
42爬取数据并保存至db
需求:
将爬取数据保存到数据库
将爬取数据保存为txt文件
将txt文件内容生成为词云
查看爬取到数据库的数据信息
代码如下:
import os.path
import requests
import pymysql
import parsel
import csv #保存csv文件
import imageio
import jieba #引用中文分词库
from wordcloud import WordCloud #引用词云库
#获取网页源代码、解析数据
def get_html():
films = [] #用来存储全部数据
num = 1
for page in range(0, 250, 25):
print(f'正在爬取第{num}页数据内容')
num += 1
url = f"https://movie.douban.com/top250?start={page}&filter="
# user-agent 浏览器基本标识 基本信息 headers请求头 主要把python代码进行伪装
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 2、获取数据
#return response.text
# 3、解析数据
selector = parsel.Selector(response.text)
lis = selector.css('.grid_view li')
for li in lis:
title = li.css('.info .hd span.title:nth-child(1)::text').get() # 电影名
movie_info_list = li.css('.bd p:nth-child(1)::text').getall()
actor_list = movie_info_list[0].strip().split(' ')
if len(actor_list) > 1:
actor_1 = actor_list[0].replace('导演', '').replace(':', '') # 导演
actor_2 = actor_list[1].replace('主演', '').replace('/...', '').replace(':', '').replace("'", "") # 主演
else:
actor_1 = actor_list[0]
actor_2 = 'None'
movie_info = movie_info_list[1].strip().split(' / ') # movie_info_list[1]:取的是拍摄国家,年份和剧情三个信息
movie_year = movie_info[0] # 电影年份
movie_country = movie_info[1] # 拍摄国家
movie_type = movie_info[2] # 电影类型
sum = li.css('.star span:nth-child(4)::text').get().replace('人评价', '')
dit = {"title":title, "actor_1":actor_1, "actor_2":actor_2, "movie_year":movie_year, "movie_country":movie_country, "movie_type":movie_type, "sum":sum}
films.append(dit) #将处理好的一步电影存入列表
return films
#保存到数据库
def save_db():
data = get_html()
# db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='python1', charset='utf8')
db = pymysql.connect(host="xxxxx",port=3306, user="root", password="666", db="pythonTest",charset='utf8')
cursor = db.cursor() # 游标 能获得连接的游标,这个游标可以用来执行SQL查询
for i in range(len(data)):
sql = "insert into movie(title,director,actor,movie_year,movie_country,movie_type,num)values('%s','%s','%s','%s','%s','%s','%s')" % (
data[i]["title"],data[i]["actor_1"],data[i]["actor_2"],data[i]["movie_year"],data[i]["movie_country"],data[i]["movie_type"],
data[i]["sum"])
cursor.execute(sql) # 执行sql语句
db.commit() # 提交至数据库
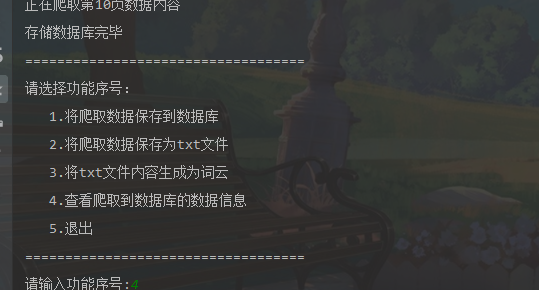
print("存储数据库完毕")
# 关闭光标对象
cursor.close()
# 关闭连接
db.close()
#保存为txt文件
def save_txt():
f = open('豆瓣Top250.txt', mode='w', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=[
'标题',
'导演',
'演员',
'电影年份',
'拍摄国家',
'电影类型',
'评价人数'
])
csv_write.writeheader() # 写入表头
