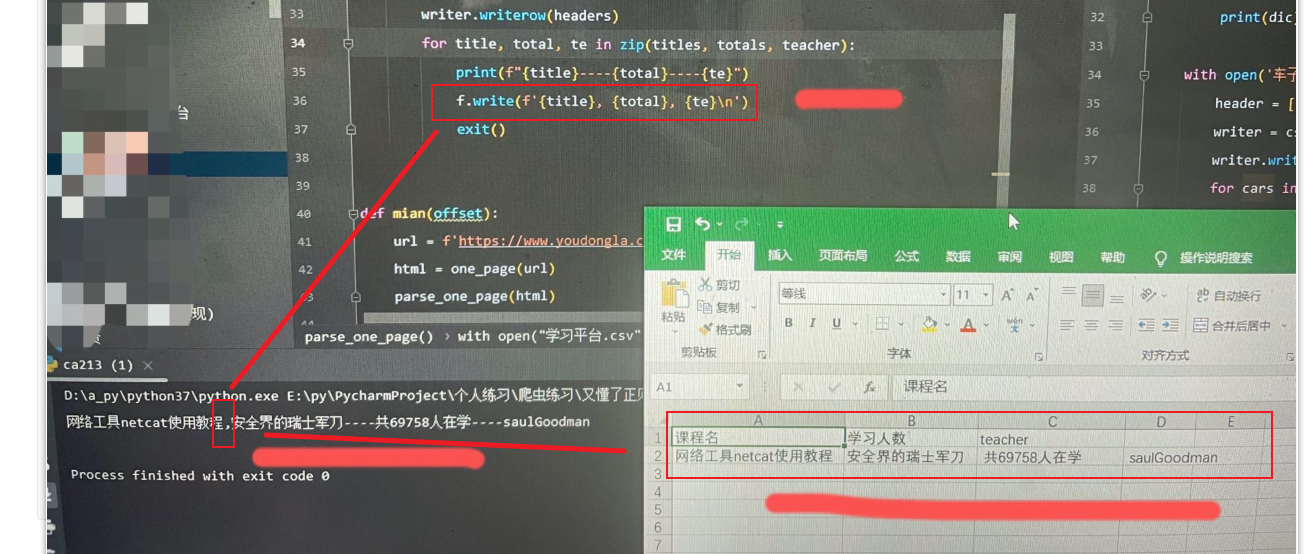
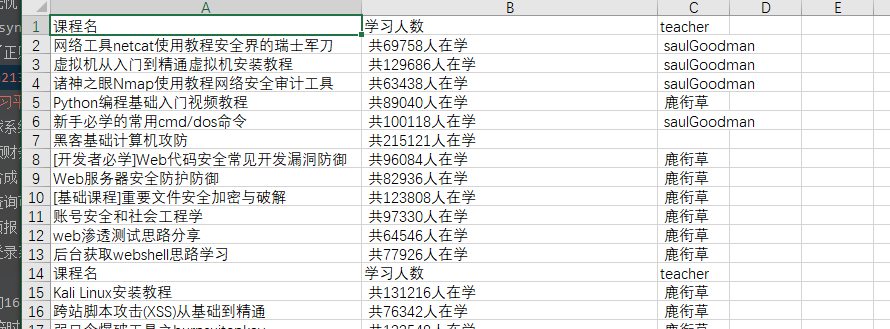
解决方法:
替换一下,我换了空,完美解决
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17116789.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号