
67使用slenium自动化爬取200页职位信息(也可以用playwright)
使用虚拟环境 创建一个 selenium版本>4
因为反爬比较严重 这里没用协议弄 采用selenium
思路:1.先用selenium,获取网页(这里获取外页,内页请求量太大),2.再解析 得到我们想要的结果 -----避免爬一半被反爬了
部分图
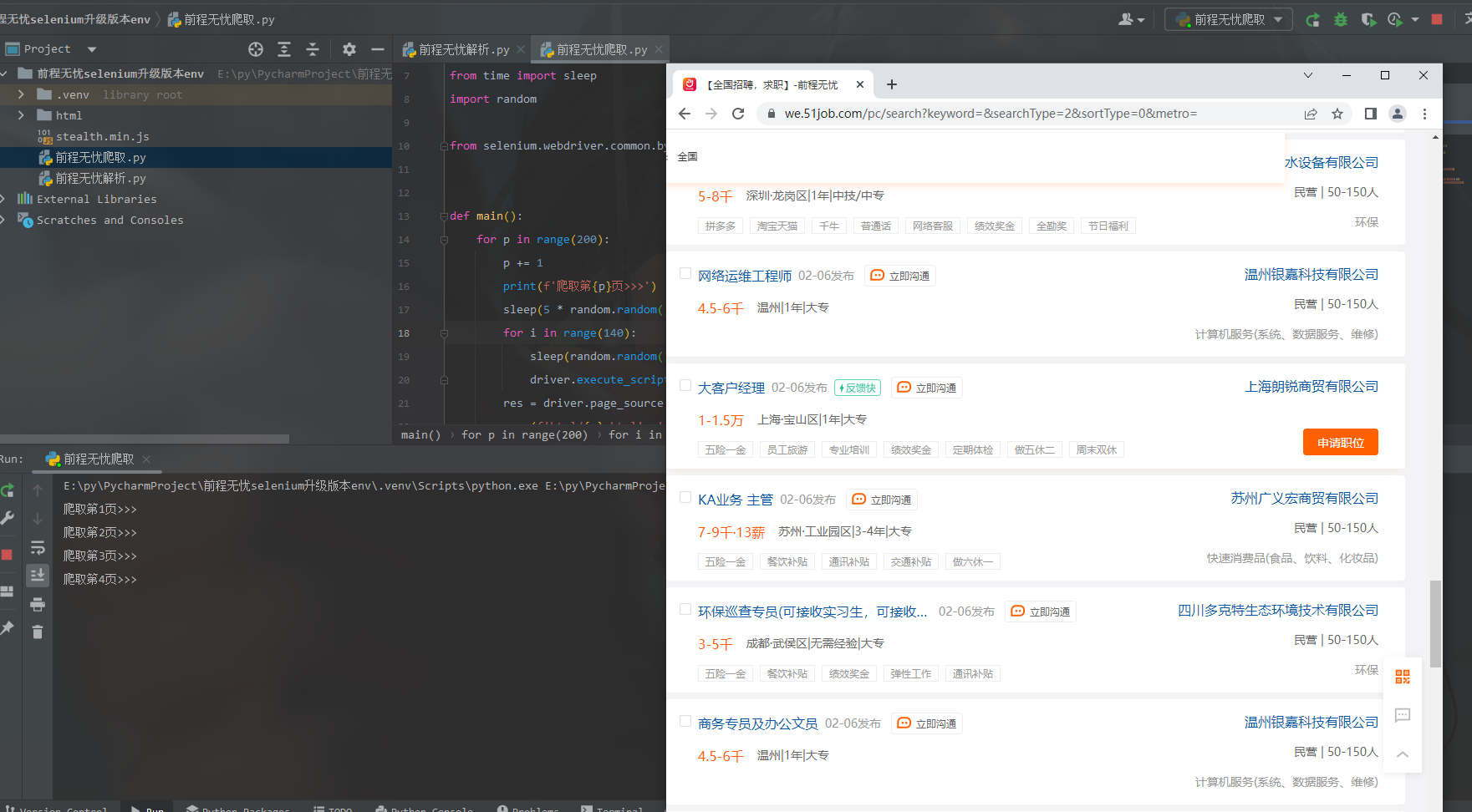
实现代码如下
# 1.获取网页
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from time import sleep
import random
from selenium.webdriver.common.by import By
def main():
for p in range(200):
p += 1
print(f'爬取第{p}页>>>')
sleep(5 * random.random())
for i in range(140):
sleep(random.random() / 5) # 这里睡眠时间随机 避免被误认为机器
driver.execute_script('window.scrollBy(0, 50)') # By向下拉50px 不能一下刷到底,否则中途丢失数据包 # window.scrollTo 是滚到那边
res = driver.page_source # 获取网页
open(f'html/{p}.html', 'w', encoding='utf-8').write(res)
if p != 200:
driver.find_element(By.ID, 'jump_page').clear()
driver.find_element(By.ID, 'jump_page').send_keys(p + 1)
sleep(random.random())
driver.find_element(By.CLASS_NAME, 'jumpPage').click() # 跳转下一页继续获取网页
if __name__ == '__main__':
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options)
js = open('stealth.min.js').read() # # stealth.min.js这个文件是puppeteer中用于抹去自动化程序特征的。当他被单独提取出来后就可以在selenium中加载并使用,使得可以抹掉selenium中的自动化特征,从而绕过一些网站或者验证程序的机器人检测。
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': js})
driver.get('url') # 杭州地区
sleep(5)
main()
driver.quit()
# 解析
from lxml import etree
import pandas as pd
def collect():
resLs = []
for i in range(200):
i += 1
res = open(f'html/{i}.html', encoding='utf-8').read()
tree = etree.HTML(res)
for li in tree.xpath('//div[@class="j_joblist"]/div'):
name = li.xpath('.//span[@class="jname at"]/text()')[0]
href = li.xpath('./a/@href')[0]
time = li.xpath('.//span[@class="time"]/text()')[0]
sala = (li.xpath('.//span[@class="sal"]/text()') + [''])[0]
addr = (li.xpath('.//span[@class="d at"]/span/text()') + [''] * 5)[0] # 有些为空,扩长
exp = (li.xpath('.//span[@class="d at"]/span/text()') + [''] * 5)[2]
edu = (li.xpath('.//span[@class="d at"]/span/text()') + [''] * 5)[4]
comp = li.xpath('.//a[@class="cname at"]/text()')[0]
kind = li.xpath('.//p[@class="dc at"]/text()')[0].split('|')[0].strip()
num = (li.xpath('.//p[@class="dc at"]/text()')[0].split('|') + [''])[1].strip()
ind = (li.xpath('.//p[@class="int at"]/text()') + [''])[0]
dic = {
'标题': name,
'链接': href,
'时间': time,
'薪资': sala,
'地区': addr,
'经验': exp,
'学历': edu,
'公司': comp,
'类型': kind,
'规模': num,
'行业': ind
}
print(dic)
resLs.append(dic)
pd.DataFrame(resLs).to_excel('XXX.xlsx', index=False, encoding='utf-8')
if __name__ == '__main__':
collect()
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17094959.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号