data = get_html()
for i in range(len(data)):
s = str(data[i]).replace('{', '').replace('}', '').replace("'", '').replace(':', '').replace('title','')\
.replace('actor_1','').replace('actor_2','').replace('movie_year','').replace('movie_country','')\
.replace('movie_type','').replace('sum','') + '\n'
f.write(s)
f.close()
print("数据成功存入文件:豆瓣Top250.txt")
#词云
def wordcloud():
mask = imageio.imread("f.png")
if os.path.isfile("豆瓣Top250.txt"):
f = open('豆瓣Top250.txt', 'r', encoding='utf-8') # 打开文件
ls = f.read() # 读文件,并将字符串放到 ls变量中
f.close() # 关闭文件
l = jieba.lcut(ls) # 利用jieba库中 全模式中文分词样式,生成l列表
txt = " ".join(l) # 将列表l 数据间加空格,再赋值给 txt 字符串
wordcloud = WordCloud(background_color="pink",
width=800,
height=600,
max_words=10000,
max_font_size=80,
min_font_size=1,
mask=mask, # 指定词云形状,默认为长方形
# contour_width=1, #轮廓宽度
# contour_color='steelblue', #轮廓颜色
font_path="simkai.ttf",
# scale=5
).generate(txt) # 向WordCloud对象wordcloud中加载文本txt生成词云
wordcloud.to_file('ball1_词云图.png') # 将词云输出为图像文件
print("词云成功生成")
else:
print("文件:豆瓣Top250.txt不存在,可先执行功能序号为2的功能创建txt文件")
#查询数据库
def finddb():
# db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='python1', charset='utf8')
db = pymysql.connect(host="xxxxx",port=3306, user="root", password="666", db="pythonTest",charset='utf8')#存储服务器
cursor = db.cursor()#游标 能获得连接的游标,这个游标可以用来执行SQL查询
#游标是一种数据访问对象,可用于在表中迭代一组行或者向表中插入新行。
sql = "select * from movie"
cursor.execute(sql)#执行sql语句
data = cursor.fetchall()#查询数据库全部数据
if len(data) !=0:
print("豆瓣电影Top250")
print("--------------------------------------------")
for i in data:
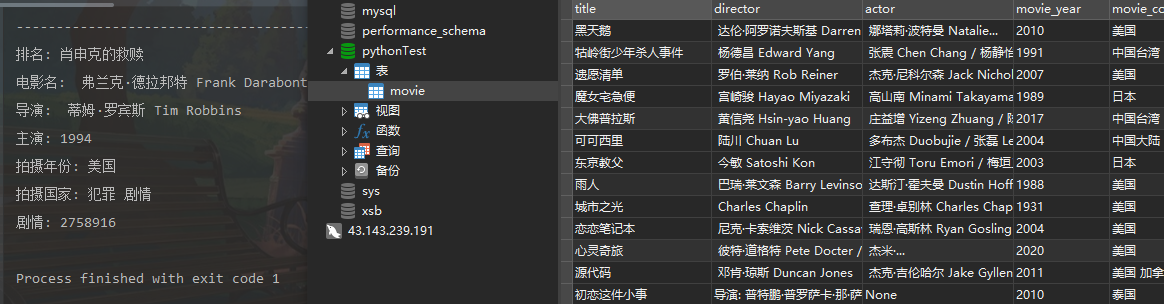
print("排名:", i[0])
print("电影名:", i[1])
print("导演:", i[2])
print("主演:", i[3])
print("拍摄年份:", i[4])
print("拍摄国家:", i[5])
print("剧情:", i[6])
print("评论人数:", i[7])
print("===================================")
else:
print("数据库为空,可先执行功能序号1的功能")
# 关闭光标对象
cursor.close()
# 关闭连接
db.close()
#主函数入口
if __name__ == '__main__':
while True:
print("===================================")
print('请选择功能序号:')
print(" 1.将爬取数据保存到数据库")
print(" 2.将爬取数据保存为txt文件")
print(" 3.将txt文件内容生成为词云")
print(" 4.查看爬取到数据库的数据信息")
print(" 5.退出")
print("===================================")
num = input('请输入功能序号:')
if num == '1':
save_db()
continue
elif num == '2':
save_txt()
continue
elif num == '3':
wordcloud()
elif num == '4':
finddb()
elif num == '5':
exit()
else:
print("序号输入错误,请重新输入")
简要效果图如下:
本文来自博客园,作者:__username,转载请注明原文链接:https://www.cnblogs.com/code3/p/17000312.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号